DeepID: Deep Learning for Face Recognition. Department of Electronic Engineering,
|
|
|
- Clifton Mills
- 5 years ago
- Views:
Transcription
1 DeepID: Deep Learning for Face Recognition Xiaogang Wang Department of Electronic Engineering, The Chinese University i of Hong Kong
2 Machine Learning with Big Data Machine learning with small data: overfitting, reducing model complexity (capacity), adding regularization Machine learning with big data: underfitting, increasing model complexity, g g g, g p y, optimization, computation resource
3 Face Recognition Face verification: binary classification Verify two images belonging to the same person or not? Face identification: multi class classification classify an image into one of N identity classes

4 Labeled Faces in the Wild (2007) Best results without deep learning
5 Learn face representations from face verification, identification, multi view reconstruction Properties of face representations sparseness, selectiveness, robustness Sparsify the network sparseness, selectiveness Applications of face representations face localization, li attribute t recognition
6 Learn face representations from face verification, identification, multi view reconstruction Properties of face representations sparseness, selectiveness, robustness Sparsify the network sparseness, selectiveness Applications of face representations face localization, li attribute t recognition






7 Key challenge on face recognition Intra personal variation Inter personal variation How to separate the two types of variations?
8 Learning feature representations Training stage A Training stage B Dataset A Dataset B feature transform feature transform Fixed Classifier A Linear classifier B The two images Reconstruct Distinguish belonging to the 10,000 faces Task people Ain same person or not (identification) multiple views (verification) The two images belonging Task Bto the same person or not Face verification
9 Learn face representations from Predicting binary labels (verification) Prediction becomes richer Prediction becomes more challenging Supervision becomes stronger Feature learningbecomes more effective Predicting multi class labels (identification) Predicting thousands of real valued pixels (multi view) i reconstruction ti
10 Learn face representations with verification signal Extract relational features with learned filter pairs These relational features are further processed through multiple layers to extract global features The fully connected layer is the feature representation Y. Sun, X. Wang, and X. Tang, Hybrid Deep Learning for Computing Face Similarities, Proc. ICCV, 2013.
11 DeepID: Learn face representations with identification signal (1, 0, 0) (0, 1, 0) (0, 0, 1) Y. Sun, X. Wang, and X. Tang, Deep Learning Face Representation from Predicting 10,000 classes, Proc. CVPR, 2014.
12 DeepID2: Joint Identification (Id) Verification (Ve) Signals (Id) Y. Sun, X. Wang, and X. Tang. NIPS, 2014.
13




14 Learning face representation from recovering canonical view face images Julie Cindy Reconstruction examples from LFW Z. Zhu, P. Luo, X. Wang, and X. Tang, Deep Learning Identity Preserving Face Space, ICCV 2013.
15 Disentangle factors through feature extraction over multiple layers No 3D model; dlno prior information on pose and lighting condition Model multiple complex transforms Reconstructing ti the whole face is a much strong supervision ii than predicting 0/1 class label Arbitrary view Canonical view
16
17 It is still not a 3D representation yet Can we reconstruct all the views?
18 Output Image y 1 (0 o ) y 2 (45 o ) y 3 (90 o ) Hidden Layer n A multi task solution: discretize the view spectrum Input Image 1. The number of views to be reconstructed is predefined, equivalent to the number of tasks 2. Cannot reconstruct views not presented in the training set 3. Encounters problems when the training data of different views are unbalanced 4. Model complexity increases as the number of views
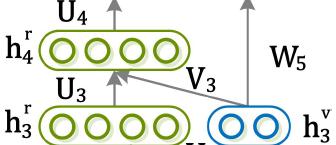
19 Deep learning multi view representation from 2D images Given an image under arbitrary view, its viewpoint can be estimated and its full spectrum of views can be reconstructed Continuous view representation tti Identity and view represented by different sets of neurons Jackie Feynman Feynman Z. Zhu, P. Luo, X. Wang, and X. Tang, Deep Learning and Disentangling Face Representation by Multi View Perception, NIPS 2014.
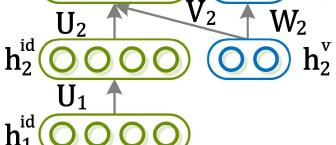
20 Network is composed of deterministic neurons and random neurons x and y are input and output images of the same identity but in different views; vis the view label of the output image; g; h id are neurons encoding identity features es h v are neurons encoding view features h r are neurons encoding features to reconstruct the output images
21 Deep Learning by EM EM updates on the probabilistic model are converted to forward and backward propagation E-step: proposes s samples of h M-step: compute gradient refer to h with largest w s
22 Face recognition accuracies across views and illuminations on the Multi PIE dataset. The first and the second best performances are in bold.
23 Deep Learning Multi view Representation from 2D Images Interpolate and predict images under viewpoints unobserved in the training set The training set only has viewpoints of 0 o, 30 o, and 60 o. (a): the reconstructed images under 15 o and 45 o when the input is taken under 0 o. (b) The input images are under 15 o and 45 o.
24 Generalize to other facial factors Label of View Label of Age y v Output Image Hidden Layer n View Age h id h v Identity View Age Random Neurons Input Image x
25 Face reconstruction across poses and expressions
26 Face reconstruction across lightings and expressions
27 Learn face representations from face verification, identification, multi view reconstruction Properties of face representations sparseness, selectiveness, robustness Sparsify the network sparseness, selectiveness Applications of face representations face attribute recognition, face localization Y. Sun, X. Wang, and X. Tang, CVPR 2015
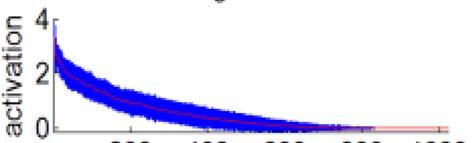
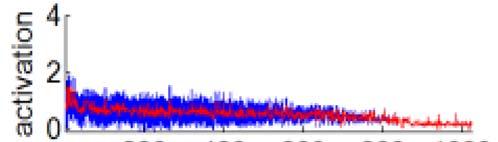
28 Deeply learned features are moderately sparse The binary codes on activation patterns are very effective on face recognition Save storage and speedup face search dramatically Activation patterns are more important than activation magnitudes in face recognition Combined model (real values) Joint Bayesian (%) Hamming distance (%) n/a Combined model (binary code)

29 Deeply learned features are moderately sparse Moderately sparse For an input image, about half of the neurons are activated Highly sparse Maximize the Hamming distance between images 2
30 Deeply learned features are moderately sparse Responses of a particular neuron on all the images An neuron has response on about half of p the images Maximize the discriminative power (entropy) of a neuron on describing the image set





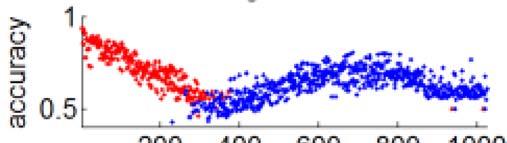
31 Deeply learned features are selective to identities and attributes With a single neuron, DeepID2 reaches 97% recognition accuracy for some identity and attribute
32 Deeply learned features are selective to identities and attributes Excitatory and inhibitory neurons (on identities) Neuron 56 Neuron 78 Neuron 344 Neuron 298 Neuron 157 Neuron 116 Neuron 328 Neuron 459 Neuron 247 Neuron 131 Neuron 487 Neuron 103 Neuron 291 Neuron 199 Neuron 457 Neuron 461 Neuron 473 Neuron 405 Neuron 393 Neuron 445 Neuron 328 Neuron 235 Neuron 98 Neuron 110 Neuron 484 Histograms of neural activations over identities with the most images in LFW
33 Neuron 38 Neuron 50 Neuron 462 Neuron 354 Neuron 418 Neuron 328 Neuron 316 Neuron 496 Neuron 484 Neuron 215 Neuron 5 Neuron 17 Neuron 432 Neuron 444 Neuron 28 Neuron 152 Neuron 105 Neuron 140 Neuron 493 Neuron 237 Neuron 12 Neuron 498 Neuron 342 Neuron 330 Neuron 10 Neuron 61 Neuron 73 Neuron 322 Neuron 410 Neuron 398
34 Deeply learned features are selective to identities and attributes Excitatory and inhibitory neurons (on attributes) Neuron 77 Neuron 361 Neuron 65 Neuron 873 Neuron 117 Neuron 3 Neuron 491 Neuron 63 Neuron 75 Neuron 410 Histograms of neural activations over gender related attributes (Male and Female) Neuron 444 Neuron 448 Neuron 108 Neuron 421 Neuron 490 Neuron 282 Neuron 241 Neuron 444 Histograms of neural activations over race related attributes (White, Black, Asian and India)
35 Neuron 205 Neuron 186 Neuron 249 Neuron 40 Neuron 200 Neuron 61 Neuron 212 Neuron 200 Neuron 106 Neuron 249 Histogram of neural activations over age related attributes (Baby, Child, Youth, Middle Aged, and Senior) Neuron 36 Neuron 163 Neuron 212 Neuron 281 Neuron 122 Neuron 50 Neuron 406 Neuron 96 Neuron 167 Neuron 245 Histogram of neural activations over hair related attributes (Bald, Black Hair, Gray Hair, Blond Hair, and Brown Hair.



36 Deeply learned features are selective to identities and attributes With a single neuron, DeepID2 reaches 97% recognition accuracy for some identity and attribute Identity classification accuracy on LFW with one single DeepID2+ or LBP feature. GB, CP, TB, DR, and GS are five celebrities lbiti with the most images in LFW. Attribute classification accuracy on LFW with one single DeepID2+ or LBP feature.
37 Excitatory and Inhibitory neurons DeepID2+ High dim LBP






38 Excitatory and Inhibitory neurons DeepID2+ High dim LBP





39 Excitatory and Inhibitory neurons DeepID2+ High dim LBP
40 Deeply learned features are selective to identities and attributes Visualize the semantic meaning of each neuron
41 Deeply learned features are selective to identities and attributes Visualize the semantic meaning of each neuron Neurons are ranked by their responses in descending order with respect to test images

42 Deeply learned features are robust to occlusions Global features are more robust to occlusions
43 Learn face representations from face verification, identification, multi view reconstruction Properties of face representations sparseness, selectiveness, robustness Sparsify the network according to neural selectiveness sparseness, selectiveness Applications of face representations face localization, li i attribute recognition ii
44 Attribute 1 Attribute K Yi Sun, Xiaogang Wang, and Xiaoou Tang, Sparsifying Neural Network Connections for Face Recognition, arxiv: , 2015
45 Attribute 1 Attribute K Explore correlations between neurons in different layers
46 Attribute 1 Attribute K Explore correlations between neurons in different layers




47 Alternatively learning weights and net structures 1. Train a dense network from scratch 2. Sparsify the top layer, and re train the net 3. Sparsify the second top layer, and re train the net Conel, JL. The postnatal development of the human cerebral cortex. Cambridge, Mass: Harvard University Press, 1959.
48 Original deep neural network Sparsified ddeep neural network and only keep 1/8 amount of parameters after joint optimization of weights and structures Train the sparsified network from scratch 98.95% 99.3% 98.33% The sparsified network has enough learning capacity, but the original denser network helps it reach a better intialization
49 Learn face representations from face verification, identification, multi view reconstruction Properties of face representations sparseness, selectiveness, robustness Sparsify the network according to neural selectiveness sparseness, selectiveness Applications of face representations face localization, li i attribute recognition ii
50 DeepID2 features for attribute recognition DeepID2 features can be directly used for attribute recognition Use DeeID2 features as initialization (pre trained result), and then fine tune on attribute t recognition Multi task learning face recognition and attribute prediction does not improve performance, because face recognition is a much stronger supervision than attribute prediction Average accuracy on 40attributes on CelebA and LFWA datasets CelebA FaceTracer [1] (HOG+SVM) Training CNN from scratch with attributes Directly use DeepID2 features DeepID2 + fine tuning LFWA





51 Features learned from face recognition can improve face localization? Single face detector Hard to handle largevariety especially on views View 1 View N Multi view detector View labels are given in training; Each detector handles a view Push the idea to extreme? Viewpoints Gender, expression, race, hair style Attributes Neurons have selectiveness on attributes A filter (or a group of filters) functions as a detector of a face attribute When a subset of neurons are activated, they indicate existence of faces with an attribute configuration



52 Attribute configuration 1 Attribute configuration 2 Brow hair Male Big eyes Black hair Smiling Sunglasses The neurons at different layers can form many activation patterns, implying that the whole set of face images can be divided into many subsets based on attribute configurations
53 LNet localizes faces LNet is pre trained with face recognition and fine tuned with attribute prediction By simply pyaveraging g response maps andgood face localization is achieved Z. Liu, P. Luo, X. Wang, and X. Tang, Deep Learning Face Attributes in the Wild, ICCV 2015
54
 Recall rates w.r.t. number of attributes (FPPI = 0.")
55 (a) (b) (a) ROC curves of LNet and state of the art face detectors (b) Recall rates w.r.t. number of attributes (FPPI = 0.1)
56 Attribute selectiveness: neurons serve as detectors Identity selectiveness: neurons serve as trackers L. Wang, W. Ouyang, X. Wang, and H. Lu, Visual Tracking with Fully Convolutional Networks, ICCV 2015.
57 Conclusions Face representation can be learned from the tasks of verification, identification, and multi view reconstruction Deeply pylearned features are moderately sparse, identity and attribute selective, and robust to data corruption The net can be sparsified substantially by alternatively optimizing the weights and structures Because of these properties, the learned face representation are effective for applications beyond face recognition, such as face localization and attribute prediction




58 Collaborators Yi Sun Ziwei Liu Zhenyao Zhu Ping Luo Xiaoou Tang




59 Thank you!
An Introduction to Deep Image Aesthetics
 Seminar in Laboratory of Visual Intelligence and Pattern Analysis (VIPA) An Introduction to Deep Image Aesthetics Yongcheng Jing College of Computer Science and Technology Zhejiang University Zhenchuan
Seminar in Laboratory of Visual Intelligence and Pattern Analysis (VIPA) An Introduction to Deep Image Aesthetics Yongcheng Jing College of Computer Science and Technology Zhejiang University Zhenchuan
Joint Image and Text Representation for Aesthetics Analysis
 Joint Image and Text Representation for Aesthetics Analysis Ye Zhou 1, Xin Lu 2, Junping Zhang 1, James Z. Wang 3 1 Fudan University, China 2 Adobe Systems Inc., USA 3 The Pennsylvania State University,
Joint Image and Text Representation for Aesthetics Analysis Ye Zhou 1, Xin Lu 2, Junping Zhang 1, James Z. Wang 3 1 Fudan University, China 2 Adobe Systems Inc., USA 3 The Pennsylvania State University,
Singer Traits Identification using Deep Neural Network
 Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Predicting Aesthetic Radar Map Using a Hierarchical Multi-task Network
 Predicting Aesthetic Radar Map Using a Hierarchical Multi-task Network Xin Jin 1,2,LeWu 1, Xinghui Zhou 1, Geng Zhao 1, Xiaokun Zhang 1, Xiaodong Li 1, and Shiming Ge 3(B) 1 Department of Cyber Security,
Predicting Aesthetic Radar Map Using a Hierarchical Multi-task Network Xin Jin 1,2,LeWu 1, Xinghui Zhou 1, Geng Zhao 1, Xiaokun Zhang 1, Xiaodong Li 1, and Shiming Ge 3(B) 1 Department of Cyber Security,
Automatic Laughter Detection
 Automatic Laughter Detection Mary Knox Final Project (EECS 94) knoxm@eecs.berkeley.edu December 1, 006 1 Introduction Laughter is a powerful cue in communication. It communicates to listeners the emotional
Automatic Laughter Detection Mary Knox Final Project (EECS 94) knoxm@eecs.berkeley.edu December 1, 006 1 Introduction Laughter is a powerful cue in communication. It communicates to listeners the emotional
CS 1674: Intro to Computer Vision. Face Detection. Prof. Adriana Kovashka University of Pittsburgh November 7, 2016
 CS 1674: Intro to Computer Vision Face Detection Prof. Adriana Kovashka University of Pittsburgh November 7, 2016 Today Window-based generic object detection basic pipeline boosting classifiers face detection
CS 1674: Intro to Computer Vision Face Detection Prof. Adriana Kovashka University of Pittsburgh November 7, 2016 Today Window-based generic object detection basic pipeline boosting classifiers face detection
Deep Aesthetic Quality Assessment with Semantic Information
 1 Deep Aesthetic Quality Assessment with Semantic Information Yueying Kao, Ran He, Kaiqi Huang arxiv:1604.04970v3 [cs.cv] 21 Oct 2016 Abstract Human beings often assess the aesthetic quality of an image
1 Deep Aesthetic Quality Assessment with Semantic Information Yueying Kao, Ran He, Kaiqi Huang arxiv:1604.04970v3 [cs.cv] 21 Oct 2016 Abstract Human beings often assess the aesthetic quality of an image
IMAGE AESTHETIC PREDICTORS BASED ON WEIGHTED CNNS. Oce Print Logic Technologies, Creteil, France
 IMAGE AESTHETIC PREDICTORS BASED ON WEIGHTED CNNS Bin Jin, Maria V. Ortiz Segovia2 and Sabine Su sstrunk EPFL, Lausanne, Switzerland; 2 Oce Print Logic Technologies, Creteil, France ABSTRACT Convolutional
IMAGE AESTHETIC PREDICTORS BASED ON WEIGHTED CNNS Bin Jin, Maria V. Ortiz Segovia2 and Sabine Su sstrunk EPFL, Lausanne, Switzerland; 2 Oce Print Logic Technologies, Creteil, France ABSTRACT Convolutional
Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj
 Bhiksha Raj") Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj 1 Story so far MLPs are universal function approximators Boolean functions, classifiers, and regressions MLPs can be
Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj 1 Story so far MLPs are universal function approximators Boolean functions, classifiers, and regressions MLPs can be
Photo Aesthetics Ranking Network with Attributes and Content Adaptation
 Photo Aesthetics Ranking Network with Attributes and Content Adaptation Shu Kong 1, Xiaohui Shen 2, Zhe Lin 2, Radomir Mech 2, Charless Fowlkes 1 1 UC Irvine {skong2, fowlkes}@ics.uci.edu 2 Adobe Research
Photo Aesthetics Ranking Network with Attributes and Content Adaptation Shu Kong 1, Xiaohui Shen 2, Zhe Lin 2, Radomir Mech 2, Charless Fowlkes 1 1 UC Irvine {skong2, fowlkes}@ics.uci.edu 2 Adobe Research
Free Viewpoint Switching in Multi-view Video Streaming Using. Wyner-Ziv Video Coding
 Free Viewpoint Switching in Multi-view Video Streaming Using Wyner-Ziv Video Coding Xun Guo 1,, Yan Lu 2, Feng Wu 2, Wen Gao 1, 3, Shipeng Li 2 1 School of Computer Sciences, Harbin Institute of Technology,
Free Viewpoint Switching in Multi-view Video Streaming Using Wyner-Ziv Video Coding Xun Guo 1,, Yan Lu 2, Feng Wu 2, Wen Gao 1, 3, Shipeng Li 2 1 School of Computer Sciences, Harbin Institute of Technology,
arxiv: v2 [cs.cv] 27 Jul 2016
![arxiv: v2 [cs.cv] 27 Jul 2016](/thumbs/78/77625577.jpg "arxiv: v2 [cs.cv] 27 Jul 2016") arxiv:1606.01621v2 [cs.cv] 27 Jul 2016 Photo Aesthetics Ranking Network with Attributes and Adaptation Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, Charless Fowlkes UC Irvine Adobe {skong2,fowlkes}@ics.uci.edu
arxiv:1606.01621v2 [cs.cv] 27 Jul 2016 Photo Aesthetics Ranking Network with Attributes and Adaptation Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, Charless Fowlkes UC Irvine Adobe {skong2,fowlkes}@ics.uci.edu
CS229 Project Report Polyphonic Piano Transcription
 CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
Semantic Image Segmentation via Deep Parsing Network
 Semantic Image Segmentation via Deep Parsing Network Ziwei Liu*, Xiaoxiao Li*, Ping Luo, Chen Change Loy, Xiaoou Tang Multimedia Lab, The Chinese University of Hong Kong Problem Problem TV Background Plant
Semantic Image Segmentation via Deep Parsing Network Ziwei Liu*, Xiaoxiao Li*, Ping Luo, Chen Change Loy, Xiaoou Tang Multimedia Lab, The Chinese University of Hong Kong Problem Problem TV Background Plant
Predicting the immediate future with Recurrent Neural Networks: Pre-training and Applications
 Predicting the immediate future with Recurrent Neural Networks: Pre-training and Applications Introduction Brandon Richardson December 16, 2011 Research preformed from the last 5 years has shown that the
Predicting the immediate future with Recurrent Neural Networks: Pre-training and Applications Introduction Brandon Richardson December 16, 2011 Research preformed from the last 5 years has shown that the
Chord Classification of an Audio Signal using Artificial Neural Network
 Chord Classification of an Audio Signal using Artificial Neural Network Ronesh Shrestha Student, Department of Electrical and Electronic Engineering, Kathmandu University, Dhulikhel, Nepal ---------------------------------------------------------------------***---------------------------------------------------------------------
Chord Classification of an Audio Signal using Artificial Neural Network Ronesh Shrestha Student, Department of Electrical and Electronic Engineering, Kathmandu University, Dhulikhel, Nepal ---------------------------------------------------------------------***---------------------------------------------------------------------
Adaptive Distributed Compressed Video Sensing
 Journal of Information Hiding and Multimedia Signal Processing 2014 ISSN 2073-4212 Ubiquitous International Volume 5, Number 1, January 2014 Adaptive Distributed Compressed Video Sensing Xue Zhang 1,3,
Journal of Information Hiding and Multimedia Signal Processing 2014 ISSN 2073-4212 Ubiquitous International Volume 5, Number 1, January 2014 Adaptive Distributed Compressed Video Sensing Xue Zhang 1,3,
CS 1674: Intro to Computer Vision. Intro to Recognition. Prof. Adriana Kovashka University of Pittsburgh October 24, 2016
 CS 1674: Intro to Computer Vision Intro to Recognition Prof. Adriana Kovashka University of Pittsburgh October 24, 2016 Plan for today Examples of visual recognition problems What should we recognize?
CS 1674: Intro to Computer Vision Intro to Recognition Prof. Adriana Kovashka University of Pittsburgh October 24, 2016 Plan for today Examples of visual recognition problems What should we recognize?
LEARNING AUDIO SHEET MUSIC CORRESPONDENCES. Matthias Dorfer Department of Computational Perception
 LEARNING AUDIO SHEET MUSIC CORRESPONDENCES Matthias Dorfer Department of Computational Perception Short Introduction... I am a PhD Candidate in the Department of Computational Perception at Johannes Kepler
LEARNING AUDIO SHEET MUSIC CORRESPONDENCES Matthias Dorfer Department of Computational Perception Short Introduction... I am a PhD Candidate in the Department of Computational Perception at Johannes Kepler
Decision-Maker Preference Modeling in Interactive Multiobjective Optimization
 Decision-Maker Preference Modeling in Interactive Multiobjective Optimization 7th International Conference on Evolutionary Multi-Criterion Optimization Introduction This work presents the results of the
Decision-Maker Preference Modeling in Interactive Multiobjective Optimization 7th International Conference on Evolutionary Multi-Criterion Optimization Introduction This work presents the results of the
Image Steganalysis: Challenges
 Image Steganalysis: Challenges Jiwu Huang,China BUCHAREST 2017 Acknowledgement Members in my team Dr. Weiqi Luo and Dr. Fangjun Huang Sun Yat-sen Univ., China Dr. Bin Li and Dr. Shunquan Tan, Mr. Jishen
Image Steganalysis: Challenges Jiwu Huang,China BUCHAREST 2017 Acknowledgement Members in my team Dr. Weiqi Luo and Dr. Fangjun Huang Sun Yat-sen Univ., China Dr. Bin Li and Dr. Shunquan Tan, Mr. Jishen
Efficient Implementation of Neural Network Deinterlacing
 Efficient Implementation of Neural Network Deinterlacing Guiwon Seo, Hyunsoo Choi and Chulhee Lee Dept. Electrical and Electronic Engineering, Yonsei University 34 Shinchon-dong Seodeamun-gu, Seoul -749,
Efficient Implementation of Neural Network Deinterlacing Guiwon Seo, Hyunsoo Choi and Chulhee Lee Dept. Electrical and Electronic Engineering, Yonsei University 34 Shinchon-dong Seodeamun-gu, Seoul -749,
arxiv: v1 [cs.sd] 5 Apr 2017
![arxiv: v1 [cs.sd] 5 Apr 2017](/thumbs/77/76093321.jpg "arxiv: v1 [cs.sd] 5 Apr 2017") REVISITING THE PROBLEM OF AUDIO-BASED HIT SONG PREDICTION USING CONVOLUTIONAL NEURAL NETWORKS Li-Chia Yang, Szu-Yu Chou, Jen-Yu Liu, Yi-Hsuan Yang, Yi-An Chen Research Center for Information Technology
REVISITING THE PROBLEM OF AUDIO-BASED HIT SONG PREDICTION USING CONVOLUTIONAL NEURAL NETWORKS Li-Chia Yang, Szu-Yu Chou, Jen-Yu Liu, Yi-Hsuan Yang, Yi-An Chen Research Center for Information Technology
Indexing local features. Wed March 30 Prof. Kristen Grauman UT-Austin
 Indexing local features Wed March 30 Prof. Kristen Grauman UT-Austin Matching local features Kristen Grauman Matching local features? Image 1 Image 2 To generate candidate matches, find patches that have
Indexing local features Wed March 30 Prof. Kristen Grauman UT-Austin Matching local features Kristen Grauman Matching local features? Image 1 Image 2 To generate candidate matches, find patches that have
Lecture 9 Source Separation
 10420CS 573100 音樂資訊檢索 Music Information Retrieval Lecture 9 Source Separation Yi-Hsuan Yang Ph.D. http://www.citi.sinica.edu.tw/pages/yang/ yang@citi.sinica.edu.tw Music & Audio Computing Lab, Research
10420CS 573100 音樂資訊檢索 Music Information Retrieval Lecture 9 Source Separation Yi-Hsuan Yang Ph.D. http://www.citi.sinica.edu.tw/pages/yang/ yang@citi.sinica.edu.tw Music & Audio Computing Lab, Research
Automatic Laughter Detection
 Automatic Laughter Detection Mary Knox 1803707 knoxm@eecs.berkeley.edu December 1, 006 Abstract We built a system to automatically detect laughter from acoustic features of audio. To implement the system,
Automatic Laughter Detection Mary Knox 1803707 knoxm@eecs.berkeley.edu December 1, 006 Abstract We built a system to automatically detect laughter from acoustic features of audio. To implement the system,
First Step Towards Enhancing Word Embeddings with Pitch Accents for DNN-based Slot Filling on Recognized Text
 First Step Towards Enhancing Word Embeddings with Pitch Accents for DNN-based Slot Filling on Recognized Text Sabrina Stehwien, Ngoc Thang Vu IMS, University of Stuttgart March 16, 2017 Slot Filling sequential
First Step Towards Enhancing Word Embeddings with Pitch Accents for DNN-based Slot Filling on Recognized Text Sabrina Stehwien, Ngoc Thang Vu IMS, University of Stuttgart March 16, 2017 Slot Filling sequential
The Million Song Dataset
 The Million Song Dataset AUDIO FEATURES The Million Song Dataset There is no data like more data Bob Mercer of IBM (1985). T. Bertin-Mahieux, D.P.W. Ellis, B. Whitman, P. Lamere, The Million Song Dataset,
The Million Song Dataset AUDIO FEATURES The Million Song Dataset There is no data like more data Bob Mercer of IBM (1985). T. Bertin-Mahieux, D.P.W. Ellis, B. Whitman, P. Lamere, The Million Song Dataset,
WYNER-ZIV VIDEO CODING WITH LOW ENCODER COMPLEXITY
 WYNER-ZIV VIDEO CODING WITH LOW ENCODER COMPLEXITY (Invited Paper) Anne Aaron and Bernd Girod Information Systems Laboratory Stanford University, Stanford, CA 94305 {amaaron,bgirod}@stanford.edu Abstract
WYNER-ZIV VIDEO CODING WITH LOW ENCODER COMPLEXITY (Invited Paper) Anne Aaron and Bernd Girod Information Systems Laboratory Stanford University, Stanford, CA 94305 {amaaron,bgirod}@stanford.edu Abstract
Generating Chinese Classical Poems Based on Images
 , March 14-16, 2018, Hong Kong Generating Chinese Classical Poems Based on Images Xiaoyu Wang, Xian Zhong, Lin Li 1 Abstract With the development of the artificial intelligence technology, Chinese classical
, March 14-16, 2018, Hong Kong Generating Chinese Classical Poems Based on Images Xiaoyu Wang, Xian Zhong, Lin Li 1 Abstract With the development of the artificial intelligence technology, Chinese classical
gresearch Focus Cognitive Sciences
 Learning about Music Cognition by Asking MIR Questions Sebastian Stober August 12, 2016 CogMIR, New York City sstober@uni-potsdam.de http://www.uni-potsdam.de/mlcog/ MLC g Machine Learning in Cognitive
Learning about Music Cognition by Asking MIR Questions Sebastian Stober August 12, 2016 CogMIR, New York City sstober@uni-potsdam.de http://www.uni-potsdam.de/mlcog/ MLC g Machine Learning in Cognitive
GENDER IDENTIFICATION AND AGE ESTIMATION OF USERS BASED ON MUSIC METADATA
 GENDER IDENTIFICATION AND AGE ESTIMATION OF USERS BASED ON MUSIC METADATA Ming-Ju Wu Computer Science Department National Tsing Hua University Hsinchu, Taiwan brian.wu@mirlab.org Jyh-Shing Roger Jang Computer
GENDER IDENTIFICATION AND AGE ESTIMATION OF USERS BASED ON MUSIC METADATA Ming-Ju Wu Computer Science Department National Tsing Hua University Hsinchu, Taiwan brian.wu@mirlab.org Jyh-Shing Roger Jang Computer
MUSI-6201 Computational Music Analysis
 MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
SentiMozart: Music Generation based on Emotions
 SentiMozart: Music Generation based on Emotions Rishi Madhok 1,, Shivali Goel 2, and Shweta Garg 1, 1 Department of Computer Science and Engineering, Delhi Technological University, New Delhi, India 2
SentiMozart: Music Generation based on Emotions Rishi Madhok 1,, Shivali Goel 2, and Shweta Garg 1, 1 Department of Computer Science and Engineering, Delhi Technological University, New Delhi, India 2
Noise (Music) Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017
 Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017") Noise (Music) Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017 Background Abstract I attempted a solution at using machine learning to compose music given a large corpus
Noise (Music) Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017 Background Abstract I attempted a solution at using machine learning to compose music given a large corpus
Detecting Musical Key with Supervised Learning
 Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
A Discriminative Approach to Topic-based Citation Recommendation
 A Discriminative Approach to Topic-based Citation Recommendation Jie Tang and Jing Zhang Department of Computer Science and Technology, Tsinghua University, Beijing, 100084. China jietang@tsinghua.edu.cn,zhangjing@keg.cs.tsinghua.edu.cn
A Discriminative Approach to Topic-based Citation Recommendation Jie Tang and Jing Zhang Department of Computer Science and Technology, Tsinghua University, Beijing, 100084. China jietang@tsinghua.edu.cn,zhangjing@keg.cs.tsinghua.edu.cn
Using Variational Autoencoders to Learn Variations in Data
 Using Variational Autoencoders to Learn Variations in Data By Dr. Ethan M. Rudd and Cody Wild Often, we would like to be able to model probability distributions of high-dimensional data points that represent
Using Variational Autoencoders to Learn Variations in Data By Dr. Ethan M. Rudd and Cody Wild Often, we would like to be able to model probability distributions of high-dimensional data points that represent
Story Tracking in Video News Broadcasts. Ph.D. Dissertation Jedrzej Miadowicz June 4, 2004
 Story Tracking in Video News Broadcasts Ph.D. Dissertation Jedrzej Miadowicz June 4, 2004 Acknowledgements Motivation Modern world is awash in information Coming from multiple sources Around the clock
Story Tracking in Video News Broadcasts Ph.D. Dissertation Jedrzej Miadowicz June 4, 2004 Acknowledgements Motivation Modern world is awash in information Coming from multiple sources Around the clock
Problem. Objective. Presentation Preview. Prior Work in Use of Color Segmentation. Prior Work in Face Detection & Recognition
 Problem Facing the Truth: Using Color to Improve Facial Feature Extraction Problem: Failed Feature Extraction in OKAO Tracking generally works on Caucasians, but sometimes features are mislabeled or altogether
Problem Facing the Truth: Using Color to Improve Facial Feature Extraction Problem: Failed Feature Extraction in OKAO Tracking generally works on Caucasians, but sometimes features are mislabeled or altogether
Learning Joint Statistical Models for Audio-Visual Fusion and Segregation
 Learning Joint Statistical Models for Audio-Visual Fusion and Segregation John W. Fisher 111* Massachusetts Institute of Technology fisher@ai.mit.edu William T. Freeman Mitsubishi Electric Research Laboratory
Learning Joint Statistical Models for Audio-Visual Fusion and Segregation John W. Fisher 111* Massachusetts Institute of Technology fisher@ai.mit.edu William T. Freeman Mitsubishi Electric Research Laboratory
Advanced Video Processing for Future Multimedia Communication Systems
 Advanced Video Processing for Future Multimedia Communication Systems André Kaup Friedrich-Alexander University Erlangen-Nürnberg Future Multimedia Communication Systems Trend in video to make communication
Advanced Video Processing for Future Multimedia Communication Systems André Kaup Friedrich-Alexander University Erlangen-Nürnberg Future Multimedia Communication Systems Trend in video to make communication
International Journal for Research in Applied Science & Engineering Technology (IJRASET) Motion Compensation Techniques Adopted In HEVC
 Motion Compensation Techniques Adopted In HEVC") Motion Compensation Techniques Adopted In HEVC S.Mahesh 1, K.Balavani 2 M.Tech student in Bapatla Engineering College, Bapatla, Andahra Pradesh Assistant professor in Bapatla Engineering College, Bapatla,
Motion Compensation Techniques Adopted In HEVC S.Mahesh 1, K.Balavani 2 M.Tech student in Bapatla Engineering College, Bapatla, Andahra Pradesh Assistant professor in Bapatla Engineering College, Bapatla,
Experiments on musical instrument separation using multiplecause
 Experiments on musical instrument separation using multiplecause models J Klingseisen and M D Plumbley* Department of Electronic Engineering King's College London * - Corresponding Author - mark.plumbley@kcl.ac.uk
Experiments on musical instrument separation using multiplecause models J Klingseisen and M D Plumbley* Department of Electronic Engineering King's College London * - Corresponding Author - mark.plumbley@kcl.ac.uk
Chapter 2 Introduction to
 Chapter 2 Introduction to H.264/AVC H.264/AVC [1] is the newest video coding standard of the ITU-T Video Coding Experts Group (VCEG) and the ISO/IEC Moving Picture Experts Group (MPEG). The main improvements
Chapter 2 Introduction to H.264/AVC H.264/AVC [1] is the newest video coding standard of the ITU-T Video Coding Experts Group (VCEG) and the ISO/IEC Moving Picture Experts Group (MPEG). The main improvements
Identifying Table Tennis Balls From Real Match Scenes Using Image Processing And Artificial Intelligence Techniques
 Identifying Table Tennis Balls From Real Match Scenes Using Image Processing And Artificial Intelligence Techniques K. C. P. Wong Department of Communication and Systems Open University Milton Keynes,
Identifying Table Tennis Balls From Real Match Scenes Using Image Processing And Artificial Intelligence Techniques K. C. P. Wong Department of Communication and Systems Open University Milton Keynes,
Automatic Piano Music Transcription
 Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Finding Sarcasm in Reddit Postings: A Deep Learning Approach
 Finding Sarcasm in Reddit Postings: A Deep Learning Approach Nick Guo, Ruchir Shah {nickguo, ruchirfs}@stanford.edu Abstract We use the recently published Self-Annotated Reddit Corpus (SARC) with a recurrent
Finding Sarcasm in Reddit Postings: A Deep Learning Approach Nick Guo, Ruchir Shah {nickguo, ruchirfs}@stanford.edu Abstract We use the recently published Self-Annotated Reddit Corpus (SARC) with a recurrent
A CLASSIFICATION-BASED POLYPHONIC PIANO TRANSCRIPTION APPROACH USING LEARNED FEATURE REPRESENTATIONS
 12th International Society for Music Information Retrieval Conference (ISMIR 2011) A CLASSIFICATION-BASED POLYPHONIC PIANO TRANSCRIPTION APPROACH USING LEARNED FEATURE REPRESENTATIONS Juhan Nam Stanford
12th International Society for Music Information Retrieval Conference (ISMIR 2011) A CLASSIFICATION-BASED POLYPHONIC PIANO TRANSCRIPTION APPROACH USING LEARNED FEATURE REPRESENTATIONS Juhan Nam Stanford
Impact of scan conversion methods on the performance of scalable. video coding. E. Dubois, N. Baaziz and M. Matta. INRS-Telecommunications
 Impact of scan conversion methods on the performance of scalable video coding E. Dubois, N. Baaziz and M. Matta INRS-Telecommunications 16 Place du Commerce, Verdun, Quebec, Canada H3E 1H6 ABSTRACT The
Impact of scan conversion methods on the performance of scalable video coding E. Dubois, N. Baaziz and M. Matta INRS-Telecommunications 16 Place du Commerce, Verdun, Quebec, Canada H3E 1H6 ABSTRACT The
Neural Network for Music Instrument Identi cation
 Neural Network for Music Instrument Identi cation Zhiwen Zhang(MSE), Hanze Tu(CCRMA), Yuan Li(CCRMA) SUN ID: zhiwen, hanze, yuanli92 Abstract - In the context of music, instrument identi cation would contribute
Neural Network for Music Instrument Identi cation Zhiwen Zhang(MSE), Hanze Tu(CCRMA), Yuan Li(CCRMA) SUN ID: zhiwen, hanze, yuanli92 Abstract - In the context of music, instrument identi cation would contribute
Discriminative and Generative Models for Image-Language Understanding. Svetlana Lazebnik
 Discriminative and Generative Models for Image-Language Understanding Svetlana Lazebnik Image-language understanding Robot, take the pan off the stove! Discriminative image-language tasks Image-sentence
Discriminative and Generative Models for Image-Language Understanding Svetlana Lazebnik Image-language understanding Robot, take the pan off the stove! Discriminative image-language tasks Image-sentence
Improving Frame Based Automatic Laughter Detection
 Improving Frame Based Automatic Laughter Detection Mary Knox EE225D Class Project knoxm@eecs.berkeley.edu December 13, 2007 Abstract Laughter recognition is an underexplored area of research. My goal for
Improving Frame Based Automatic Laughter Detection Mary Knox EE225D Class Project knoxm@eecs.berkeley.edu December 13, 2007 Abstract Laughter recognition is an underexplored area of research. My goal for
An AI Approach to Automatic Natural Music Transcription
 An AI Approach to Automatic Natural Music Transcription Michael Bereket Stanford University Stanford, CA mbereket@stanford.edu Karey Shi Stanford Univeristy Stanford, CA kareyshi@stanford.edu Abstract
An AI Approach to Automatic Natural Music Transcription Michael Bereket Stanford University Stanford, CA mbereket@stanford.edu Karey Shi Stanford Univeristy Stanford, CA kareyshi@stanford.edu Abstract
Music Composition with RNN
 Music Composition with RNN Jason Wang Department of Statistics Stanford University zwang01@stanford.edu Abstract Music composition is an interesting problem that tests the creativity capacities of artificial
Music Composition with RNN Jason Wang Department of Statistics Stanford University zwang01@stanford.edu Abstract Music composition is an interesting problem that tests the creativity capacities of artificial
Enabling editors through machine learning
 Meta Follow Meta is an AI company that provides academics & innovation-driven companies with powerful views of t Dec 9, 2016 9 min read Enabling editors through machine learning Examining the data science
Meta Follow Meta is an AI company that provides academics & innovation-driven companies with powerful views of t Dec 9, 2016 9 min read Enabling editors through machine learning Examining the data science
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes
 Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
IEEE Santa Clara ComSoc/CAS Weekend Workshop Event-based analog sensing
 IEEE Santa Clara ComSoc/CAS Weekend Workshop Event-based analog sensing Theodore Yu theodore.yu@ti.com Texas Instruments Kilby Labs, Silicon Valley Labs September 29, 2012 1 Living in an analog world The
IEEE Santa Clara ComSoc/CAS Weekend Workshop Event-based analog sensing Theodore Yu theodore.yu@ti.com Texas Instruments Kilby Labs, Silicon Valley Labs September 29, 2012 1 Living in an analog world The
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng
 Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the
Noise Flooding for Detecting Audio Adversarial Examples Against Automatic Speech Recognition
 Noise Flooding for Detecting Audio Adversarial Examples Against Automatic Speech Recognition Krishan Rajaratnam The College University of Chicago Chicago, USA krajaratnam@uchicago.edu Jugal Kalita Department
Noise Flooding for Detecting Audio Adversarial Examples Against Automatic Speech Recognition Krishan Rajaratnam The College University of Chicago Chicago, USA krajaratnam@uchicago.edu Jugal Kalita Department
CS 7643: Deep Learning
 CS 7643: Deep Learning Topics: Stride, padding Pooling layers Fully-connected layers as convolutions Backprop in conv layers Dhruv Batra Georgia Tech Invited Talks Sumit Chopra on CNNs for Pixel Labeling
CS 7643: Deep Learning Topics: Stride, padding Pooling layers Fully-connected layers as convolutions Backprop in conv layers Dhruv Batra Georgia Tech Invited Talks Sumit Chopra on CNNs for Pixel Labeling
Automatic Musical Pattern Feature Extraction Using Convolutional Neural Network
 Automatic Musical Pattern Feature Extraction Using Convolutional Neural Network Tom LH. Li, Antoni B. Chan and Andy HW. Chun Abstract Music genre classification has been a challenging yet promising task
Automatic Musical Pattern Feature Extraction Using Convolutional Neural Network Tom LH. Li, Antoni B. Chan and Andy HW. Chun Abstract Music genre classification has been a challenging yet promising task
Robust 3-D Video System Based on Modified Prediction Coding and Adaptive Selection Mode Error Concealment Algorithm
 International Journal of Signal Processing Systems Vol. 2, No. 2, December 2014 Robust 3-D Video System Based on Modified Prediction Coding and Adaptive Selection Mode Error Concealment Algorithm Walid
International Journal of Signal Processing Systems Vol. 2, No. 2, December 2014 Robust 3-D Video System Based on Modified Prediction Coding and Adaptive Selection Mode Error Concealment Algorithm Walid
Topics in Computer Music Instrument Identification. Ioanna Karydi
 Topics in Computer Music Instrument Identification Ioanna Karydi Presentation overview What is instrument identification? Sound attributes & Timbre Human performance The ideal algorithm Selected approaches
Topics in Computer Music Instrument Identification Ioanna Karydi Presentation overview What is instrument identification? Sound attributes & Timbre Human performance The ideal algorithm Selected approaches
Representations of Sound in Deep Learning of Audio Features from Music
 Representations of Sound in Deep Learning of Audio Features from Music Sergey Shuvaev, Hamza Giaffar, and Alexei A. Koulakov Cold Spring Harbor Laboratory, Cold Spring Harbor, NY Abstract The work of a
Representations of Sound in Deep Learning of Audio Features from Music Sergey Shuvaev, Hamza Giaffar, and Alexei A. Koulakov Cold Spring Harbor Laboratory, Cold Spring Harbor, NY Abstract The work of a
A Study of Predict Sales Based on Random Forest Classification
 , pp.25-34 http://dx.doi.org/10.14257/ijunesst.2017.10.7.03 A Study of Predict Sales Based on Random Forest Classification Hyeon-Kyung Lee 1, Hong-Jae Lee 2, Jaewon Park 3, Jaehyun Choi 4 and Jong-Bae
, pp.25-34 http://dx.doi.org/10.14257/ijunesst.2017.10.7.03 A Study of Predict Sales Based on Random Forest Classification Hyeon-Kyung Lee 1, Hong-Jae Lee 2, Jaewon Park 3, Jaehyun Choi 4 and Jong-Bae
Structured training for large-vocabulary chord recognition. Brian McFee* & Juan Pablo Bello
 Structured training for large-vocabulary chord recognition Brian McFee* & Juan Pablo Bello Small chord vocabularies Typically a supervised learning problem N C:maj C:min C#:maj C#:min D:maj D:min......
Structured training for large-vocabulary chord recognition Brian McFee* & Juan Pablo Bello Small chord vocabularies Typically a supervised learning problem N C:maj C:min C#:maj C#:min D:maj D:min......
AN IMPROVED ERROR CONCEALMENT STRATEGY DRIVEN BY SCENE MOTION PROPERTIES FOR H.264/AVC DECODERS
 AN IMPROVED ERROR CONCEALMENT STRATEGY DRIVEN BY SCENE MOTION PROPERTIES FOR H.264/AVC DECODERS Susanna Spinsante, Ennio Gambi, Franco Chiaraluce Dipartimento di Elettronica, Intelligenza artificiale e
AN IMPROVED ERROR CONCEALMENT STRATEGY DRIVEN BY SCENE MOTION PROPERTIES FOR H.264/AVC DECODERS Susanna Spinsante, Ennio Gambi, Franco Chiaraluce Dipartimento di Elettronica, Intelligenza artificiale e
EyeFace SDK v Technical Sheet
 EyeFace SDK v4.5.0 Technical Sheet Copyright 2015, All rights reserved. All attempts have been made to make the information in this document complete and accurate. Eyedea Recognition, Ltd. is not responsible
EyeFace SDK v4.5.0 Technical Sheet Copyright 2015, All rights reserved. All attempts have been made to make the information in this document complete and accurate. Eyedea Recognition, Ltd. is not responsible
IDENTIFYING TABLE TENNIS BALLS FROM REAL MATCH SCENES USING IMAGE PROCESSING AND ARTIFICIAL INTELLIGENCE TECHNIQUES
 IDENTIFYING TABLE TENNIS BALLS FROM REAL MATCH SCENES USING IMAGE PROCESSING AND ARTIFICIAL INTELLIGENCE TECHNIQUES Dr. K. C. P. WONG Department of Communication and Systems Open University, Walton Hall
IDENTIFYING TABLE TENNIS BALLS FROM REAL MATCH SCENES USING IMAGE PROCESSING AND ARTIFICIAL INTELLIGENCE TECHNIQUES Dr. K. C. P. WONG Department of Communication and Systems Open University, Walton Hall
Music Similarity and Cover Song Identification: The Case of Jazz
 Music Similarity and Cover Song Identification: The Case of Jazz Simon Dixon and Peter Foster s.e.dixon@qmul.ac.uk Centre for Digital Music School of Electronic Engineering and Computer Science Queen Mary
Music Similarity and Cover Song Identification: The Case of Jazz Simon Dixon and Peter Foster s.e.dixon@qmul.ac.uk Centre for Digital Music School of Electronic Engineering and Computer Science Queen Mary
Rebroadcast Attacks: Defenses, Reattacks, and Redefenses
 Rebroadcast Attacks: Defenses, Reattacks, and Redefenses Wei Fan, Shruti Agarwal, and Hany Farid Computer Science Dartmouth College Hanover, NH 35 Email: {wei.fan, shruti.agarwal.gr, hany.farid}@dartmouth.edu
Rebroadcast Attacks: Defenses, Reattacks, and Redefenses Wei Fan, Shruti Agarwal, and Hany Farid Computer Science Dartmouth College Hanover, NH 35 Email: {wei.fan, shruti.agarwal.gr, hany.farid}@dartmouth.edu
Music Genre Classification and Variance Comparison on Number of Genres
 Music Genre Classification and Variance Comparison on Number of Genres Miguel Francisco, miguelf@stanford.edu Dong Myung Kim, dmk8265@stanford.edu 1 Abstract In this project we apply machine learning techniques
Music Genre Classification and Variance Comparison on Number of Genres Miguel Francisco, miguelf@stanford.edu Dong Myung Kim, dmk8265@stanford.edu 1 Abstract In this project we apply machine learning techniques
Reducing False Positives in Video Shot Detection
 Reducing False Positives in Video Shot Detection Nithya Manickam Computer Science & Engineering Department Indian Institute of Technology, Bombay Powai, India - 400076 mnitya@cse.iitb.ac.in Sharat Chandran
Reducing False Positives in Video Shot Detection Nithya Manickam Computer Science & Engineering Department Indian Institute of Technology, Bombay Powai, India - 400076 mnitya@cse.iitb.ac.in Sharat Chandran
arxiv: v1 [cs.lg] 15 Jun 2016
![arxiv: v1 [cs.lg] 15 Jun 2016](/thumbs/79/79195906.jpg "arxiv: v1 [cs.lg] 15 Jun 2016") Deep Learning for Music arxiv:1606.04930v1 [cs.lg] 15 Jun 2016 Allen Huang Department of Management Science and Engineering Stanford University allenh@cs.stanford.edu Abstract Raymond Wu Department of
Deep Learning for Music arxiv:1606.04930v1 [cs.lg] 15 Jun 2016 Allen Huang Department of Management Science and Engineering Stanford University allenh@cs.stanford.edu Abstract Raymond Wu Department of
FOIL it! Find One mismatch between Image and Language caption
 FOIL it! Find One mismatch between Image and Language caption ACL, Vancouver, 31st July, 2017 Ravi Shekhar, Sandro Pezzelle, Yauhen Klimovich, Aurelie Herbelot, Moin Nabi, Enver Sangineto, Raffaella Bernardi
FOIL it! Find One mismatch between Image and Language caption ACL, Vancouver, 31st July, 2017 Ravi Shekhar, Sandro Pezzelle, Yauhen Klimovich, Aurelie Herbelot, Moin Nabi, Enver Sangineto, Raffaella Bernardi
Research Article. ISSN (Print) *Corresponding author Shireen Fathima
 *Corresponding author Shireen Fathima") Scholars Journal of Engineering and Technology (SJET) Sch. J. Eng. Tech., 2014; 2(4C):613-620 Scholars Academic and Scientific Publisher (An International Publisher for Academic and Scientific Resources)
Scholars Journal of Engineering and Technology (SJET) Sch. J. Eng. Tech., 2014; 2(4C):613-620 Scholars Academic and Scientific Publisher (An International Publisher for Academic and Scientific Resources)
MindMouse. This project is written in C++ and uses the following Libraries: LibSvm, kissfft, BOOST File System, and Emotiv Research Edition SDK.
 Andrew Robbins MindMouse Project Description: MindMouse is an application that interfaces the user s mind with the computer s mouse functionality. The hardware that is required for MindMouse is the Emotiv
Andrew Robbins MindMouse Project Description: MindMouse is an application that interfaces the user s mind with the computer s mouse functionality. The hardware that is required for MindMouse is the Emotiv
arxiv: v1 [cs.sd] 18 Oct 2017
![arxiv: v1 [cs.sd] 18 Oct 2017](/thumbs/71/65997419.jpg "arxiv: v1 [cs.sd] 18 Oct 2017") REPRESENTATION LEARNING OF MUSIC USING ARTIST LABELS Jiyoung Park 1, Jongpil Lee 1, Jangyeon Park 2, Jung-Woo Ha 2, Juhan Nam 1 1 Graduate School of Culture Technology, KAIST, 2 NAVER corp., Seongnam,
REPRESENTATION LEARNING OF MUSIC USING ARTIST LABELS Jiyoung Park 1, Jongpil Lee 1, Jangyeon Park 2, Jung-Woo Ha 2, Juhan Nam 1 1 Graduate School of Culture Technology, KAIST, 2 NAVER corp., Seongnam,
Speech To Song Classification
 Speech To Song Classification Emily Graber Center for Computer Research in Music and Acoustics, Department of Music, Stanford University Abstract The speech to song illusion is a perceptual phenomenon
Speech To Song Classification Emily Graber Center for Computer Research in Music and Acoustics, Department of Music, Stanford University Abstract The speech to song illusion is a perceptual phenomenon
Detecting the Moment of Snap in Real-World Football Videos
 Detecting the Moment of Snap in Real-World Football Videos Behrooz Mahasseni and Sheng Chen and Alan Fern and Sinisa Todorovic School of Electrical Engineering and Computer Science Oregon State University
Detecting the Moment of Snap in Real-World Football Videos Behrooz Mahasseni and Sheng Chen and Alan Fern and Sinisa Todorovic School of Electrical Engineering and Computer Science Oregon State University
A Survey of Audio-Based Music Classification and Annotation
 A Survey of Audio-Based Music Classification and Annotation Zhouyu Fu, Guojun Lu, Kai Ming Ting, and Dengsheng Zhang IEEE Trans. on Multimedia, vol. 13, no. 2, April 2011 presenter: Yin-Tzu Lin ( 阿孜孜 ^.^)
A Survey of Audio-Based Music Classification and Annotation Zhouyu Fu, Guojun Lu, Kai Ming Ting, and Dengsheng Zhang IEEE Trans. on Multimedia, vol. 13, no. 2, April 2011 presenter: Yin-Tzu Lin ( 阿孜孜 ^.^)
Release Year Prediction for Songs
 Release Year Prediction for Songs [CSE 258 Assignment 2] Ruyu Tan University of California San Diego PID: A53099216 rut003@ucsd.edu Jiaying Liu University of California San Diego PID: A53107720 jil672@ucsd.edu
Release Year Prediction for Songs [CSE 258 Assignment 2] Ruyu Tan University of California San Diego PID: A53099216 rut003@ucsd.edu Jiaying Liu University of California San Diego PID: A53107720 jil672@ucsd.edu
Supplementary material for Inverting Visual Representations with Convolutional Networks
 Supplementary material for Inverting Visual Representations with Convolutional Networks Alexey Dosovitskiy Thomas Brox University of Freiburg Freiburg im Breisgau, Germany {dosovits,brox}@cs.uni-freiburg.de
Supplementary material for Inverting Visual Representations with Convolutional Networks Alexey Dosovitskiy Thomas Brox University of Freiburg Freiburg im Breisgau, Germany {dosovits,brox}@cs.uni-freiburg.de
Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn
 Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn Introduction Active neurons communicate by action potential firing (spikes), accompanied
Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn Introduction Active neurons communicate by action potential firing (spikes), accompanied
WITH the rapid development of high-fidelity video services
 896 IEEE SIGNAL PROCESSING LETTERS, VOL. 22, NO. 7, JULY 2015 An Efficient Frame-Content Based Intra Frame Rate Control for High Efficiency Video Coding Miaohui Wang, Student Member, IEEE, KingNgiNgan,
896 IEEE SIGNAL PROCESSING LETTERS, VOL. 22, NO. 7, JULY 2015 An Efficient Frame-Content Based Intra Frame Rate Control for High Efficiency Video Coding Miaohui Wang, Student Member, IEEE, KingNgiNgan,
Generic object recognition
 Generic object recognition May 19 th, 2015 Yong Jae Lee UC Davis Announcements PS3 out; due 6/3, 11:59 pm Sign attendance sheet (3 rd one) 2 Indexing local features 3 Kristen Grauman Visual words Map high-dimensional
Generic object recognition May 19 th, 2015 Yong Jae Lee UC Davis Announcements PS3 out; due 6/3, 11:59 pm Sign attendance sheet (3 rd one) 2 Indexing local features 3 Kristen Grauman Visual words Map high-dimensional
Music Information Retrieval with Temporal Features and Timbre
 Music Information Retrieval with Temporal Features and Timbre Angelina A. Tzacheva and Keith J. Bell University of South Carolina Upstate, Department of Informatics 800 University Way, Spartanburg, SC
Music Information Retrieval with Temporal Features and Timbre Angelina A. Tzacheva and Keith J. Bell University of South Carolina Upstate, Department of Informatics 800 University Way, Spartanburg, SC
Multi-modal Analysis for Person Type Classification in News Video
 Multi-modal Analysis for Person Type Classification in News Video Jun Yang, Alexander G. Hauptmann School of Computer Science, Carnegie Mellon University, 5000 Forbes Ave, PA 15213, USA {juny, alex}@cs.cmu.edu,
Multi-modal Analysis for Person Type Classification in News Video Jun Yang, Alexander G. Hauptmann School of Computer Science, Carnegie Mellon University, 5000 Forbes Ave, PA 15213, USA {juny, alex}@cs.cmu.edu,
Automatic Rhythmic Notation from Single Voice Audio Sources
 Automatic Rhythmic Notation from Single Voice Audio Sources Jack O Reilly, Shashwat Udit Introduction In this project we used machine learning technique to make estimations of rhythmic notation of a sung
Automatic Rhythmic Notation from Single Voice Audio Sources Jack O Reilly, Shashwat Udit Introduction In this project we used machine learning technique to make estimations of rhythmic notation of a sung
arxiv: v1 [cs.cv] 2 Nov 2017
![arxiv: v1 [cs.cv] 2 Nov 2017](/thumbs/71/65844936.jpg "arxiv: v1 [cs.cv] 2 Nov 2017") Understanding and Predicting The Attractiveness of Human Action Shot Bin Dai Institute for Advanced Study, Tsinghua University, Beijing, China daib13@mails.tsinghua.edu.cn Baoyuan Wang Microsoft Research,
Understanding and Predicting The Attractiveness of Human Action Shot Bin Dai Institute for Advanced Study, Tsinghua University, Beijing, China daib13@mails.tsinghua.edu.cn Baoyuan Wang Microsoft Research,
Xuelong Li, Thomas Huang. University of Illinois at Urbana-Champaign
 Non-Negative N Graph Embedding Jianchao Yang, Shuicheng Yan, Yun Fu, Xuelong Li, Thomas Huang Department of ECE, Beckman Institute and CSL University of Illinois at Urbana-Champaign Outline Non-negative
Non-Negative N Graph Embedding Jianchao Yang, Shuicheng Yan, Yun Fu, Xuelong Li, Thomas Huang Department of ECE, Beckman Institute and CSL University of Illinois at Urbana-Champaign Outline Non-negative
SCALABLE video coding (SVC) is currently being developed
 is currently being developed") IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 16, NO. 7, JULY 2006 889 Fast Mode Decision Algorithm for Inter-Frame Coding in Fully Scalable Video Coding He Li, Z. G. Li, Senior
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 16, NO. 7, JULY 2006 889 Fast Mode Decision Algorithm for Inter-Frame Coding in Fully Scalable Video Coding He Li, Z. G. Li, Senior
Sarcasm Detection in Text: Design Document
 CSC 59866 Senior Design Project Specification Professor Jie Wei Wednesday, November 23, 2016 Sarcasm Detection in Text: Design Document Jesse Feinman, James Kasakyan, Jeff Stolzenberg 1 Table of contents
CSC 59866 Senior Design Project Specification Professor Jie Wei Wednesday, November 23, 2016 Sarcasm Detection in Text: Design Document Jesse Feinman, James Kasakyan, Jeff Stolzenberg 1 Table of contents
Analysis of Packet Loss for Compressed Video: Does Burst-Length Matter?
 Analysis of Packet Loss for Compressed Video: Does Burst-Length Matter? Yi J. Liang 1, John G. Apostolopoulos, Bernd Girod 1 Mobile and Media Systems Laboratory HP Laboratories Palo Alto HPL-22-331 November
Analysis of Packet Loss for Compressed Video: Does Burst-Length Matter? Yi J. Liang 1, John G. Apostolopoulos, Bernd Girod 1 Mobile and Media Systems Laboratory HP Laboratories Palo Alto HPL-22-331 November
Composer Style Attribution
 Composer Style Attribution Jacqueline Speiser, Vishesh Gupta Introduction Josquin des Prez (1450 1521) is one of the most famous composers of the Renaissance. Despite his fame, there exists a significant
Composer Style Attribution Jacqueline Speiser, Vishesh Gupta Introduction Josquin des Prez (1450 1521) is one of the most famous composers of the Renaissance. Despite his fame, there exists a significant
Joint Optimization of Source-Channel Video Coding Using the H.264/AVC encoder and FEC Codes. Digital Signal and Image Processing Lab
 Joint Optimization of Source-Channel Video Coding Using the H.264/AVC encoder and FEC Codes Digital Signal and Image Processing Lab Simone Milani Ph.D. student simone.milani@dei.unipd.it, Summer School
Joint Optimization of Source-Channel Video Coding Using the H.264/AVC encoder and FEC Codes Digital Signal and Image Processing Lab Simone Milani Ph.D. student simone.milani@dei.unipd.it, Summer School
Video coding standards
 Video coding standards Video signals represent sequences of images or frames which can be transmitted with a rate from 5 to 60 frames per second (fps), that provides the illusion of motion in the displayed
Video coding standards Video signals represent sequences of images or frames which can be transmitted with a rate from 5 to 60 frames per second (fps), that provides the illusion of motion in the displayed
LOUDNESS EFFECT OF THE DIFFERENT TONES ON THE TIMBRE SUBJECTIVE PERCEPTION EXPERIMENT OF ERHU
 The 21 st International Congress on Sound and Vibration 13-17 July, 2014, Beijing/China LOUDNESS EFFECT OF THE DIFFERENT TONES ON THE TIMBRE SUBJECTIVE PERCEPTION EXPERIMENT OF ERHU Siyu Zhu, Peifeng Ji,
The 21 st International Congress on Sound and Vibration 13-17 July, 2014, Beijing/China LOUDNESS EFFECT OF THE DIFFERENT TONES ON THE TIMBRE SUBJECTIVE PERCEPTION EXPERIMENT OF ERHU Siyu Zhu, Peifeng Ji,
A Survey on: Sound Source Separation Methods
 Volume 3, Issue 11, November-2016, pp. 580-584 ISSN (O): 2349-7084 International Journal of Computer Engineering In Research Trends Available online at: www.ijcert.org A Survey on: Sound Source Separation
Volume 3, Issue 11, November-2016, pp. 580-584 ISSN (O): 2349-7084 International Journal of Computer Engineering In Research Trends Available online at: www.ijcert.org A Survey on: Sound Source Separation