Structured training for large-vocabulary chord recognition. Brian McFee* & Juan Pablo Bello
|
|
|
- Jonah Hall
- 6 years ago
- Views:
Transcription


1 Structured training for large-vocabulary chord recognition Brian McFee* & Juan Pablo Bello
2 Small chord vocabularies Typically a supervised learning problem N C:maj C:min C#:maj C#:min D:maj D:min B:maj B:min Frames chord labels 1-of-K classification models are common 25 classes: N + (12 min) + (12 maj) Hidden Markov Models, Deep convolutional networks, etc. Optimize accuracy, log-likelihood, etc.
3 Small chord vocabularies Typically a supervised learning problem N C:maj C:min C#:maj C#:min D:maj D:min B:maj B:min Frames chord labels 1-of-K classification models are common 25 classes: N + (12 min) + (12 maj) Hidden Markov Models, Deep convolutional networks, etc. Optimize accuracy, log-likelihood, etc. Implicit training assumption: All mistakes are equally bad
4 Large chord vocabularies Classes are not well-separated Chord quality Frequency maj 52.53% C:7 = C:maj + m7 min 13.63% C:sus4 vs. F:sus %... hdim7 0.17% dim7 0.07% minmaj7 0.04% Distribution of the 1217 dataset Class distribution is non-uniform Rare classes are hard to model

5 Some mistakes are better than others d a b y Ver Not so ba d


6 Some mistakes are better than others d This a b y Ver Not implies that chord so ba d space is structured!
7 Our contributions Deep learning architecture to exploit structure of chord symbols Improve accuracy in rare classes Preserve accuracy in common classes Bonus: package is online for you to use!
8 Chord simplification All classification models need a finite, canonical label set
9 Chord simplification All classification models need a finite, canonical label set Vocabulary simplification process: a. Ignore inversions G :9(*5)/3 G :9(*5)
10 Chord simplification All classification models need a finite, canonical label set Vocabulary simplification process: a. b. Ignore inversions Ignore added and suppressed notes G :9(*5)/3 G :9(*5) G :9
11 Chord simplification All classification models need a finite, canonical label set Vocabulary simplification process: a. b. c. Ignore inversions Ignore added and suppressed notes Template-match to nearest quality G :9(*5)/3 G :9(*5) G :9 G :7
12 Chord simplification All classification models need a finite, canonical label set Vocabulary simplification process: a. b. c. d. Ignore inversions Ignore added and suppressed notes Template-match to nearest quality Resolve enharmonic equivalences G :9(*5)/3 G :9(*5) G :9 G :7 F :7
13 Chord simplification All classification models need a finite, canonical label set Vocabulary simplification process: a. b. c. d. Ignore inversions Ignore added and suppressed notes Template-match to nearest quality Resolve enharmonic equivalences G :9(*5)/3 G :9(*5) Simp lifica (but all ch tion is lossy ord m! odel s do it) G :9 G :7 F :7
14 = 170 classes 14 qualities min maj dim aug min6 C C#... B N No chord (e.g., silence) X Out of gamut (e.g., power chords) maj6 min7 minmaj7 maj7 7 dim7 hdim7 sus2 sus4
15 Structural encoding Represent chord labels as binary encodings Encoding is lossless* and structured: Similar chords with different labels will have similar encodings Dissimilar chords will have dissimilar encodings Learning problem: Predict the encoding from audio Learn to decode into chord labels * up to octave-folding
16 The big idea Jointly estimate structured encoding AND chord labels Full objective = root loss + pitch loss + bass loss + decoder loss
![Model architectures Input: constant-q spectral patches Per-frame outputs: Root Pitches Bass Chords [multiclass, 13]](/docs-images/76/73041725/images/17-0.jpg "[multilabel, 12] [multiclass, 13] [multiclass, 170] Convolutional-recurrent architecture (encoder-decoder) End-to-end")
17 Model architectures Input: constant-q spectral patches Per-frame outputs: Root Pitches Bass Chords [multiclass, 13] [multilabel, 12] [multiclass, 13] [multiclass, 170] Convolutional-recurrent architecture (encoder-decoder) End-to-end training

18 Encoder architecture Hidden state at frame t: h(t) [-1, +1]D Suppress transients Encode frequencies Contextual smoothing
19 Decoder architectures Chords = Logistic regression from encoder state Frames are independently decoded: y(t) = softmax(w h(t) + β)
20 Decoder architectures Chords = Logistic regression from encoder state Decoding = GRU + LR Frames are recurrently decoded: h2(t) = Bi-GRU[h](t) y(t) = softmax(w h2(t) + β)
21 Decoder architectures Chords = Logistic regression from encoder state Decoding = GRU + LR Chords = LR from encoder state + root/pitch/bass Frames are independently decoded with structure: y(t) = softmax(wr r(t) + Wp p(t) + Wb b(t) + Wh h(t) + β)

22 Decoder architectures Chords = Logistic regression from encoder state Decoding = GRU + LR Chords = LR from encoder state + root/pitch/bass All of the above

23 What about root bias? Quality and root should be independent But the data is inherently biased Solution: data augmentation! muda [McFee, Humphrey, Bello 2015] Pitch-shift the audio and annotations simultaneously Each training track ± 6 semitone shifts All qualities are observed in all root positions All roots, pitches, and bass values are observed
24 Evaluation 8 configurations ± data augmentation ± structured training 1 vs. 2 recurrent layers 1217 recordings (Billboard + Isophonics + MARL corpus) 5-fold cross-validation Baseline models: DNN [Humphrey & Bello, 2015] KHMM [Cho, 2014]
25 CR1: 1 recurrent layer CR2: 2 recurrent layers Results Data augmentation (+A) is necessary to match baselines. +A: data augmentation +S: structure encoding
26 CR1: 1 recurrent layer Results CR2: 2 recurrent layers +A: data augmentation +S: structure encoding Structured training (+S) and deeper models improve over baselines.
27 CR1: 1 recurrent layer CR2: 2 recurrent layers Results Improvements are bigger on the harder metrics (7ths and tetrads) +A: data augmentation +S: structure encoding

28 CR1: 1 recurrent layer Results CR2: 2 recurrent layers +A: data augmentation +S: structure encoding Substantial gains in maj/min and MIREX metrics CR2+S+A wins on all metrics

29 Error analysis: quality confusions Errors tend toward simplification Reflects maj/min bias in training data Simplified vocab. accuracy: 63.6%
30 Summary Structured training helps Deeper is better Data augmentation is critical pip install muda Rare classes are still hard We probably need new data
31 Thanks! Questions? Implementation is online pip install crema
32 Extra goodies

33 Error analysis: CR2+S+A vs CR2+A Reduction of confusions to major Improvements in rare classes: aug, maj6, dim7, hdim7, sus4

34 Learned model weights Layer 1: Harmonic saliency Layer 2: Pitch filters (sorted by dominant frequency)
35 Training details Keras / TensorFlow + pescador ADAM optimizer Early learning rate Determined by decoder loss 8 seconds per patch 32 patches ber batch 1024 batches per epoch

36 Inter-root confusions Confusions primarily toward P4/P5
37 Inversion estimation For each detected chord segment Find the most likely bass note If that note is within the detected quality, predict it as the inversion Implemented in the crema package Inversion-sensitive metrics ~1% lower than inversion-agnostic

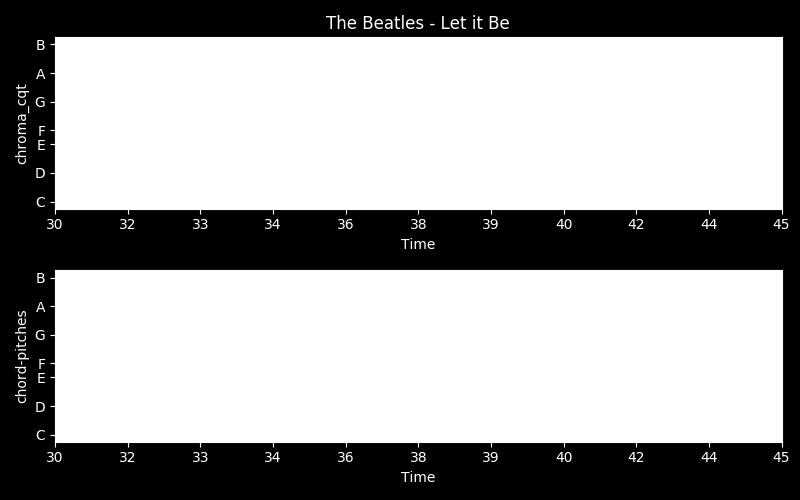
38 Pitches as chroma
Chord Label Personalization through Deep Learning of Integrated Harmonic Interval-based Representations
 Chord Label Personalization through Deep Learning of Integrated Harmonic Interval-based Representations Hendrik Vincent Koops 1, W. Bas de Haas 2, Jeroen Bransen 2, and Anja Volk 1 arxiv:1706.09552v1 [cs.sd]
Chord Label Personalization through Deep Learning of Integrated Harmonic Interval-based Representations Hendrik Vincent Koops 1, W. Bas de Haas 2, Jeroen Bransen 2, and Anja Volk 1 arxiv:1706.09552v1 [cs.sd]
Music Genre Classification
 Music Genre Classification chunya25 Fall 2017 1 Introduction A genre is defined as a category of artistic composition, characterized by similarities in form, style, or subject matter. [1] Some researchers
Music Genre Classification chunya25 Fall 2017 1 Introduction A genre is defined as a category of artistic composition, characterized by similarities in form, style, or subject matter. [1] Some researchers
Music Composition with RNN
 Music Composition with RNN Jason Wang Department of Statistics Stanford University zwang01@stanford.edu Abstract Music composition is an interesting problem that tests the creativity capacities of artificial
Music Composition with RNN Jason Wang Department of Statistics Stanford University zwang01@stanford.edu Abstract Music composition is an interesting problem that tests the creativity capacities of artificial
Data-Driven Solo Voice Enhancement for Jazz Music Retrieval
 Data-Driven Solo Voice Enhancement for Jazz Music Retrieval Stefan Balke1, Christian Dittmar1, Jakob Abeßer2, Meinard Müller1 1International Audio Laboratories Erlangen 2Fraunhofer Institute for Digital
Data-Driven Solo Voice Enhancement for Jazz Music Retrieval Stefan Balke1, Christian Dittmar1, Jakob Abeßer2, Meinard Müller1 1International Audio Laboratories Erlangen 2Fraunhofer Institute for Digital
Singer Traits Identification using Deep Neural Network
 Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Noise (Music) Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017
 Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017") Noise (Music) Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017 Background Abstract I attempted a solution at using machine learning to compose music given a large corpus
Noise (Music) Composition Using Classification Algorithms Peter Wang (pwang01) December 15, 2017 Background Abstract I attempted a solution at using machine learning to compose music given a large corpus
Detecting Musical Key with Supervised Learning
 Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
An AI Approach to Automatic Natural Music Transcription
 An AI Approach to Automatic Natural Music Transcription Michael Bereket Stanford University Stanford, CA mbereket@stanford.edu Karey Shi Stanford Univeristy Stanford, CA kareyshi@stanford.edu Abstract
An AI Approach to Automatic Natural Music Transcription Michael Bereket Stanford University Stanford, CA mbereket@stanford.edu Karey Shi Stanford Univeristy Stanford, CA kareyshi@stanford.edu Abstract
arxiv: v2 [cs.sd] 31 Mar 2017
![arxiv: v2 [cs.sd] 31 Mar 2017](/thumbs/76/73943146.jpg "arxiv: v2 [cs.sd] 31 Mar 2017") On the Futility of Learning Complex Frame-Level Language Models for Chord Recognition arxiv:1702.00178v2 [cs.sd] 31 Mar 2017 Abstract Filip Korzeniowski and Gerhard Widmer Department of Computational Perception
On the Futility of Learning Complex Frame-Level Language Models for Chord Recognition arxiv:1702.00178v2 [cs.sd] 31 Mar 2017 Abstract Filip Korzeniowski and Gerhard Widmer Department of Computational Perception
Automatic Construction of Synthetic Musical Instruments and Performers
 Ph.D. Thesis Proposal Automatic Construction of Synthetic Musical Instruments and Performers Ning Hu Carnegie Mellon University Thesis Committee Roger B. Dannenberg, Chair Michael S. Lewicki Richard M.
Ph.D. Thesis Proposal Automatic Construction of Synthetic Musical Instruments and Performers Ning Hu Carnegie Mellon University Thesis Committee Roger B. Dannenberg, Chair Michael S. Lewicki Richard M.
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng
 Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the
Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models
 Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models Aric Bartle (abartle@stanford.edu) December 14, 2012 1 Background The field of composer recognition has
Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models Aric Bartle (abartle@stanford.edu) December 14, 2012 1 Background The field of composer recognition has
LEARNING AUDIO SHEET MUSIC CORRESPONDENCES. Matthias Dorfer Department of Computational Perception
 LEARNING AUDIO SHEET MUSIC CORRESPONDENCES Matthias Dorfer Department of Computational Perception Short Introduction... I am a PhD Candidate in the Department of Computational Perception at Johannes Kepler
LEARNING AUDIO SHEET MUSIC CORRESPONDENCES Matthias Dorfer Department of Computational Perception Short Introduction... I am a PhD Candidate in the Department of Computational Perception at Johannes Kepler
Image-to-Markup Generation with Coarse-to-Fine Attention
 Image-to-Markup Generation with Coarse-to-Fine Attention Presenter: Ceyer Wakilpoor Yuntian Deng 1 Anssi Kanervisto 2 Alexander M. Rush 1 Harvard University 3 University of Eastern Finland ICML, 2017 Yuntian
Image-to-Markup Generation with Coarse-to-Fine Attention Presenter: Ceyer Wakilpoor Yuntian Deng 1 Anssi Kanervisto 2 Alexander M. Rush 1 Harvard University 3 University of Eastern Finland ICML, 2017 Yuntian
Chord Recognition with Stacked Denoising Autoencoders
 Chord Recognition with Stacked Denoising Autoencoders Author: Nikolaas Steenbergen Supervisors: Prof. Dr. Theo Gevers Dr. John Ashley Burgoyne A thesis submitted in fulfilment of the requirements for the
Chord Recognition with Stacked Denoising Autoencoders Author: Nikolaas Steenbergen Supervisors: Prof. Dr. Theo Gevers Dr. John Ashley Burgoyne A thesis submitted in fulfilment of the requirements for the
EE391 Special Report (Spring 2005) Automatic Chord Recognition Using A Summary Autocorrelation Function
 Automatic Chord Recognition Using A Summary Autocorrelation Function") EE391 Special Report (Spring 25) Automatic Chord Recognition Using A Summary Autocorrelation Function Advisor: Professor Julius Smith Kyogu Lee Center for Computer Research in Music and Acoustics (CCRMA)
EE391 Special Report (Spring 25) Automatic Chord Recognition Using A Summary Autocorrelation Function Advisor: Professor Julius Smith Kyogu Lee Center for Computer Research in Music and Acoustics (CCRMA)
Automatic Piano Music Transcription
 Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Homework 2 Key-finding algorithm
 Homework 2 Key-finding algorithm Li Su Research Center for IT Innovation, Academia, Taiwan lisu@citi.sinica.edu.tw (You don t need any solid understanding about the musical key before doing this homework,
Homework 2 Key-finding algorithm Li Su Research Center for IT Innovation, Academia, Taiwan lisu@citi.sinica.edu.tw (You don t need any solid understanding about the musical key before doing this homework,
Neural Network for Music Instrument Identi cation
 Neural Network for Music Instrument Identi cation Zhiwen Zhang(MSE), Hanze Tu(CCRMA), Yuan Li(CCRMA) SUN ID: zhiwen, hanze, yuanli92 Abstract - In the context of music, instrument identi cation would contribute
Neural Network for Music Instrument Identi cation Zhiwen Zhang(MSE), Hanze Tu(CCRMA), Yuan Li(CCRMA) SUN ID: zhiwen, hanze, yuanli92 Abstract - In the context of music, instrument identi cation would contribute
Chord Classification of an Audio Signal using Artificial Neural Network
 Chord Classification of an Audio Signal using Artificial Neural Network Ronesh Shrestha Student, Department of Electrical and Electronic Engineering, Kathmandu University, Dhulikhel, Nepal ---------------------------------------------------------------------***---------------------------------------------------------------------
Chord Classification of an Audio Signal using Artificial Neural Network Ronesh Shrestha Student, Department of Electrical and Electronic Engineering, Kathmandu University, Dhulikhel, Nepal ---------------------------------------------------------------------***---------------------------------------------------------------------
The Million Song Dataset
 The Million Song Dataset AUDIO FEATURES The Million Song Dataset There is no data like more data Bob Mercer of IBM (1985). T. Bertin-Mahieux, D.P.W. Ellis, B. Whitman, P. Lamere, The Million Song Dataset,
The Million Song Dataset AUDIO FEATURES The Million Song Dataset There is no data like more data Bob Mercer of IBM (1985). T. Bertin-Mahieux, D.P.W. Ellis, B. Whitman, P. Lamere, The Million Song Dataset,
A System for Automatic Chord Transcription from Audio Using Genre-Specific Hidden Markov Models
 A System for Automatic Chord Transcription from Audio Using Genre-Specific Hidden Markov Models Kyogu Lee Center for Computer Research in Music and Acoustics Stanford University, Stanford CA 94305, USA
A System for Automatic Chord Transcription from Audio Using Genre-Specific Hidden Markov Models Kyogu Lee Center for Computer Research in Music and Acoustics Stanford University, Stanford CA 94305, USA
Adaptive decoding of convolutional codes
 Adv. Radio Sci., 5, 29 214, 27 www.adv-radio-sci.net/5/29/27/ Author(s) 27. This work is licensed under a Creative Commons License. Advances in Radio Science Adaptive decoding of convolutional codes K.
Adv. Radio Sci., 5, 29 214, 27 www.adv-radio-sci.net/5/29/27/ Author(s) 27. This work is licensed under a Creative Commons License. Advances in Radio Science Adaptive decoding of convolutional codes K.
THE estimation of complexity of musical content is among. A data-driven model of tonal chord sequence complexity
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 A data-driven model of tonal chord sequence complexity Bruno Di Giorgi, Simon Dixon, Massimiliano Zanoni, and Augusto Sarti, Senior Member,
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 A data-driven model of tonal chord sequence complexity Bruno Di Giorgi, Simon Dixon, Massimiliano Zanoni, and Augusto Sarti, Senior Member,
Generating Music with Recurrent Neural Networks
 Generating Music with Recurrent Neural Networks 27 October 2017 Ushini Attanayake Supervised by Christian Walder Co-supervised by Henry Gardner COMP3740 Project Work in Computing The Australian National
Generating Music with Recurrent Neural Networks 27 October 2017 Ushini Attanayake Supervised by Christian Walder Co-supervised by Henry Gardner COMP3740 Project Work in Computing The Australian National
Computational Modelling of Harmony
 Computational Modelling of Harmony Simon Dixon Centre for Digital Music, Queen Mary University of London, Mile End Rd, London E1 4NS, UK simon.dixon@elec.qmul.ac.uk http://www.elec.qmul.ac.uk/people/simond
Computational Modelling of Harmony Simon Dixon Centre for Digital Music, Queen Mary University of London, Mile End Rd, London E1 4NS, UK simon.dixon@elec.qmul.ac.uk http://www.elec.qmul.ac.uk/people/simond
A STUDY ON LSTM NETWORKS FOR POLYPHONIC MUSIC SEQUENCE MODELLING
 A STUDY ON LSTM NETWORKS FOR POLYPHONIC MUSIC SEQUENCE MODELLING Adrien Ycart and Emmanouil Benetos Centre for Digital Music, Queen Mary University of London, UK {a.ycart, emmanouil.benetos}@qmul.ac.uk
A STUDY ON LSTM NETWORKS FOR POLYPHONIC MUSIC SEQUENCE MODELLING Adrien Ycart and Emmanouil Benetos Centre for Digital Music, Queen Mary University of London, UK {a.ycart, emmanouil.benetos}@qmul.ac.uk
mir_eval: A TRANSPARENT IMPLEMENTATION OF COMMON MIR METRICS
 mir_eval: A TRANSPARENT IMPLEMENTATION OF COMMON MIR METRICS Colin Raffel 1,*, Brian McFee 1,2, Eric J. Humphrey 3, Justin Salamon 3,4, Oriol Nieto 3, Dawen Liang 1, and Daniel P. W. Ellis 1 1 LabROSA,
mir_eval: A TRANSPARENT IMPLEMENTATION OF COMMON MIR METRICS Colin Raffel 1,*, Brian McFee 1,2, Eric J. Humphrey 3, Justin Salamon 3,4, Oriol Nieto 3, Dawen Liang 1, and Daniel P. W. Ellis 1 1 LabROSA,
2016 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT , 2016, SALERNO, ITALY
 216 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 13 16, 216, SALERNO, ITALY A FULLY CONVOLUTIONAL DEEP AUDITORY MODEL FOR MUSICAL CHORD RECOGNITION Filip Korzeniowski and
216 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 13 16, 216, SALERNO, ITALY A FULLY CONVOLUTIONAL DEEP AUDITORY MODEL FOR MUSICAL CHORD RECOGNITION Filip Korzeniowski and
A probabilistic framework for audio-based tonal key and chord recognition
 A probabilistic framework for audio-based tonal key and chord recognition Benoit Catteau 1, Jean-Pierre Martens 1, and Marc Leman 2 1 ELIS - Electronics & Information Systems, Ghent University, Gent (Belgium)
A probabilistic framework for audio-based tonal key and chord recognition Benoit Catteau 1, Jean-Pierre Martens 1, and Marc Leman 2 1 ELIS - Electronics & Information Systems, Ghent University, Gent (Belgium)
Searching for Similar Phrases in Music Audio
 Searching for Similar Phrases in Music udio an Ellis Laboratory for Recognition and Organization of Speech and udio ept. Electrical Engineering, olumbia University, NY US http://labrosa.ee.columbia.edu/
Searching for Similar Phrases in Music udio an Ellis Laboratory for Recognition and Organization of Speech and udio ept. Electrical Engineering, olumbia University, NY US http://labrosa.ee.columbia.edu/
Pitch Perception and Grouping. HST.723 Neural Coding and Perception of Sound
 Pitch Perception and Grouping HST.723 Neural Coding and Perception of Sound Pitch Perception. I. Pure Tones The pitch of a pure tone is strongly related to the tone s frequency, although there are small
Pitch Perception and Grouping HST.723 Neural Coding and Perception of Sound Pitch Perception. I. Pure Tones The pitch of a pure tone is strongly related to the tone s frequency, although there are small
Lecture 9 Source Separation
 10420CS 573100 音樂資訊檢索 Music Information Retrieval Lecture 9 Source Separation Yi-Hsuan Yang Ph.D. http://www.citi.sinica.edu.tw/pages/yang/ yang@citi.sinica.edu.tw Music & Audio Computing Lab, Research
10420CS 573100 音樂資訊檢索 Music Information Retrieval Lecture 9 Source Separation Yi-Hsuan Yang Ph.D. http://www.citi.sinica.edu.tw/pages/yang/ yang@citi.sinica.edu.tw Music & Audio Computing Lab, Research
JOINT BEAT AND DOWNBEAT TRACKING WITH RECURRENT NEURAL NETWORKS
 JOINT BEAT AND DOWNBEAT TRACKING WITH RECURRENT NEURAL NETWORKS Sebastian Böck, Florian Krebs, and Gerhard Widmer Department of Computational Perception Johannes Kepler University Linz, Austria sebastian.boeck@jku.at
JOINT BEAT AND DOWNBEAT TRACKING WITH RECURRENT NEURAL NETWORKS Sebastian Böck, Florian Krebs, and Gerhard Widmer Department of Computational Perception Johannes Kepler University Linz, Austria sebastian.boeck@jku.at
gresearch Focus Cognitive Sciences
 Learning about Music Cognition by Asking MIR Questions Sebastian Stober August 12, 2016 CogMIR, New York City sstober@uni-potsdam.de http://www.uni-potsdam.de/mlcog/ MLC g Machine Learning in Cognitive
Learning about Music Cognition by Asking MIR Questions Sebastian Stober August 12, 2016 CogMIR, New York City sstober@uni-potsdam.de http://www.uni-potsdam.de/mlcog/ MLC g Machine Learning in Cognitive
Basic Theory Test, Part A - Notes and intervals
 CONCORDIA UNIVERSITY DEPARTMENT OF MUSIC - CONCORDIA Hello, Georges! Your Account Your Desks CONCORDIA UNIVERSITY DEPARTMENT OF MUSIC - CONCORDIA APPLICATION Basic Theory Test, Part A - Notes and intervals
CONCORDIA UNIVERSITY DEPARTMENT OF MUSIC - CONCORDIA Hello, Georges! Your Account Your Desks CONCORDIA UNIVERSITY DEPARTMENT OF MUSIC - CONCORDIA APPLICATION Basic Theory Test, Part A - Notes and intervals
Student Performance Q&A:
 Student Performance Q&A: 2002 AP Music Theory Free-Response Questions The following comments are provided by the Chief Reader about the 2002 free-response questions for AP Music Theory. They are intended
Student Performance Q&A: 2002 AP Music Theory Free-Response Questions The following comments are provided by the Chief Reader about the 2002 free-response questions for AP Music Theory. They are intended
LSTM Neural Style Transfer in Music Using Computational Musicology
 LSTM Neural Style Transfer in Music Using Computational Musicology Jett Oristaglio Dartmouth College, June 4 2017 1. Introduction In the 2016 paper A Neural Algorithm of Artistic Style, Gatys et al. discovered
LSTM Neural Style Transfer in Music Using Computational Musicology Jett Oristaglio Dartmouth College, June 4 2017 1. Introduction In the 2016 paper A Neural Algorithm of Artistic Style, Gatys et al. discovered
AUTOMATIC ACCOMPANIMENT OF VOCAL MELODIES IN THE CONTEXT OF POPULAR MUSIC
 AUTOMATIC ACCOMPANIMENT OF VOCAL MELODIES IN THE CONTEXT OF POPULAR MUSIC A Thesis Presented to The Academic Faculty by Xiang Cao In Partial Fulfillment of the Requirements for the Degree Master of Science
AUTOMATIC ACCOMPANIMENT OF VOCAL MELODIES IN THE CONTEXT OF POPULAR MUSIC A Thesis Presented to The Academic Faculty by Xiang Cao In Partial Fulfillment of the Requirements for the Degree Master of Science
Automatic Music Genre Classification
 Automatic Music Genre Classification Nathan YongHoon Kwon, SUNY Binghamton Ingrid Tchakoua, Jackson State University Matthew Pietrosanu, University of Alberta Freya Fu, Colorado State University Yue Wang,
Automatic Music Genre Classification Nathan YongHoon Kwon, SUNY Binghamton Ingrid Tchakoua, Jackson State University Matthew Pietrosanu, University of Alberta Freya Fu, Colorado State University Yue Wang,
Experimenting with Musically Motivated Convolutional Neural Networks
 Experimenting with Musically Motivated Convolutional Neural Networks Jordi Pons 1, Thomas Lidy 2 and Xavier Serra 1 1 Music Technology Group, Universitat Pompeu Fabra, Barcelona 2 Institute of Software
Experimenting with Musically Motivated Convolutional Neural Networks Jordi Pons 1, Thomas Lidy 2 and Xavier Serra 1 1 Music Technology Group, Universitat Pompeu Fabra, Barcelona 2 Institute of Software
An Introduction to Deep Image Aesthetics
 Seminar in Laboratory of Visual Intelligence and Pattern Analysis (VIPA) An Introduction to Deep Image Aesthetics Yongcheng Jing College of Computer Science and Technology Zhejiang University Zhenchuan
Seminar in Laboratory of Visual Intelligence and Pattern Analysis (VIPA) An Introduction to Deep Image Aesthetics Yongcheng Jing College of Computer Science and Technology Zhejiang University Zhenchuan
COMP 249 Advanced Distributed Systems Multimedia Networking. Video Compression Standards
 COMP 9 Advanced Distributed Systems Multimedia Networking Video Compression Standards Kevin Jeffay Department of Computer Science University of North Carolina at Chapel Hill jeffay@cs.unc.edu September,
COMP 9 Advanced Distributed Systems Multimedia Networking Video Compression Standards Kevin Jeffay Department of Computer Science University of North Carolina at Chapel Hill jeffay@cs.unc.edu September,
Recognition and Summarization of Chord Progressions and Their Application to Music Information Retrieval
 Recognition and Summarization of Chord Progressions and Their Application to Music Information Retrieval Yi Yu, Roger Zimmermann, Ye Wang School of Computing National University of Singapore Singapore
Recognition and Summarization of Chord Progressions and Their Application to Music Information Retrieval Yi Yu, Roger Zimmermann, Ye Wang School of Computing National University of Singapore Singapore
Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj
 Bhiksha Raj") Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj 1 Story so far MLPs are universal function approximators Boolean functions, classifiers, and regressions MLPs can be
Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj 1 Story so far MLPs are universal function approximators Boolean functions, classifiers, and regressions MLPs can be
Music Information Retrieval for Jazz
 Music Information Retrieval for Jazz Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,thierry}@ee.columbia.edu http://labrosa.ee.columbia.edu/
Music Information Retrieval for Jazz Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,thierry}@ee.columbia.edu http://labrosa.ee.columbia.edu/
CHORD GENERATION FROM SYMBOLIC MELODY USING BLSTM NETWORKS
 CHORD GENERATION FROM SYMBOLIC MELODY USING BLSTM NETWORKS Hyungui Lim 1,2, Seungyeon Rhyu 1 and Kyogu Lee 1,2 3 Music and Audio Research Group, Graduate School of Convergence Science and Technology 4
CHORD GENERATION FROM SYMBOLIC MELODY USING BLSTM NETWORKS Hyungui Lim 1,2, Seungyeon Rhyu 1 and Kyogu Lee 1,2 3 Music and Audio Research Group, Graduate School of Convergence Science and Technology 4
Compressed-Sensing-Enabled Video Streaming for Wireless Multimedia Sensor Networks Abstract:
 Compressed-Sensing-Enabled Video Streaming for Wireless Multimedia Sensor Networks Abstract: This article1 presents the design of a networked system for joint compression, rate control and error correction
Compressed-Sensing-Enabled Video Streaming for Wireless Multimedia Sensor Networks Abstract: This article1 presents the design of a networked system for joint compression, rate control and error correction
Chorale Harmonisation in the Style of J.S. Bach A Machine Learning Approach. Alex Chilvers
 Chorale Harmonisation in the Style of J.S. Bach A Machine Learning Approach Alex Chilvers 2006 Contents 1 Introduction 3 2 Project Background 5 3 Previous Work 7 3.1 Music Representation........................
Chorale Harmonisation in the Style of J.S. Bach A Machine Learning Approach Alex Chilvers 2006 Contents 1 Introduction 3 2 Project Background 5 3 Previous Work 7 3.1 Music Representation........................
The reduction in the number of flip-flops in a sequential circuit is referred to as the state-reduction problem.
 State Reduction The reduction in the number of flip-flops in a sequential circuit is referred to as the state-reduction problem. State-reduction algorithms are concerned with procedures for reducing the
State Reduction The reduction in the number of flip-flops in a sequential circuit is referred to as the state-reduction problem. State-reduction algorithms are concerned with procedures for reducing the
A Psychoacoustically Motivated Technique for the Automatic Transcription of Chords from Musical Audio
 A Psychoacoustically Motivated Technique for the Automatic Transcription of Chords from Musical Audio Daniel Throssell School of Electrical, Electronic & Computer Engineering The University of Western
A Psychoacoustically Motivated Technique for the Automatic Transcription of Chords from Musical Audio Daniel Throssell School of Electrical, Electronic & Computer Engineering The University of Western
CS229 Project Report Polyphonic Piano Transcription
 CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
Probabilist modeling of musical chord sequences for music analysis
 Probabilist modeling of musical chord sequences for music analysis Christophe Hauser January 29, 2009 1 INTRODUCTION Computer and network technologies have improved consequently over the last years. Technology
Probabilist modeling of musical chord sequences for music analysis Christophe Hauser January 29, 2009 1 INTRODUCTION Computer and network technologies have improved consequently over the last years. Technology
Topic 4. Single Pitch Detection
 Topic 4 Single Pitch Detection What is pitch? A perceptual attribute, so subjective Only defined for (quasi) harmonic sounds Harmonic sounds are periodic, and the period is 1/F0. Can be reliably matched
Topic 4 Single Pitch Detection What is pitch? A perceptual attribute, so subjective Only defined for (quasi) harmonic sounds Harmonic sounds are periodic, and the period is 1/F0. Can be reliably matched
AUDIO-ALIGNED JAZZ HARMONY DATASET FOR AUTOMATIC CHORD TRANSCRIPTION AND CORPUS-BASED RESEARCH
 AUDIO-ALIGNED JAZZ HARMONY DATASET FOR AUTOMATIC CHORD TRANSCRIPTION AND CORPUS-BASED RESEARCH Vsevolod Eremenko, Emir Demirel, Baris Bozkurt, Xavier Serra Music Technology Group, Universitat Pompeu Fabra,
AUDIO-ALIGNED JAZZ HARMONY DATASET FOR AUTOMATIC CHORD TRANSCRIPTION AND CORPUS-BASED RESEARCH Vsevolod Eremenko, Emir Demirel, Baris Bozkurt, Xavier Serra Music Technology Group, Universitat Pompeu Fabra,
Acoustic Scene Classification
 Acoustic Scene Classification Marc-Christoph Gerasch Seminar Topics in Computer Music - Acoustic Scene Classification 6/24/2015 1 Outline Acoustic Scene Classification - definition History and state of
Acoustic Scene Classification Marc-Christoph Gerasch Seminar Topics in Computer Music - Acoustic Scene Classification 6/24/2015 1 Outline Acoustic Scene Classification - definition History and state of
DeepID: Deep Learning for Face Recognition. Department of Electronic Engineering,
 DeepID: Deep Learning for Face Recognition Xiaogang Wang Department of Electronic Engineering, The Chinese University i of Hong Kong Machine Learning with Big Data Machine learning with small data: overfitting,
DeepID: Deep Learning for Face Recognition Xiaogang Wang Department of Electronic Engineering, The Chinese University i of Hong Kong Machine Learning with Big Data Machine learning with small data: overfitting,
Deep Jammer: A Music Generation Model
 Deep Jammer: A Music Generation Model Justin Svegliato and Sam Witty College of Information and Computer Sciences University of Massachusetts Amherst, MA 01003, USA {jsvegliato,switty}@cs.umass.edu Abstract
Deep Jammer: A Music Generation Model Justin Svegliato and Sam Witty College of Information and Computer Sciences University of Massachusetts Amherst, MA 01003, USA {jsvegliato,switty}@cs.umass.edu Abstract
AUDIOVISUAL COMMUNICATION
 AUDIOVISUAL COMMUNICATION Laboratory Session: Recommendation ITU-T H.261 Fernando Pereira The objective of this lab session about Recommendation ITU-T H.261 is to get the students familiar with many aspects
AUDIOVISUAL COMMUNICATION Laboratory Session: Recommendation ITU-T H.261 Fernando Pereira The objective of this lab session about Recommendation ITU-T H.261 is to get the students familiar with many aspects
Using Genre Classification to Make Content-based Music Recommendations
 Using Genre Classification to Make Content-based Music Recommendations Robbie Jones (rmjones@stanford.edu) and Karen Lu (karenlu@stanford.edu) CS 221, Autumn 2016 Stanford University I. Introduction Our
Using Genre Classification to Make Content-based Music Recommendations Robbie Jones (rmjones@stanford.edu) and Karen Lu (karenlu@stanford.edu) CS 221, Autumn 2016 Stanford University I. Introduction Our
Week 14 Music Understanding and Classification
 Week 14 Music Understanding and Classification Roger B. Dannenberg Professor of Computer Science, Music & Art Overview n Music Style Classification n What s a classifier? n Naïve Bayesian Classifiers n
Week 14 Music Understanding and Classification Roger B. Dannenberg Professor of Computer Science, Music & Art Overview n Music Style Classification n What s a classifier? n Naïve Bayesian Classifiers n
Personalized TV Recommendation with Mixture Probabilistic Matrix Factorization
 Personalized TV Recommendation with Mixture Probabilistic Matrix Factorization Huayu Li, Hengshu Zhu #, Yong Ge, Yanjie Fu +,Yuan Ge Computer Science Department, UNC Charlotte # Baidu Research-Big Data
Personalized TV Recommendation with Mixture Probabilistic Matrix Factorization Huayu Li, Hengshu Zhu #, Yong Ge, Yanjie Fu +,Yuan Ge Computer Science Department, UNC Charlotte # Baidu Research-Big Data
Deep learning for music data processing
 Deep learning for music data processing A personal (re)view of the state-of-the-art Jordi Pons www.jordipons.me Music Technology Group, DTIC, Universitat Pompeu Fabra, Barcelona. 31st January 2017 Jordi
Deep learning for music data processing A personal (re)view of the state-of-the-art Jordi Pons www.jordipons.me Music Technology Group, DTIC, Universitat Pompeu Fabra, Barcelona. 31st January 2017 Jordi
Music Similarity and Cover Song Identification: The Case of Jazz
 Music Similarity and Cover Song Identification: The Case of Jazz Simon Dixon and Peter Foster s.e.dixon@qmul.ac.uk Centre for Digital Music School of Electronic Engineering and Computer Science Queen Mary
Music Similarity and Cover Song Identification: The Case of Jazz Simon Dixon and Peter Foster s.e.dixon@qmul.ac.uk Centre for Digital Music School of Electronic Engineering and Computer Science Queen Mary
DAY 1. Intelligent Audio Systems: A review of the foundations and applications of semantic audio analysis and music information retrieval
 DAY 1 Intelligent Audio Systems: A review of the foundations and applications of semantic audio analysis and music information retrieval Jay LeBoeuf Imagine Research jay{at}imagine-research.com Rebecca
DAY 1 Intelligent Audio Systems: A review of the foundations and applications of semantic audio analysis and music information retrieval Jay LeBoeuf Imagine Research jay{at}imagine-research.com Rebecca
Music Emotion Recognition. Jaesung Lee. Chung-Ang University
 Music Emotion Recognition Jaesung Lee Chung-Ang University Introduction Searching Music in Music Information Retrieval Some information about target music is available Query by Text: Title, Artist, or
Music Emotion Recognition Jaesung Lee Chung-Ang University Introduction Searching Music in Music Information Retrieval Some information about target music is available Query by Text: Title, Artist, or
A Survey of Audio-Based Music Classification and Annotation
 A Survey of Audio-Based Music Classification and Annotation Zhouyu Fu, Guojun Lu, Kai Ming Ting, and Dengsheng Zhang IEEE Trans. on Multimedia, vol. 13, no. 2, April 2011 presenter: Yin-Tzu Lin ( 阿孜孜 ^.^)
A Survey of Audio-Based Music Classification and Annotation Zhouyu Fu, Guojun Lu, Kai Ming Ting, and Dengsheng Zhang IEEE Trans. on Multimedia, vol. 13, no. 2, April 2011 presenter: Yin-Tzu Lin ( 阿孜孜 ^.^)
Chord Recognition in Symbolic Music: A Segmental CRF Model, Segment-Level Features, and Comparative Evaluations on Classical and Popular Music
 Masada, K. and Bunescu, R. (2018). Chord Recognition in Symbolic Music: A Segmental CRF Model, Segment-Level Features, and Comparative Evaluations on Classical and Popular Music, Transactions of the International
Masada, K. and Bunescu, R. (2018). Chord Recognition in Symbolic Music: A Segmental CRF Model, Segment-Level Features, and Comparative Evaluations on Classical and Popular Music, Transactions of the International
Pitch. The perceptual correlate of frequency: the perceptual dimension along which sounds can be ordered from low to high.
 Pitch The perceptual correlate of frequency: the perceptual dimension along which sounds can be ordered from low to high. 1 The bottom line Pitch perception involves the integration of spectral (place)
Pitch The perceptual correlate of frequency: the perceptual dimension along which sounds can be ordered from low to high. 1 The bottom line Pitch perception involves the integration of spectral (place)
Finding Sarcasm in Reddit Postings: A Deep Learning Approach
 Finding Sarcasm in Reddit Postings: A Deep Learning Approach Nick Guo, Ruchir Shah {nickguo, ruchirfs}@stanford.edu Abstract We use the recently published Self-Annotated Reddit Corpus (SARC) with a recurrent
Finding Sarcasm in Reddit Postings: A Deep Learning Approach Nick Guo, Ruchir Shah {nickguo, ruchirfs}@stanford.edu Abstract We use the recently published Self-Annotated Reddit Corpus (SARC) with a recurrent
SINGING VOICE MELODY TRANSCRIPTION USING DEEP NEURAL NETWORKS
 SINGING VOICE MELODY TRANSCRIPTION USING DEEP NEURAL NETWORKS François Rigaud and Mathieu Radenen Audionamix R&D 7 quai de Valmy, 7 Paris, France .@audionamix.com ABSTRACT This paper
SINGING VOICE MELODY TRANSCRIPTION USING DEEP NEURAL NETWORKS François Rigaud and Mathieu Radenen Audionamix R&D 7 quai de Valmy, 7 Paris, France .@audionamix.com ABSTRACT This paper
POST-PROCESSING FIDDLE : A REAL-TIME MULTI-PITCH TRACKING TECHNIQUE USING HARMONIC PARTIAL SUBTRACTION FOR USE WITHIN LIVE PERFORMANCE SYSTEMS
 POST-PROCESSING FIDDLE : A REAL-TIME MULTI-PITCH TRACKING TECHNIQUE USING HARMONIC PARTIAL SUBTRACTION FOR USE WITHIN LIVE PERFORMANCE SYSTEMS Andrew N. Robertson, Mark D. Plumbley Centre for Digital Music
POST-PROCESSING FIDDLE : A REAL-TIME MULTI-PITCH TRACKING TECHNIQUE USING HARMONIC PARTIAL SUBTRACTION FOR USE WITHIN LIVE PERFORMANCE SYSTEMS Andrew N. Robertson, Mark D. Plumbley Centre for Digital Music
IMPROVED CHORD RECOGNITION BY COMBINING DURATION AND HARMONIC LANGUAGE MODELS
 IMPROVED CHORD RECOGNITION BY COMBINING DURATION AND HARMONIC LANGUAGE MODELS Filip Korzeniowski and Gerhard Widmer Institute of Computational Perception, Johannes Kepler University, Linz, Austria filip.korzeniowski@jku.at
IMPROVED CHORD RECOGNITION BY COMBINING DURATION AND HARMONIC LANGUAGE MODELS Filip Korzeniowski and Gerhard Widmer Institute of Computational Perception, Johannes Kepler University, Linz, Austria filip.korzeniowski@jku.at
Labelling. Friday 18th May. Goldsmiths, University of London. Bayesian Model Selection for Harmonic. Labelling. Christophe Rhodes.
 Selection Bayesian Goldsmiths, University of London Friday 18th May Selection 1 Selection 2 3 4 Selection The task: identifying chords and assigning harmonic labels in popular music. currently to MIDI
Selection Bayesian Goldsmiths, University of London Friday 18th May Selection 1 Selection 2 3 4 Selection The task: identifying chords and assigning harmonic labels in popular music. currently to MIDI
Laughbot: Detecting Humor in Spoken Language with Language and Audio Cues
 Laughbot: Detecting Humor in Spoken Language with Language and Audio Cues Kate Park katepark@stanford.edu Annie Hu anniehu@stanford.edu Natalie Muenster ncm000@stanford.edu Abstract We propose detecting
Laughbot: Detecting Humor in Spoken Language with Language and Audio Cues Kate Park katepark@stanford.edu Annie Hu anniehu@stanford.edu Natalie Muenster ncm000@stanford.edu Abstract We propose detecting
Audio: Generation & Extraction. Charu Jaiswal
 Audio: Generation & Extraction Charu Jaiswal Music Composition which approach? Feed forward NN can t store information about past (or keep track of position in song) RNN as a single step predictor struggle
Audio: Generation & Extraction Charu Jaiswal Music Composition which approach? Feed forward NN can t store information about past (or keep track of position in song) RNN as a single step predictor struggle
A CHROMA-BASED SALIENCE FUNCTION FOR MELODY AND BASS LINE ESTIMATION FROM MUSIC AUDIO SIGNALS
 A CHROMA-BASED SALIENCE FUNCTION FOR MELODY AND BASS LINE ESTIMATION FROM MUSIC AUDIO SIGNALS Justin Salamon Music Technology Group Universitat Pompeu Fabra, Barcelona, Spain justin.salamon@upf.edu Emilia
A CHROMA-BASED SALIENCE FUNCTION FOR MELODY AND BASS LINE ESTIMATION FROM MUSIC AUDIO SIGNALS Justin Salamon Music Technology Group Universitat Pompeu Fabra, Barcelona, Spain justin.salamon@upf.edu Emilia
Take a Break, Bach! Let Machine Learning Harmonize That Chorale For You. Chris Lewis Stanford University
 Take a Break, Bach! Let Machine Learning Harmonize That Chorale For You Chris Lewis Stanford University cmslewis@stanford.edu Abstract In this project, I explore the effectiveness of the Naive Bayes Classifier
Take a Break, Bach! Let Machine Learning Harmonize That Chorale For You Chris Lewis Stanford University cmslewis@stanford.edu Abstract In this project, I explore the effectiveness of the Naive Bayes Classifier
Lessons from the Netflix Prize: Going beyond the algorithms
 Lessons from the Netflix Prize: Going beyond the algorithms Yehuda Koren movie #868 Haifa movie #76 movie #666 We Know What You Ought To Be Watching This Summer We re quite curious, really. To the tune
Lessons from the Netflix Prize: Going beyond the algorithms Yehuda Koren movie #868 Haifa movie #76 movie #666 We Know What You Ought To Be Watching This Summer We re quite curious, really. To the tune
CSC475 Music Information Retrieval
 CSC475 Music Information Retrieval Monophonic pitch extraction George Tzanetakis University of Victoria 2014 G. Tzanetakis 1 / 32 Table of Contents I 1 Motivation and Terminology 2 Psychacoustics 3 F0
CSC475 Music Information Retrieval Monophonic pitch extraction George Tzanetakis University of Victoria 2014 G. Tzanetakis 1 / 32 Table of Contents I 1 Motivation and Terminology 2 Psychacoustics 3 F0
Sarcasm Detection in Text: Design Document
 CSC 59866 Senior Design Project Specification Professor Jie Wei Wednesday, November 23, 2016 Sarcasm Detection in Text: Design Document Jesse Feinman, James Kasakyan, Jeff Stolzenberg 1 Table of contents
CSC 59866 Senior Design Project Specification Professor Jie Wei Wednesday, November 23, 2016 Sarcasm Detection in Text: Design Document Jesse Feinman, James Kasakyan, Jeff Stolzenberg 1 Table of contents
AP Music Theory 2010 Scoring Guidelines
 AP Music Theory 2010 Scoring Guidelines The College Board The College Board is a not-for-profit membership association whose mission is to connect students to college success and opportunity. Founded in
AP Music Theory 2010 Scoring Guidelines The College Board The College Board is a not-for-profit membership association whose mission is to connect students to college success and opportunity. Founded in
MUSI-6201 Computational Music Analysis
 MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
RECOMMENDATION ITU-R BT (Questions ITU-R 25/11, ITU-R 60/11 and ITU-R 61/11)
") Rec. ITU-R BT.61-4 1 SECTION 11B: DIGITAL TELEVISION RECOMMENDATION ITU-R BT.61-4 Rec. ITU-R BT.61-4 ENCODING PARAMETERS OF DIGITAL TELEVISION FOR STUDIOS (Questions ITU-R 25/11, ITU-R 6/11 and ITU-R 61/11)
Rec. ITU-R BT.61-4 1 SECTION 11B: DIGITAL TELEVISION RECOMMENDATION ITU-R BT.61-4 Rec. ITU-R BT.61-4 ENCODING PARAMETERS OF DIGITAL TELEVISION FOR STUDIOS (Questions ITU-R 25/11, ITU-R 6/11 and ITU-R 61/11)
A DISCRETE MIXTURE MODEL FOR CHORD LABELLING
 A DISCRETE MIXTURE MODEL FOR CHORD LABELLING Matthias Mauch and Simon Dixon Queen Mary, University of London, Centre for Digital Music. matthias.mauch@elec.qmul.ac.uk ABSTRACT Chord labels for recorded
A DISCRETE MIXTURE MODEL FOR CHORD LABELLING Matthias Mauch and Simon Dixon Queen Mary, University of London, Centre for Digital Music. matthias.mauch@elec.qmul.ac.uk ABSTRACT Chord labels for recorded
Music Generation from MIDI datasets
 Music Generation from MIDI datasets Moritz Hilscher, Novin Shahroudi 2 Institute of Computer Science, University of Tartu moritz.hilscher@student.hpi.de, 2 novin@ut.ee Abstract. Many approaches are being
Music Generation from MIDI datasets Moritz Hilscher, Novin Shahroudi 2 Institute of Computer Science, University of Tartu moritz.hilscher@student.hpi.de, 2 novin@ut.ee Abstract. Many approaches are being
IEEE Proof Web Version
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 22, NO. 2, FEBRUARY 2014 1 Automatic Chord Estimation from Audio: AReviewoftheStateoftheArt Matt McVicar, Raúl Santos-Rodríguez, Yizhao
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 22, NO. 2, FEBRUARY 2014 1 Automatic Chord Estimation from Audio: AReviewoftheStateoftheArt Matt McVicar, Raúl Santos-Rodríguez, Yizhao
Minimax Disappointment Video Broadcasting
 Minimax Disappointment Video Broadcasting DSP Seminar Spring 2001 Leiming R. Qian and Douglas L. Jones http://www.ifp.uiuc.edu/ lqian Seminar Outline 1. Motivation and Introduction 2. Background Knowledge
Minimax Disappointment Video Broadcasting DSP Seminar Spring 2001 Leiming R. Qian and Douglas L. Jones http://www.ifp.uiuc.edu/ lqian Seminar Outline 1. Motivation and Introduction 2. Background Knowledge
First Step Towards Enhancing Word Embeddings with Pitch Accents for DNN-based Slot Filling on Recognized Text
 First Step Towards Enhancing Word Embeddings with Pitch Accents for DNN-based Slot Filling on Recognized Text Sabrina Stehwien, Ngoc Thang Vu IMS, University of Stuttgart March 16, 2017 Slot Filling sequential
First Step Towards Enhancing Word Embeddings with Pitch Accents for DNN-based Slot Filling on Recognized Text Sabrina Stehwien, Ngoc Thang Vu IMS, University of Stuttgart March 16, 2017 Slot Filling sequential
arxiv: v1 [cs.lg] 15 Jun 2016
![arxiv: v1 [cs.lg] 15 Jun 2016](/thumbs/79/79195906.jpg "arxiv: v1 [cs.lg] 15 Jun 2016") Deep Learning for Music arxiv:1606.04930v1 [cs.lg] 15 Jun 2016 Allen Huang Department of Management Science and Engineering Stanford University allenh@cs.stanford.edu Abstract Raymond Wu Department of
Deep Learning for Music arxiv:1606.04930v1 [cs.lg] 15 Jun 2016 Allen Huang Department of Management Science and Engineering Stanford University allenh@cs.stanford.edu Abstract Raymond Wu Department of
Jazz Melody Generation and Recognition
 Jazz Melody Generation and Recognition Joseph Victor December 14, 2012 Introduction In this project, we attempt to use machine learning methods to study jazz solos. The reason we study jazz in particular
Jazz Melody Generation and Recognition Joseph Victor December 14, 2012 Introduction In this project, we attempt to use machine learning methods to study jazz solos. The reason we study jazz in particular
Combinational / Sequential Logic
 Digital Circuit Design and Language Combinational / Sequential Logic Chang, Ik Joon Kyunghee University Combinational Logic + The outputs are determined by the present inputs + Consist of input/output
Digital Circuit Design and Language Combinational / Sequential Logic Chang, Ik Joon Kyunghee University Combinational Logic + The outputs are determined by the present inputs + Consist of input/output
Scene Classification with Inception-7. Christian Szegedy with Julian Ibarz and Vincent Vanhoucke
 Scene Classification with Inception-7 Christian Szegedy with Julian Ibarz and Vincent Vanhoucke Julian Ibarz Vincent Vanhoucke Task Classification of images into 10 different classes: Bedroom Bridge Church
Scene Classification with Inception-7 Christian Szegedy with Julian Ibarz and Vincent Vanhoucke Julian Ibarz Vincent Vanhoucke Task Classification of images into 10 different classes: Bedroom Bridge Church
Hidden Markov Model based dance recognition
 Hidden Markov Model based dance recognition Dragutin Hrenek, Nenad Mikša, Robert Perica, Pavle Prentašić and Boris Trubić University of Zagreb, Faculty of Electrical Engineering and Computing Unska 3,
Hidden Markov Model based dance recognition Dragutin Hrenek, Nenad Mikša, Robert Perica, Pavle Prentašić and Boris Trubić University of Zagreb, Faculty of Electrical Engineering and Computing Unska 3,
APPLICATIONS OF A SEMI-AUTOMATIC MELODY EXTRACTION INTERFACE FOR INDIAN MUSIC
 APPLICATIONS OF A SEMI-AUTOMATIC MELODY EXTRACTION INTERFACE FOR INDIAN MUSIC Vishweshwara Rao, Sachin Pant, Madhumita Bhaskar and Preeti Rao Department of Electrical Engineering, IIT Bombay {vishu, sachinp,
APPLICATIONS OF A SEMI-AUTOMATIC MELODY EXTRACTION INTERFACE FOR INDIAN MUSIC Vishweshwara Rao, Sachin Pant, Madhumita Bhaskar and Preeti Rao Department of Electrical Engineering, IIT Bombay {vishu, sachinp,
2014A Cappella Harmonv Academv Handout #2 Page 1. Sweet Adelines International Balance & Blend Joan Boutilier
 2014A Cappella Harmonv Academv Page 1 The Role of Balance within the Judging Categories Music: Part balance to enable delivery of complete, clear, balanced chords Balance in tempo choice and variation
2014A Cappella Harmonv Academv Page 1 The Role of Balance within the Judging Categories Music: Part balance to enable delivery of complete, clear, balanced chords Balance in tempo choice and variation
Advanced Video Processing for Future Multimedia Communication Systems
 Advanced Video Processing for Future Multimedia Communication Systems André Kaup Friedrich-Alexander University Erlangen-Nürnberg Future Multimedia Communication Systems Trend in video to make communication
Advanced Video Processing for Future Multimedia Communication Systems André Kaup Friedrich-Alexander University Erlangen-Nürnberg Future Multimedia Communication Systems Trend in video to make communication
IMPROVING PREDICTIONS OF DERIVED VIEWPOINTS IN MULTIPLE VIEWPOINT SYSTEMS
 IMPROVING PREDICTIONS OF DERIVED VIEWPOINTS IN MULTIPLE VIEWPOINT SYSTEMS Thomas Hedges Queen Mary University of London t.w.hedges@qmul.ac.uk Geraint Wiggins Queen Mary University of London geraint.wiggins@qmul.ac.uk
IMPROVING PREDICTIONS OF DERIVED VIEWPOINTS IN MULTIPLE VIEWPOINT SYSTEMS Thomas Hedges Queen Mary University of London t.w.hedges@qmul.ac.uk Geraint Wiggins Queen Mary University of London geraint.wiggins@qmul.ac.uk
TOWARD AN INTELLIGENT EDITOR FOR JAZZ MUSIC
 TOWARD AN INTELLIGENT EDITOR FOR JAZZ MUSIC G.TZANETAKIS, N.HU, AND R.B. DANNENBERG Computer Science Department, Carnegie Mellon University 5000 Forbes Avenue, Pittsburgh, PA 15213, USA E-mail: gtzan@cs.cmu.edu
TOWARD AN INTELLIGENT EDITOR FOR JAZZ MUSIC G.TZANETAKIS, N.HU, AND R.B. DANNENBERG Computer Science Department, Carnegie Mellon University 5000 Forbes Avenue, Pittsburgh, PA 15213, USA E-mail: gtzan@cs.cmu.edu
XI. Chord-Scales Via Modal Theory (Part 1)
") XI. Chord-Scales Via Modal Theory (Part 1) A. Terminology And Definitions Scale: A graduated series of musical tones ascending or descending in order of pitch according to a specified scheme of their intervals.
XI. Chord-Scales Via Modal Theory (Part 1) A. Terminology And Definitions Scale: A graduated series of musical tones ascending or descending in order of pitch according to a specified scheme of their intervals.