GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS. Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1)
|
|
|
- Kory Ryan
- 5 years ago
- Views:
Transcription

 and Dan Boneh (1) (1)")

1 GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1) (1) Stanford University (2) National Research and Simulation Center, Rafael Ltd. 0

2

3 MICROPHONE ACCESS REQUIRES PERMISSIONS
4 GYROSCOPE ACCESS DOES NOT REQUIRE PERMISSIONS
5 CORIOLIS FORCE An effect whereby a mass moving in a rotating system experiences a force (Coriolis force) acting perpendicular to the direction of motion and to the axis of rotation. The Coriolis force is fictitious force, like centripetal force. MEMS Gyroscope measures this force to compute the angular velocity.

")
6 MEMS GYROSCOPES Major vendors: STM Microelectronics (Samsung Galaxy) InvenSense (Google Nexus)

7 STMicroelectronics 3-AXIS GYRO DESIGN Driving Frequency: 20KHz Samsung Galaxy, Apple Iphones and Ipads. Dominates market - ~80%

8 InvenSense 3-AXIS GYRO DESIGN Driving Frequency: between 25KHz 30KHz Google Nexus, Galaxy tabs
9 GYROSCOPES ARE SUSCEPTIBLE TO SOUND 70 HZ TONE POWER SPECTRAL DENSITY 50 HZ TONE POWER SPECTRAL DENSITY
10 GYROSCOPES ARE (LOUSY, BUT STILL) MICROPHONES Hardware sampling frequency: InvenSense: up to 8000 Hz STM Microelectronics: 800 Hz Software sampling frequency: Android: 200 Hz ios: 100 Hz
11 GYROSCOPES ARE (LOUSY, BUT STILL) MICROPHONES Very low SNR (Signal-to-Noise Ratio) Acoustic sensitivity threshold: ~70 db Comparable to a loud conversation. Sensitive to sound angle of arrival Directional microphone (due to 3 axes)
12 IS GYROSCOPE DIRECTIONAL? Gyroscope is omni-directional audio sensor. 3 axes --> 3 different sets for 1 reading. Can sense in all directions.
13 BROWSERS ALLOW GYROSCOPE ACCESS TOO
14 BROWSERS ALLOW GYROSCOPE ACCESS TOO

15 BROWSERS ALLOW GYROSCOPE ACCESS TOO

16 BROWSERS ALLOW GYROSCOPE ACCESS TOO
17 PROBLEM: HOW DO WE LOOK INTO HIGHER FREQUENCIES? SPEECH RANGE Adult male Hz Adult female Hz
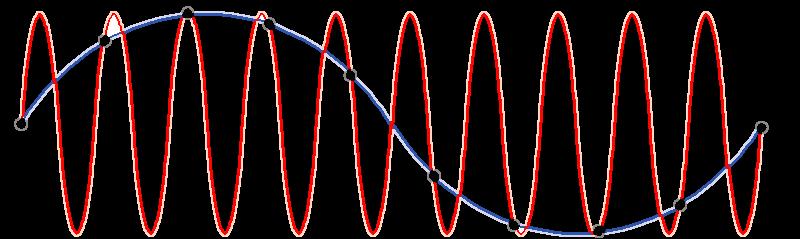
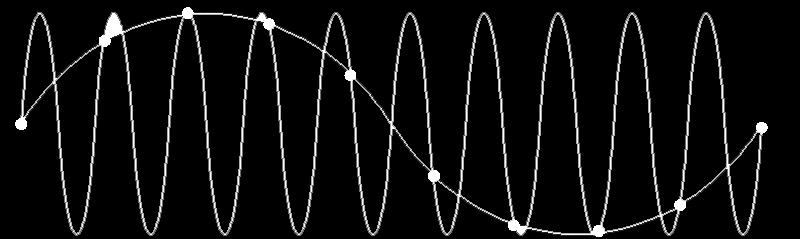
18 ALIASING

19 WE CAN SENSE HIGH FREQUENCY SIGNALS DUE TO ALIASING THE RESULT OF RECORDING TONES BETWEEN 120 AND 160 HZ ON A NEXUS 7 DEVICE

20 FREQUENCIES > SAMPLING FREQUENCY

21 EXPERIMENTAL SETUP Room. Simple speakers. Smartphone. Subset of TIDigits speech recognition corpus 10 speakers 11 samples 2 pronunciations = 220 total samples

22 SPEECH ANALYSIS USING A SINGLE GYROSCOPE Gender identification Speaker identification Isolated word recognition

23 Speech recognition engine developed at CMU Tested for isolated word recognition 14% success rate (random guess is 9%)
24 PREPROCESSING All samples are converted to audio files in WAV format Upsampled to 8 KHz Silence removal (based on voiced/unvoiced segment classification)
25 FEATURES MFCC - Mel-Frequency Cepstral Coefficients Statistical features are used (mean and variance) delta-mfcc Spectral centroid RMS energy STFT - Short-Time Fourier Transform
26 CLASSIFIERS SVM (and Multi-class SVM) GMM (Gaussian Mixture Model) DTW (Dynamic Time Warping)


27 DYNAMIC TIME WARPING EUCLIDEAN DISTANCE DTW DISTANCE
28 GENDER IDENTIFICATION Binary SVM with spectral features DTW with STFT features Window size: 512 samples - corresponds to 64 ms under 8 KHz sampling rate
29 WE CAN SUCCESSFULLY IDENTIFY GENDER NEXUS 4 84% (DTW) GALAXY S III 82% (SVM) Random guess probability is 50%


30 SPEAKER IDENTIFICATION Multi-class SVM and GMM with spectral features DTW with STFT features (same as before)
31 A GOOD CHANCE TO IDENTIFY THE SPEAKER Nexus 4 Mixed Female/Male 50% (DTW) Female speakers 45% (DTW) Male speakers 65% (DTW) Random guess probability is 20% for one gender and 10% for a mixed set
 Confusion matrix corresponds to the mixed set results using DTW Random guess probability is 9%")
32 ISOLATED WORDS RECOGNITION SPEAKER INDEPENDENT Nexus 4 Mixed Female/Male 17% (DTW) Female speakers 26% (DTW) Male speakers 23% (DTW) Confusion matrix corresponds to the mixed set results using DTW Random guess probability is 9%

33 ISOLATED WORDS RECOGNITION SPEAKER DEPENDENT Confusion matrix corresponds to the DTW results Random guess probability is 9%

34 HOW CAN WE LEVERAGE EAVESDROPPING SIMULTANEOUSLY ON TWO DEVICES?
35 SIMILAR TO TIME-INTERLEAVED ADC's
36 SIMILAR TO TIME-INTERLEAVED ADC's DC component removal
37 SIMILAR TO TIME-INTERLEAVED ADC's Normalization / use a reference signal

38 SIMILAR TO TIME-INTERLEAVED ADC's Background or foreground calibration
39 NON-UNIFORM RECONSTRUCTION REQUIRES KNOWING PRECISE TIME-SKEWS Filterbank interpolation based on Eldar and Oppenheim's paper


40 PRACTICAL COMPROMISE Interleaving samples from multiple devices
41 EVALUATION (Tested for the case of speaker dependent word recognition) Single device Two devices Exhibits improvement over using a single device Using even more devices might yield even better results Not a proper non-uniform reconstruction

42 FURTHER ATTACKS
43 SOURCE SEPARATION Use the 3 axes of the gyro Learn the number of sound sources around Use angle of arrival information for source separation
44 AMBIENT SOUND RECOGNITION IS THE USER IN A ROOM/OUTDOORS/ON A STREET?

45 DEFENSES
46 SOFTWARE DEFENSES Low-pass filter the raw samples 0-20 Hz range should be enough for browser based applications (according to WebKit) Access to high sampling rate should require a special permission
47 HARDWARE DEFENSES Hardware filtering of sensor signals (Not subject to configuration) Acoustic masking (won't help against vibration of the surface)
48 CONCLUSION Giving applications direct access to hardware is dangerous. Especially given the high sampling rate.
49 THANK YOU VERY MUCH QUESTIONS? CRYPTO.STANFORD.EDU/GYROPHONE

50 IT IS POSSIBLE TO SAMPLE THROUGH JAVASCRIPT
51 FAQ Did you experiment with an anechoic chamber? Yes, and did not find it beneficial at this stage.
52 FAQ Perhaps the gyro actually measures the vibrations of the surface? Maybe, but tests suggest it's not only that. In any case it is still dangerous.
53 FAQ Is it possible to use measurements from multiple devices in other ways? Yes. For example as in MIMO: EGC (Equal Gain Combining).
Gyrophone: Recognizing Speech from Gyroscope Signals
 Gyrophone: Recognizing Speech from Gyroscope Signals Yan Michalevsky and Dan Boneh, Stanford University; Gabi Nakibly, National Research & Simulation Center, Rafael Ltd. https://www.usenix.org/conference/usenixsecurity14/technical-sessions/presentation/michalevsky
Gyrophone: Recognizing Speech from Gyroscope Signals Yan Michalevsky and Dan Boneh, Stanford University; Gabi Nakibly, National Research & Simulation Center, Rafael Ltd. https://www.usenix.org/conference/usenixsecurity14/technical-sessions/presentation/michalevsky
Gyrophone: Recognizing Speech From Gyroscope Signals
 Gyrophone: Recognizing Speech From Gyroscope Signals Yan Michalevsky Dan Boneh Computer Science Department Stanford University Abstract We show that the MEMS gyroscopes found on modern smart phones are
Gyrophone: Recognizing Speech From Gyroscope Signals Yan Michalevsky Dan Boneh Computer Science Department Stanford University Abstract We show that the MEMS gyroscopes found on modern smart phones are
Features for Audio and Music Classification
 Features for Audio and Music Classification Martin F. McKinney and Jeroen Breebaart Auditory and Multisensory Perception, Digital Signal Processing Group Philips Research Laboratories Eindhoven, The Netherlands
Features for Audio and Music Classification Martin F. McKinney and Jeroen Breebaart Auditory and Multisensory Perception, Digital Signal Processing Group Philips Research Laboratories Eindhoven, The Netherlands
Getting Started with the LabVIEW Sound and Vibration Toolkit
 1 Getting Started with the LabVIEW Sound and Vibration Toolkit This tutorial is designed to introduce you to some of the sound and vibration analysis capabilities in the industry-leading software tool
1 Getting Started with the LabVIEW Sound and Vibration Toolkit This tutorial is designed to introduce you to some of the sound and vibration analysis capabilities in the industry-leading software tool
Voice Controlled Car System
 Voice Controlled Car System 6.111 Project Proposal Ekin Karasan & Driss Hafdi November 3, 2016 1. Overview Voice controlled car systems have been very important in providing the ability to drivers to adjust
Voice Controlled Car System 6.111 Project Proposal Ekin Karasan & Driss Hafdi November 3, 2016 1. Overview Voice controlled car systems have been very important in providing the ability to drivers to adjust
Automatic Laughter Detection
 Automatic Laughter Detection Mary Knox Final Project (EECS 94) knoxm@eecs.berkeley.edu December 1, 006 1 Introduction Laughter is a powerful cue in communication. It communicates to listeners the emotional
Automatic Laughter Detection Mary Knox Final Project (EECS 94) knoxm@eecs.berkeley.edu December 1, 006 1 Introduction Laughter is a powerful cue in communication. It communicates to listeners the emotional
What is the minimum sound pressure level iphone or ipad can measure? What is the maximum sound pressure level iphone or ipad can measure?
 Technical Note 1701 i437l- Frequent Asked Questions Question 1 : What are the advantages of MicW i437l? Answer 1 : The i437l is a digital microphone connected to iphone Lightning connector. It has flat
Technical Note 1701 i437l- Frequent Asked Questions Question 1 : What are the advantages of MicW i437l? Answer 1 : The i437l is a digital microphone connected to iphone Lightning connector. It has flat
Speech and Speaker Recognition for the Command of an Industrial Robot
 Speech and Speaker Recognition for the Command of an Industrial Robot CLAUDIA MOISA*, HELGA SILAGHI*, ANDREI SILAGHI** *Dept. of Electric Drives and Automation University of Oradea University Street, nr.
Speech and Speaker Recognition for the Command of an Industrial Robot CLAUDIA MOISA*, HELGA SILAGHI*, ANDREI SILAGHI** *Dept. of Electric Drives and Automation University of Oradea University Street, nr.
MUSI-6201 Computational Music Analysis
 MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
Figure 1: Feature Vector Sequence Generator block diagram.
 1 Introduction Figure 1: Feature Vector Sequence Generator block diagram. We propose designing a simple isolated word speech recognition system in Verilog. Our design is naturally divided into two modules.
1 Introduction Figure 1: Feature Vector Sequence Generator block diagram. We propose designing a simple isolated word speech recognition system in Verilog. Our design is naturally divided into two modules.
Classification of Timbre Similarity
 Classification of Timbre Similarity Corey Kereliuk McGill University March 15, 2007 1 / 16 1 Definition of Timbre What Timbre is Not What Timbre is A 2-dimensional Timbre Space 2 3 Considerations Common
Classification of Timbre Similarity Corey Kereliuk McGill University March 15, 2007 1 / 16 1 Definition of Timbre What Timbre is Not What Timbre is A 2-dimensional Timbre Space 2 3 Considerations Common
Automatic Laughter Detection
 Automatic Laughter Detection Mary Knox 1803707 knoxm@eecs.berkeley.edu December 1, 006 Abstract We built a system to automatically detect laughter from acoustic features of audio. To implement the system,
Automatic Laughter Detection Mary Knox 1803707 knoxm@eecs.berkeley.edu December 1, 006 Abstract We built a system to automatically detect laughter from acoustic features of audio. To implement the system,
Supervised Learning in Genre Classification
 Supervised Learning in Genre Classification Introduction & Motivation Mohit Rajani and Luke Ekkizogloy {i.mohit,luke.ekkizogloy}@gmail.com Stanford University, CS229: Machine Learning, 2009 Now that music
Supervised Learning in Genre Classification Introduction & Motivation Mohit Rajani and Luke Ekkizogloy {i.mohit,luke.ekkizogloy}@gmail.com Stanford University, CS229: Machine Learning, 2009 Now that music
DETECTING ENVIRONMENTAL NOISE WITH BASIC TOOLS
 DETECTING ENVIRONMENTAL NOISE WITH BASIC TOOLS By Henrik, September 2018, Version 2 Measuring low-frequency components of environmental noise close to the hearing threshold with high accuracy requires
DETECTING ENVIRONMENTAL NOISE WITH BASIC TOOLS By Henrik, September 2018, Version 2 Measuring low-frequency components of environmental noise close to the hearing threshold with high accuracy requires
GCT535- Sound Technology for Multimedia Timbre Analysis. Graduate School of Culture Technology KAIST Juhan Nam
 GCT535- Sound Technology for Multimedia Timbre Analysis Graduate School of Culture Technology KAIST Juhan Nam 1 Outlines Timbre Analysis Definition of Timbre Timbre Features Zero-crossing rate Spectral
GCT535- Sound Technology for Multimedia Timbre Analysis Graduate School of Culture Technology KAIST Juhan Nam 1 Outlines Timbre Analysis Definition of Timbre Timbre Features Zero-crossing rate Spectral
hit), and assume that longer incidental sounds (forest noise, water, wind noise) resemble a Gaussian noise distribution.
, and assume that longer incidental sounds (forest noise, water, wind noise) resemble a Gaussian noise distribution.") CS 229 FINAL PROJECT A SOUNDHOUND FOR THE SOUNDS OF HOUNDS WEAKLY SUPERVISED MODELING OF ANIMAL SOUNDS ROBERT COLCORD, ETHAN GELLER, MATTHEW HORTON Abstract: We propose a hybrid approach to generating
CS 229 FINAL PROJECT A SOUNDHOUND FOR THE SOUNDS OF HOUNDS WEAKLY SUPERVISED MODELING OF ANIMAL SOUNDS ROBERT COLCORD, ETHAN GELLER, MATTHEW HORTON Abstract: We propose a hybrid approach to generating
INTER GENRE SIMILARITY MODELLING FOR AUTOMATIC MUSIC GENRE CLASSIFICATION
 INTER GENRE SIMILARITY MODELLING FOR AUTOMATIC MUSIC GENRE CLASSIFICATION ULAŞ BAĞCI AND ENGIN ERZIN arxiv:0907.3220v1 [cs.sd] 18 Jul 2009 ABSTRACT. Music genre classification is an essential tool for
INTER GENRE SIMILARITY MODELLING FOR AUTOMATIC MUSIC GENRE CLASSIFICATION ULAŞ BAĞCI AND ENGIN ERZIN arxiv:0907.3220v1 [cs.sd] 18 Jul 2009 ABSTRACT. Music genre classification is an essential tool for
Music Genre Classification and Variance Comparison on Number of Genres
 Music Genre Classification and Variance Comparison on Number of Genres Miguel Francisco, miguelf@stanford.edu Dong Myung Kim, dmk8265@stanford.edu 1 Abstract In this project we apply machine learning techniques
Music Genre Classification and Variance Comparison on Number of Genres Miguel Francisco, miguelf@stanford.edu Dong Myung Kim, dmk8265@stanford.edu 1 Abstract In this project we apply machine learning techniques
Application Of Missing Feature Theory To The Recognition Of Musical Instruments In Polyphonic Audio
 Application Of Missing Feature Theory To The Recognition Of Musical Instruments In Polyphonic Audio Jana Eggink and Guy J. Brown Department of Computer Science, University of Sheffield Regent Court, 11
Application Of Missing Feature Theory To The Recognition Of Musical Instruments In Polyphonic Audio Jana Eggink and Guy J. Brown Department of Computer Science, University of Sheffield Regent Court, 11
Improving Frame Based Automatic Laughter Detection
 Improving Frame Based Automatic Laughter Detection Mary Knox EE225D Class Project knoxm@eecs.berkeley.edu December 13, 2007 Abstract Laughter recognition is an underexplored area of research. My goal for
Improving Frame Based Automatic Laughter Detection Mary Knox EE225D Class Project knoxm@eecs.berkeley.edu December 13, 2007 Abstract Laughter recognition is an underexplored area of research. My goal for
CS229 Project Report Polyphonic Piano Transcription
 CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
On Human Capability and Acoustic Cues for Discriminating Singing and Speaking Voices
 On Human Capability and Acoustic Cues for Discriminating Singing and Speaking Voices Yasunori Ohishi 1 Masataka Goto 3 Katunobu Itou 2 Kazuya Takeda 1 1 Graduate School of Information Science, Nagoya University,
On Human Capability and Acoustic Cues for Discriminating Singing and Speaking Voices Yasunori Ohishi 1 Masataka Goto 3 Katunobu Itou 2 Kazuya Takeda 1 1 Graduate School of Information Science, Nagoya University,
Perceptual dimensions of short audio clips and corresponding timbre features
 Perceptual dimensions of short audio clips and corresponding timbre features Jason Musil, Budr El-Nusairi, Daniel Müllensiefen Department of Psychology, Goldsmiths, University of London Question How do
Perceptual dimensions of short audio clips and corresponding timbre features Jason Musil, Budr El-Nusairi, Daniel Müllensiefen Department of Psychology, Goldsmiths, University of London Question How do
A fragment-decoding plus missing-data imputation ASR system evaluated on the 2nd CHiME Challenge
 A fragment-decoding plus missing-data imputation ASR system evaluated on the 2nd CHiME Challenge Ning Ma MRC Institute of Hearing Research, Nottingham, NG7 2RD, UK n.ma@ihr.mrc.ac.uk Jon Barker Department
A fragment-decoding plus missing-data imputation ASR system evaluated on the 2nd CHiME Challenge Ning Ma MRC Institute of Hearing Research, Nottingham, NG7 2RD, UK n.ma@ihr.mrc.ac.uk Jon Barker Department
Computational Models of Music Similarity. Elias Pampalk National Institute for Advanced Industrial Science and Technology (AIST)
") Computational Models of Music Similarity 1 Elias Pampalk National Institute for Advanced Industrial Science and Technology (AIST) Abstract The perceived similarity of two pieces of music is multi-dimensional,
Computational Models of Music Similarity 1 Elias Pampalk National Institute for Advanced Industrial Science and Technology (AIST) Abstract The perceived similarity of two pieces of music is multi-dimensional,
19 th INTERNATIONAL CONGRESS ON ACOUSTICS MADRID, 2-7 SEPTEMBER 2007
 19 th INTERNATIONAL CONGRESS ON ACOUSTICS MADRID, 2-7 SEPTEMBER 2007 AN HMM BASED INVESTIGATION OF DIFFERENCES BETWEEN MUSICAL INSTRUMENTS OF THE SAME TYPE PACS: 43.75.-z Eichner, Matthias; Wolff, Matthias;
19 th INTERNATIONAL CONGRESS ON ACOUSTICS MADRID, 2-7 SEPTEMBER 2007 AN HMM BASED INVESTIGATION OF DIFFERENCES BETWEEN MUSICAL INSTRUMENTS OF THE SAME TYPE PACS: 43.75.-z Eichner, Matthias; Wolff, Matthias;
HomeLog: A Smart System for Unobtrusive Family Routine Monitoring
 HomeLog: A Smart System for Unobtrusive Family Routine Monitoring Abstract Research has shown that family routine plays a critical role in establishing good relationships among family members and maintaining
HomeLog: A Smart System for Unobtrusive Family Routine Monitoring Abstract Research has shown that family routine plays a critical role in establishing good relationships among family members and maintaining
An Ultra-low noise MEMS accelerometer for Seismology
 QuietSeis TM An Ultra-low noise MEMS accelerometer for Seismology aurelien.fougerat@sercel.com laurent.guerineau@sercel.com April 10 th, 2018 SERCEL Introduction French company founded in 1956, subsidiary
QuietSeis TM An Ultra-low noise MEMS accelerometer for Seismology aurelien.fougerat@sercel.com laurent.guerineau@sercel.com April 10 th, 2018 SERCEL Introduction French company founded in 1956, subsidiary
What s New in Raven May 2006 This document briefly summarizes the new features that have been added to Raven since the release of Raven
 What s New in Raven 1.3 16 May 2006 This document briefly summarizes the new features that have been added to Raven since the release of Raven 1.2.1. Extensible multi-channel audio input device support
What s New in Raven 1.3 16 May 2006 This document briefly summarizes the new features that have been added to Raven since the release of Raven 1.2.1. Extensible multi-channel audio input device support
Comparison Parameters and Speaker Similarity Coincidence Criteria:
 Comparison Parameters and Speaker Similarity Coincidence Criteria: The Easy Voice system uses two interrelating parameters of comparison (first and second error types). False Rejection, FR is a probability
Comparison Parameters and Speaker Similarity Coincidence Criteria: The Easy Voice system uses two interrelating parameters of comparison (first and second error types). False Rejection, FR is a probability
Automatic Rhythmic Notation from Single Voice Audio Sources
 Automatic Rhythmic Notation from Single Voice Audio Sources Jack O Reilly, Shashwat Udit Introduction In this project we used machine learning technique to make estimations of rhythmic notation of a sung
Automatic Rhythmic Notation from Single Voice Audio Sources Jack O Reilly, Shashwat Udit Introduction In this project we used machine learning technique to make estimations of rhythmic notation of a sung
Efficient Computer-Aided Pitch Track and Note Estimation for Scientific Applications. Matthias Mauch Chris Cannam György Fazekas
 Efficient Computer-Aided Pitch Track and Note Estimation for Scientific Applications Matthias Mauch Chris Cannam György Fazekas! 1 Matthias Mauch, Chris Cannam, George Fazekas Problem Intonation in Unaccompanied
Efficient Computer-Aided Pitch Track and Note Estimation for Scientific Applications Matthias Mauch Chris Cannam György Fazekas! 1 Matthias Mauch, Chris Cannam, George Fazekas Problem Intonation in Unaccompanied
Major Differences Between the DT9847 Series Modules
 DT9847 Series Dynamic Signal Analyzer for USB With Low THD and Wide Dynamic Range The DT9847 Series are high-accuracy, dynamic signal acquisition modules designed for sound and vibration applications.
DT9847 Series Dynamic Signal Analyzer for USB With Low THD and Wide Dynamic Range The DT9847 Series are high-accuracy, dynamic signal acquisition modules designed for sound and vibration applications.
THE importance of music content analysis for musical
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 1, JANUARY 2007 333 Drum Sound Recognition for Polyphonic Audio Signals by Adaptation and Matching of Spectrogram Templates With
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 1, JANUARY 2007 333 Drum Sound Recognition for Polyphonic Audio Signals by Adaptation and Matching of Spectrogram Templates With
Digital Signal. Continuous. Continuous. amplitude. amplitude. Discrete-time Signal. Analog Signal. Discrete. Continuous. time. time.
 Discrete amplitude Continuous amplitude Continuous amplitude Digital Signal Analog Signal Discrete-time Signal Continuous time Discrete time Digital Signal Discrete time 1 Digital Signal contd. Analog
Discrete amplitude Continuous amplitude Continuous amplitude Digital Signal Analog Signal Discrete-time Signal Continuous time Discrete time Digital Signal Discrete time 1 Digital Signal contd. Analog
Classification of Musical Instruments sounds by Using MFCC and Timbral Audio Descriptors
 Classification of Musical Instruments sounds by Using MFCC and Timbral Audio Descriptors Priyanka S. Jadhav M.E. (Computer Engineering) G. H. Raisoni College of Engg. & Mgmt. Wagholi, Pune, India E-mail:
Classification of Musical Instruments sounds by Using MFCC and Timbral Audio Descriptors Priyanka S. Jadhav M.E. (Computer Engineering) G. H. Raisoni College of Engg. & Mgmt. Wagholi, Pune, India E-mail:
DT9857E. Key Features: Dynamic Signal Analyzer for Sound and Vibration Analysis Expandable to 64 Channels
 DT9857E Dynamic Signal Analyzer for Sound and Vibration Analysis Expandable to 64 Channels The DT9857E is a high accuracy dynamic signal acquisition module for noise, vibration, and acoustic measurements
DT9857E Dynamic Signal Analyzer for Sound and Vibration Analysis Expandable to 64 Channels The DT9857E is a high accuracy dynamic signal acquisition module for noise, vibration, and acoustic measurements
MIE 402: WORKSHOP ON DATA ACQUISITION AND SIGNAL PROCESSING Spring 2003
 MIE 402: WORKSHOP ON DATA ACQUISITION AND SIGNAL PROCESSING Spring 2003 OBJECTIVE To become familiar with state-of-the-art digital data acquisition hardware and software. To explore common data acquisition
MIE 402: WORKSHOP ON DATA ACQUISITION AND SIGNAL PROCESSING Spring 2003 OBJECTIVE To become familiar with state-of-the-art digital data acquisition hardware and software. To explore common data acquisition
A NOVEL CEPSTRAL REPRESENTATION FOR TIMBRE MODELING OF SOUND SOURCES IN POLYPHONIC MIXTURES
 A NOVEL CEPSTRAL REPRESENTATION FOR TIMBRE MODELING OF SOUND SOURCES IN POLYPHONIC MIXTURES Zhiyao Duan 1, Bryan Pardo 2, Laurent Daudet 3 1 Department of Electrical and Computer Engineering, University
A NOVEL CEPSTRAL REPRESENTATION FOR TIMBRE MODELING OF SOUND SOURCES IN POLYPHONIC MIXTURES Zhiyao Duan 1, Bryan Pardo 2, Laurent Daudet 3 1 Department of Electrical and Computer Engineering, University
inter.noise 2000 The 29th International Congress and Exhibition on Noise Control Engineering August 2000, Nice, FRANCE
 Copyright SFA - InterNoise 2000 1 inter.noise 2000 The 29th International Congress and Exhibition on Noise Control Engineering 27-30 August 2000, Nice, FRANCE I-INCE Classification: 5.3 ACTIVE NOISE CONTROL
Copyright SFA - InterNoise 2000 1 inter.noise 2000 The 29th International Congress and Exhibition on Noise Control Engineering 27-30 August 2000, Nice, FRANCE I-INCE Classification: 5.3 ACTIVE NOISE CONTROL
Experiments on tone adjustments
 Experiments on tone adjustments Jesko L. VERHEY 1 ; Jan HOTS 2 1 University of Magdeburg, Germany ABSTRACT Many technical sounds contain tonal components originating from rotating parts, such as electric
Experiments on tone adjustments Jesko L. VERHEY 1 ; Jan HOTS 2 1 University of Magdeburg, Germany ABSTRACT Many technical sounds contain tonal components originating from rotating parts, such as electric
International Journal of Advance Engineering and Research Development MUSICAL INSTRUMENT IDENTIFICATION AND STATUS FINDING WITH MFCC
 Scientific Journal of Impact Factor (SJIF): 5.71 International Journal of Advance Engineering and Research Development Volume 5, Issue 04, April -2018 e-issn (O): 2348-4470 p-issn (P): 2348-6406 MUSICAL
Scientific Journal of Impact Factor (SJIF): 5.71 International Journal of Advance Engineering and Research Development Volume 5, Issue 04, April -2018 e-issn (O): 2348-4470 p-issn (P): 2348-6406 MUSICAL
Automatic LP Digitalization Spring Group 6: Michael Sibley, Alexander Su, Daphne Tsatsoulis {msibley, ahs1,
 Automatic LP Digitalization 18-551 Spring 2011 Group 6: Michael Sibley, Alexander Su, Daphne Tsatsoulis {msibley, ahs1, ptsatsou}@andrew.cmu.edu Introduction This project was originated from our interest
Automatic LP Digitalization 18-551 Spring 2011 Group 6: Michael Sibley, Alexander Su, Daphne Tsatsoulis {msibley, ahs1, ptsatsou}@andrew.cmu.edu Introduction This project was originated from our interest
Hidden melody in music playing motion: Music recording using optical motion tracking system
 PROCEEDINGS of the 22 nd International Congress on Acoustics General Musical Acoustics: Paper ICA2016-692 Hidden melody in music playing motion: Music recording using optical motion tracking system Min-Ho
PROCEEDINGS of the 22 nd International Congress on Acoustics General Musical Acoustics: Paper ICA2016-692 Hidden melody in music playing motion: Music recording using optical motion tracking system Min-Ho
idrims Resampler After resampling idrims Resampler provides a functionality to resample measurement data. The data is 2016/08/21 Tomonori Nagayama
 idrims Resampler Overview: Smartphones equipped with MEMS devices allow easy acquisition of physical quantities, such as acceleration and angular velocities, at a cost way much lower than conventional
idrims Resampler Overview: Smartphones equipped with MEMS devices allow easy acquisition of physical quantities, such as acceleration and angular velocities, at a cost way much lower than conventional
Signal Processing. Case Study - 3. It s Too Loud. Hardware. Sound Levels
 Case Study - 3 Signal Processing Lisa Simpson: Would you guys turn that down! Homer Simpson: Sweetie, if we didn't turn it down for the cops, what chance do you have? "The Simpsons" Little Big Mom (2000)
Case Study - 3 Signal Processing Lisa Simpson: Would you guys turn that down! Homer Simpson: Sweetie, if we didn't turn it down for the cops, what chance do you have? "The Simpsons" Little Big Mom (2000)
MUSICAL INSTRUMENT IDENTIFICATION BASED ON HARMONIC TEMPORAL TIMBRE FEATURES
 MUSICAL INSTRUMENT IDENTIFICATION BASED ON HARMONIC TEMPORAL TIMBRE FEATURES Jun Wu, Yu Kitano, Stanislaw Andrzej Raczynski, Shigeki Miyabe, Takuya Nishimoto, Nobutaka Ono and Shigeki Sagayama The Graduate
MUSICAL INSTRUMENT IDENTIFICATION BASED ON HARMONIC TEMPORAL TIMBRE FEATURES Jun Wu, Yu Kitano, Stanislaw Andrzej Raczynski, Shigeki Miyabe, Takuya Nishimoto, Nobutaka Ono and Shigeki Sagayama The Graduate
Automatic Identification of Instrument Type in Music Signal using Wavelet and MFCC
 Automatic Identification of Instrument Type in Music Signal using Wavelet and MFCC Arijit Ghosal, Rudrasis Chakraborty, Bibhas Chandra Dhara +, and Sanjoy Kumar Saha! * CSE Dept., Institute of Technology
Automatic Identification of Instrument Type in Music Signal using Wavelet and MFCC Arijit Ghosal, Rudrasis Chakraborty, Bibhas Chandra Dhara +, and Sanjoy Kumar Saha! * CSE Dept., Institute of Technology
An Introduction to the Spectral Dynamics Rotating Machinery Analysis (RMA) package For PUMA and COUGAR
 package For PUMA and COUGAR") An Introduction to the Spectral Dynamics Rotating Machinery Analysis (RMA) package For PUMA and COUGAR Introduction: The RMA package is a PC-based system which operates with PUMA and COUGAR hardware to
An Introduction to the Spectral Dynamics Rotating Machinery Analysis (RMA) package For PUMA and COUGAR Introduction: The RMA package is a PC-based system which operates with PUMA and COUGAR hardware to
Results of Vibration Study for LCLS-II Construction in FEE, Hutch 3 LODCM and M3H 1
 LCLS-TN-12-4 Results of Vibration Study for LCLS-II Construction in FEE, Hutch 3 LODCM and M3H 1 Georg Gassner SLAC August 30, 2012 Abstract To study the influence of LCLS-II construction on the stability
LCLS-TN-12-4 Results of Vibration Study for LCLS-II Construction in FEE, Hutch 3 LODCM and M3H 1 Georg Gassner SLAC August 30, 2012 Abstract To study the influence of LCLS-II construction on the stability
Adaptive Resampling - Transforming From the Time to the Angle Domain
 Adaptive Resampling - Transforming From the Time to the Angle Domain Jason R. Blough, Ph.D. Assistant Professor Mechanical Engineering-Engineering Mechanics Department Michigan Technological University
Adaptive Resampling - Transforming From the Time to the Angle Domain Jason R. Blough, Ph.D. Assistant Professor Mechanical Engineering-Engineering Mechanics Department Michigan Technological University
Recognising Cello Performers using Timbre Models
 Recognising Cello Performers using Timbre Models Chudy, Magdalena; Dixon, Simon For additional information about this publication click this link. http://qmro.qmul.ac.uk/jspui/handle/123456789/5013 Information
Recognising Cello Performers using Timbre Models Chudy, Magdalena; Dixon, Simon For additional information about this publication click this link. http://qmro.qmul.ac.uk/jspui/handle/123456789/5013 Information
BEAMAGE 3.0 KEY FEATURES BEAM DIAGNOSTICS PRELIMINARY AVAILABLE MODEL MAIN FUNCTIONS. CMOS Beam Profiling Camera
 PRELIMINARY POWER DETECTORS ENERGY DETECTORS MONITORS SPECIAL PRODUCTS OEM DETECTORS THZ DETECTORS PHOTO DETECTORS HIGH POWER DETECTORS CMOS Beam Profiling Camera AVAILABLE MODEL Beamage 3.0 (⅔ in CMOS
PRELIMINARY POWER DETECTORS ENERGY DETECTORS MONITORS SPECIAL PRODUCTS OEM DETECTORS THZ DETECTORS PHOTO DETECTORS HIGH POWER DETECTORS CMOS Beam Profiling Camera AVAILABLE MODEL Beamage 3.0 (⅔ in CMOS
Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn
 Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn Introduction Active neurons communicate by action potential firing (spikes), accompanied
Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn Introduction Active neurons communicate by action potential firing (spikes), accompanied
A Music Retrieval System Using Melody and Lyric
 202 IEEE International Conference on Multimedia and Expo Workshops A Music Retrieval System Using Melody and Lyric Zhiyuan Guo, Qiang Wang, Gang Liu, Jun Guo, Yueming Lu 2 Pattern Recognition and Intelligent
202 IEEE International Conference on Multimedia and Expo Workshops A Music Retrieval System Using Melody and Lyric Zhiyuan Guo, Qiang Wang, Gang Liu, Jun Guo, Yueming Lu 2 Pattern Recognition and Intelligent
Effects of acoustic degradations on cover song recognition
 Signal Processing in Acoustics: Paper 68 Effects of acoustic degradations on cover song recognition Julien Osmalskyj (a), Jean-Jacques Embrechts (b) (a) University of Liège, Belgium, josmalsky@ulg.ac.be
Signal Processing in Acoustics: Paper 68 Effects of acoustic degradations on cover song recognition Julien Osmalskyj (a), Jean-Jacques Embrechts (b) (a) University of Liège, Belgium, josmalsky@ulg.ac.be
Recognising Cello Performers Using Timbre Models
 Recognising Cello Performers Using Timbre Models Magdalena Chudy and Simon Dixon Abstract In this paper, we compare timbre features of various cello performers playing the same instrument in solo cello
Recognising Cello Performers Using Timbre Models Magdalena Chudy and Simon Dixon Abstract In this paper, we compare timbre features of various cello performers playing the same instrument in solo cello
Chapter 1. Introduction to Digital Signal Processing
 Chapter 1 Introduction to Digital Signal Processing 1. Introduction Signal processing is a discipline concerned with the acquisition, representation, manipulation, and transformation of signals required
Chapter 1 Introduction to Digital Signal Processing 1. Introduction Signal processing is a discipline concerned with the acquisition, representation, manipulation, and transformation of signals required
ISSN ICIRET-2014
 Robust Multilingual Voice Biometrics using Optimum Frames Kala A 1, Anu Infancia J 2, Pradeepa Natarajan 3 1,2 PG Scholar, SNS College of Technology, Coimbatore-641035, India 3 Assistant Professor, SNS
Robust Multilingual Voice Biometrics using Optimum Frames Kala A 1, Anu Infancia J 2, Pradeepa Natarajan 3 1,2 PG Scholar, SNS College of Technology, Coimbatore-641035, India 3 Assistant Professor, SNS
Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models
 Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models Aric Bartle (abartle@stanford.edu) December 14, 2012 1 Background The field of composer recognition has
Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models Aric Bartle (abartle@stanford.edu) December 14, 2012 1 Background The field of composer recognition has
Benefits of the R&S RTO Oscilloscope's Digital Trigger. <Application Note> Products: R&S RTO Digital Oscilloscope
 Benefits of the R&S RTO Oscilloscope's Digital Trigger Application Note Products: R&S RTO Digital Oscilloscope The trigger is a key element of an oscilloscope. It captures specific signal events for detailed
Benefits of the R&S RTO Oscilloscope's Digital Trigger Application Note Products: R&S RTO Digital Oscilloscope The trigger is a key element of an oscilloscope. It captures specific signal events for detailed
Generating the Noise Field for Ambient Noise Rejection Tests Application Note
 Generating the Noise Field for Ambient Noise Rejection Tests Application Note Products: R&S UPV R&S UPV-K9 R&S UPV-K91 This document describes how to generate the noise field for ambient noise rejection
Generating the Noise Field for Ambient Noise Rejection Tests Application Note Products: R&S UPV R&S UPV-K9 R&S UPV-K91 This document describes how to generate the noise field for ambient noise rejection
SCM820 Digital IntelliMix Automatic Mixer SEAMLESS MIXING. ADVANCED CONTROL.
 SCM820 Digital IntelliMix Automatic Mixer SEAMLESS MIXING. ADVANCED CONTROL. SCM820 Digital IntelliMix Automatic Mixer The SCM820 is the flagship Shure digital automatic mixer for seamless, natural-sounding
SCM820 Digital IntelliMix Automatic Mixer SEAMLESS MIXING. ADVANCED CONTROL. SCM820 Digital IntelliMix Automatic Mixer The SCM820 is the flagship Shure digital automatic mixer for seamless, natural-sounding
Sensor Development for the imote2 Smart Sensor Platform
 Sensor Development for the imote2 Smart Sensor Platform March 7, 2008 2008 Introduction Aging infrastructure requires cost effective and timely inspection and maintenance practices The condition of a structure
Sensor Development for the imote2 Smart Sensor Platform March 7, 2008 2008 Introduction Aging infrastructure requires cost effective and timely inspection and maintenance practices The condition of a structure
Music Information Retrieval for Jazz
 Music Information Retrieval for Jazz Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,thierry}@ee.columbia.edu http://labrosa.ee.columbia.edu/
Music Information Retrieval for Jazz Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,thierry}@ee.columbia.edu http://labrosa.ee.columbia.edu/
Narrative Theme Navigation for Sitcoms Supported by Fan-generated Scripts
 Narrative Theme Navigation for Sitcoms Supported by Fan-generated Scripts Gerald Friedland, Luke Gottlieb, Adam Janin International Computer Science Institute (ICSI) Presented by: Katya Gonina What? Novel
Narrative Theme Navigation for Sitcoms Supported by Fan-generated Scripts Gerald Friedland, Luke Gottlieb, Adam Janin International Computer Science Institute (ICSI) Presented by: Katya Gonina What? Novel
Singer Identification
 Singer Identification Bertrand SCHERRER McGill University March 15, 2007 Bertrand SCHERRER (McGill University) Singer Identification March 15, 2007 1 / 27 Outline 1 Introduction Applications Challenges
Singer Identification Bertrand SCHERRER McGill University March 15, 2007 Bertrand SCHERRER (McGill University) Singer Identification March 15, 2007 1 / 27 Outline 1 Introduction Applications Challenges
Data Converter Overview: DACs and ADCs. Dr. Paul Hasler and Dr. Philip Allen
 Data Converter Overview: DACs and ADCs Dr. Paul Hasler and Dr. Philip Allen The need for Data Converters ANALOG SIGNAL (Speech, Images, Sensors, Radar, etc.) PRE-PROCESSING (Filtering and analog to digital
Data Converter Overview: DACs and ADCs Dr. Paul Hasler and Dr. Philip Allen The need for Data Converters ANALOG SIGNAL (Speech, Images, Sensors, Radar, etc.) PRE-PROCESSING (Filtering and analog to digital
DESIGNING OPTIMIZED MICROPHONE BEAMFORMERS
 3235 Kifer Rd. Suite 100 Santa Clara, CA 95051 www.dspconcepts.com DESIGNING OPTIMIZED MICROPHONE BEAMFORMERS Our previous paper, Fundamentals of Voice UI, explained the algorithms and processes required
3235 Kifer Rd. Suite 100 Santa Clara, CA 95051 www.dspconcepts.com DESIGNING OPTIMIZED MICROPHONE BEAMFORMERS Our previous paper, Fundamentals of Voice UI, explained the algorithms and processes required
UNDERSTANDING the timbre of musical instruments has
 68 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 1, JANUARY 2006 Instrument Recognition in Polyphonic Music Based on Automatic Taxonomies Slim Essid, Gaël Richard, Member, IEEE,
68 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 1, JANUARY 2006 Instrument Recognition in Polyphonic Music Based on Automatic Taxonomies Slim Essid, Gaël Richard, Member, IEEE,
Musical instrument identification in continuous recordings
 Musical instrument identification in continuous recordings Arie Livshin, Xavier Rodet To cite this version: Arie Livshin, Xavier Rodet. Musical instrument identification in continuous recordings. Digital
Musical instrument identification in continuous recordings Arie Livshin, Xavier Rodet To cite this version: Arie Livshin, Xavier Rodet. Musical instrument identification in continuous recordings. Digital
REpeating Pattern Extraction Technique (REPET): A Simple Method for Music/Voice Separation
: A Simple Method for Music/Voice Separation") IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 1, JANUARY 2013 73 REpeating Pattern Extraction Technique (REPET): A Simple Method for Music/Voice Separation Zafar Rafii, Student
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 1, JANUARY 2013 73 REpeating Pattern Extraction Technique (REPET): A Simple Method for Music/Voice Separation Zafar Rafii, Student
A CLASSIFICATION APPROACH TO MELODY TRANSCRIPTION
 A CLASSIFICATION APPROACH TO MELODY TRANSCRIPTION Graham E. Poliner and Daniel P.W. Ellis LabROSA, Dept. of Electrical Engineering Columbia University, New York NY 127 USA {graham,dpwe}@ee.columbia.edu
A CLASSIFICATION APPROACH TO MELODY TRANSCRIPTION Graham E. Poliner and Daniel P.W. Ellis LabROSA, Dept. of Electrical Engineering Columbia University, New York NY 127 USA {graham,dpwe}@ee.columbia.edu
Lecture 15: Research at LabROSA
 ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 15: Research at LabROSA 1. Sources, Mixtures, & Perception 2. Spatial Filtering 3. Time-Frequency Masking 4. Model-Based Separation Dan Ellis Dept. Electrical
ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 15: Research at LabROSA 1. Sources, Mixtures, & Perception 2. Spatial Filtering 3. Time-Frequency Masking 4. Model-Based Separation Dan Ellis Dept. Electrical
Blind Identification of Source Mobile Devices Using VoIP Calls
 Blind Identification of Source Mobile Devices Using VoIP Calls Mehdi Jahanirad 1, Ainuddin Wahid Abdul Wahab, Nor Badrul Anuar, Mohd Yamani Idna Idris, and Mohamad Nizam Ayub Faculty of Computer Science
Blind Identification of Source Mobile Devices Using VoIP Calls Mehdi Jahanirad 1, Ainuddin Wahid Abdul Wahab, Nor Badrul Anuar, Mohd Yamani Idna Idris, and Mohamad Nizam Ayub Faculty of Computer Science
Audio-Based Video Editing with Two-Channel Microphone
 Audio-Based Video Editing with Two-Channel Microphone Tetsuya Takiguchi Organization of Advanced Science and Technology Kobe University, Japan takigu@kobe-u.ac.jp Yasuo Ariki Organization of Advanced Science
Audio-Based Video Editing with Two-Channel Microphone Tetsuya Takiguchi Organization of Advanced Science and Technology Kobe University, Japan takigu@kobe-u.ac.jp Yasuo Ariki Organization of Advanced Science
SOFTWARE INSTRUCTIONS REAL-TIME STEERING ARRAY MICROPHONES AM-1B AM-1W
 SOFTWARE INSTRUCTIONS REAL-TIME STEERING ARRAY MICROPHONES AM-1B AM-1W Thank you for purchasing TOA s Real-Time Steering Array Microphone. Please carefully follow the instructions in this manual to ensure
SOFTWARE INSTRUCTIONS REAL-TIME STEERING ARRAY MICROPHONES AM-1B AM-1W Thank you for purchasing TOA s Real-Time Steering Array Microphone. Please carefully follow the instructions in this manual to ensure
WE ADDRESS the development of a novel computational
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 18, NO. 3, MARCH 2010 663 Dynamic Spectral Envelope Modeling for Timbre Analysis of Musical Instrument Sounds Juan José Burred, Member,
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 18, NO. 3, MARCH 2010 663 Dynamic Spectral Envelope Modeling for Timbre Analysis of Musical Instrument Sounds Juan José Burred, Member,
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes
 Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
An ecological approach to multimodal subjective music similarity perception
 An ecological approach to multimodal subjective music similarity perception Stephan Baumann German Research Center for AI, Germany www.dfki.uni-kl.de/~baumann John Halloran Interact Lab, Department of
An ecological approach to multimodal subjective music similarity perception Stephan Baumann German Research Center for AI, Germany www.dfki.uni-kl.de/~baumann John Halloran Interact Lab, Department of
Music Mood Classification - an SVM based approach. Sebastian Napiorkowski
 Music Mood Classification - an SVM based approach Sebastian Napiorkowski Topics on Computer Music (Seminar Report) HPAC - RWTH - SS2015 Contents 1. Motivation 2. Quantification and Definition of Mood 3.
Music Mood Classification - an SVM based approach Sebastian Napiorkowski Topics on Computer Music (Seminar Report) HPAC - RWTH - SS2015 Contents 1. Motivation 2. Quantification and Definition of Mood 3.
DT9837 Series. High Performance, USB Powered Modules for Sound & Vibration Analysis. Key Features:
 DT9837 Series High Performance, Powered Modules for Sound & Vibration Analysis The DT9837 Series high accuracy dynamic signal acquisition modules are ideal for portable noise, vibration, and acoustic measurements.
DT9837 Series High Performance, Powered Modules for Sound & Vibration Analysis The DT9837 Series high accuracy dynamic signal acquisition modules are ideal for portable noise, vibration, and acoustic measurements.
Dithering in Analog-to-digital Conversion
 Application Note 1. Introduction 2. What is Dither High-speed ADCs today offer higher dynamic performances and every effort is made to push these state-of-the art performances through design improvements
Application Note 1. Introduction 2. What is Dither High-speed ADCs today offer higher dynamic performances and every effort is made to push these state-of-the art performances through design improvements
Automatic Music Similarity Assessment and Recommendation. A Thesis. Submitted to the Faculty. Drexel University. Donald Shaul Williamson
 Automatic Music Similarity Assessment and Recommendation A Thesis Submitted to the Faculty of Drexel University by Donald Shaul Williamson in partial fulfillment of the requirements for the degree of Master
Automatic Music Similarity Assessment and Recommendation A Thesis Submitted to the Faculty of Drexel University by Donald Shaul Williamson in partial fulfillment of the requirements for the degree of Master
MUSICAL INSTRUMENT RECOGNITION USING BIOLOGICALLY INSPIRED FILTERING OF TEMPORAL DICTIONARY ATOMS
 MUSICAL INSTRUMENT RECOGNITION USING BIOLOGICALLY INSPIRED FILTERING OF TEMPORAL DICTIONARY ATOMS Steven K. Tjoa and K. J. Ray Liu Signals and Information Group, Department of Electrical and Computer Engineering
MUSICAL INSTRUMENT RECOGNITION USING BIOLOGICALLY INSPIRED FILTERING OF TEMPORAL DICTIONARY ATOMS Steven K. Tjoa and K. J. Ray Liu Signals and Information Group, Department of Electrical and Computer Engineering
Entwicklungen der Mikrosystemtechnik. in Chemnitz
 Entwicklungen der Mikrosystemtechnik Gliederung: in Chemnitz Fraunhofer Institut für f r Zuverlässigkeit und Mikrointegration IZM Institutsteil Multi Device Integration, Chemnitz, Thomas Gessner jan.mehner@che.izm.fhg.de
Entwicklungen der Mikrosystemtechnik Gliederung: in Chemnitz Fraunhofer Institut für f r Zuverlässigkeit und Mikrointegration IZM Institutsteil Multi Device Integration, Chemnitz, Thomas Gessner jan.mehner@che.izm.fhg.de
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Psychological and Physiological Acoustics Session 4aPPb: Binaural Hearing
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Psychological and Physiological Acoustics Session 4aPPb: Binaural Hearing
A System for Automatic Chord Transcription from Audio Using Genre-Specific Hidden Markov Models
 A System for Automatic Chord Transcription from Audio Using Genre-Specific Hidden Markov Models Kyogu Lee Center for Computer Research in Music and Acoustics Stanford University, Stanford CA 94305, USA
A System for Automatic Chord Transcription from Audio Using Genre-Specific Hidden Markov Models Kyogu Lee Center for Computer Research in Music and Acoustics Stanford University, Stanford CA 94305, USA
Haptic, Acoustic, and Visual Short Range Communication on Smartphones
 Distributed Computing Haptic, Acoustic, and Visual Short Range Communication on Smartphones Distributed Systems Lab Marcel Bertsch, Roland Meyer bertschm@student.ethz.ch, romeyer@student.ethz.ch Distributed
Distributed Computing Haptic, Acoustic, and Visual Short Range Communication on Smartphones Distributed Systems Lab Marcel Bertsch, Roland Meyer bertschm@student.ethz.ch, romeyer@student.ethz.ch Distributed
ni.com Digital Signal Processing for Every Application
 Digital Signal Processing for Every Application Digital Signal Processing is Everywhere High-Volume Image Processing Production Test Structural Sound Health and Vibration Monitoring RF WiMAX, and Microwave
Digital Signal Processing for Every Application Digital Signal Processing is Everywhere High-Volume Image Processing Production Test Structural Sound Health and Vibration Monitoring RF WiMAX, and Microwave
Working with BuzzMaster
 Working with BuzzMaster Working with BuzzMaster Technical and organizational details: What does BuzzMaster provide? What is the system capable of? What are the technical considerations? What are the organizational
Working with BuzzMaster Working with BuzzMaster Technical and organizational details: What does BuzzMaster provide? What is the system capable of? What are the technical considerations? What are the organizational
2. AN INTROSPECTION OF THE MORPHING PROCESS
 1. INTRODUCTION Voice morphing means the transition of one speech signal into another. Like image morphing, speech morphing aims to preserve the shared characteristics of the starting and final signals,
1. INTRODUCTION Voice morphing means the transition of one speech signal into another. Like image morphing, speech morphing aims to preserve the shared characteristics of the starting and final signals,
Subjective Similarity of Music: Data Collection for Individuality Analysis
 Subjective Similarity of Music: Data Collection for Individuality Analysis Shota Kawabuchi and Chiyomi Miyajima and Norihide Kitaoka and Kazuya Takeda Nagoya University, Nagoya, Japan E-mail: shota.kawabuchi@g.sp.m.is.nagoya-u.ac.jp
Subjective Similarity of Music: Data Collection for Individuality Analysis Shota Kawabuchi and Chiyomi Miyajima and Norihide Kitaoka and Kazuya Takeda Nagoya University, Nagoya, Japan E-mail: shota.kawabuchi@g.sp.m.is.nagoya-u.ac.jp
Music Database Retrieval Based on Spectral Similarity
 Music Database Retrieval Based on Spectral Similarity Cheng Yang Department of Computer Science Stanford University yangc@cs.stanford.edu Abstract We present an efficient algorithm to retrieve similar
Music Database Retrieval Based on Spectral Similarity Cheng Yang Department of Computer Science Stanford University yangc@cs.stanford.edu Abstract We present an efficient algorithm to retrieve similar
WAKE-UP-WORD SPOTTING FOR MOBILE SYSTEMS. A. Zehetner, M. Hagmüller, and F. Pernkopf
 WAKE-UP-WORD SPOTTING FOR MOBILE SYSTEMS A. Zehetner, M. Hagmüller, and F. Pernkopf Graz University of Technology Signal Processing and Speech Communication Laboratory, Austria ABSTRACT Wake-up-word (WUW)
WAKE-UP-WORD SPOTTING FOR MOBILE SYSTEMS A. Zehetner, M. Hagmüller, and F. Pernkopf Graz University of Technology Signal Processing and Speech Communication Laboratory, Austria ABSTRACT Wake-up-word (WUW)
Supervised Musical Source Separation from Mono and Stereo Mixtures based on Sinusoidal Modeling
 Supervised Musical Source Separation from Mono and Stereo Mixtures based on Sinusoidal Modeling Juan José Burred Équipe Analyse/Synthèse, IRCAM burred@ircam.fr Communication Systems Group Technische Universität
Supervised Musical Source Separation from Mono and Stereo Mixtures based on Sinusoidal Modeling Juan José Burred Équipe Analyse/Synthèse, IRCAM burred@ircam.fr Communication Systems Group Technische Universität
Region Adaptive Unsharp Masking based DCT Interpolation for Efficient Video Intra Frame Up-sampling
 International Conference on Electronic Design and Signal Processing (ICEDSP) 0 Region Adaptive Unsharp Masking based DCT Interpolation for Efficient Video Intra Frame Up-sampling Aditya Acharya Dept. of
International Conference on Electronic Design and Signal Processing (ICEDSP) 0 Region Adaptive Unsharp Masking based DCT Interpolation for Efficient Video Intra Frame Up-sampling Aditya Acharya Dept. of
DT8837 Ethernet High Speed DAQ
 DT8837 High Performance Ethernet (LXI) Instrument Module for Sound & Vibration (Supported by the VIBpoint Framework Application) DT8837 Ethernet High Speed DAQ The DT8837 is a highly accurate multi-channel
DT8837 High Performance Ethernet (LXI) Instrument Module for Sound & Vibration (Supported by the VIBpoint Framework Application) DT8837 Ethernet High Speed DAQ The DT8837 is a highly accurate multi-channel
Setup Guide. SpectraCal MobileForge. Pattern Generator App. Rev. 1.6
 Setup Guide SpectraCal MobileForge Pattern Generator App Rev. 1.6 Introduction MobileForge is a free pattern generator app for ios, Android, and Fire TV devices. MobileForge generates accurate test patterns
Setup Guide SpectraCal MobileForge Pattern Generator App Rev. 1.6 Introduction MobileForge is a free pattern generator app for ios, Android, and Fire TV devices. MobileForge generates accurate test patterns
PSYCHOACOUSTICS & THE GRAMMAR OF AUDIO (By Steve Donofrio NATF)
") PSYCHOACOUSTICS & THE GRAMMAR OF AUDIO (By Steve Donofrio NATF) "The reason I got into playing and producing music was its power to travel great distances and have an emotional impact on people" Quincey
PSYCHOACOUSTICS & THE GRAMMAR OF AUDIO (By Steve Donofrio NATF) "The reason I got into playing and producing music was its power to travel great distances and have an emotional impact on people" Quincey