arxiv: v2 [cs.cv] 23 May 2017
|
|
|
- Todd Cameron
- 6 years ago
- Views:
Transcription

1 Multi-View Image Generation from a Single-View Bo Zhao1,2 Xiao Wu1 1 Zhi-Qi Cheng1 Southwest Jiaotong University 2 Hao Liu2 Jiashi Feng2 National University of Singapore arxiv: v2 [cs.cv] 23 May 2017 {zhaobo.cs, wuxiaohk, zhiqicheng, hfut.haoliu}@gmail.com, elefjia@nus.edu.sg Abstract This paper addresses a challenging problem how to generate multi-view cloth images from only a single view input. To generate realistic-looking images with different views from the input, we propose a new image generation model termed VariGANs that combines the strengths of the variational inference and the Generative Adversarial Networks (GANs). Our proposed VariGANs model generates the target image in a coarse-to-fine manner instead of a single pass which suffers from severe artifacts. It first performs variational inference to model global appearance of the object (e.g., shape and color) and produce a coarse image with a different view. Conditioned on the generated low resolution images, it then proceeds to perform adversarial learning to fill details and generate images of consistent details with the input. Extensive experiments conducted on two clothing datasets, MVC and DeepFashion, have demonstrated that images of a novel view generated by our model are more plausible than those generated by existing approaches, in terms of more consistent global appearance as well as richer and sharper details. Figure 1. The photo-realistic image generation process of the proposed VariGANs. It decomposes the image generation into low and high image generation. The LR images are firstly generated by variational inference with new views v1 and v2. Then, the HR images are generated by filling the details and correcting the defects through adversarial learning. the high dimensionality of images and the complex configuration and layout of image contents, some recent works have demonstrated good performance on realistic image generation beneficial from advanced models like Variational Autoencoder (VAE) [11]) and Generative Adversarial Networks (GANs) [6]. VAE adopts variational inference plus deep representation learning to learn a complex generative model and gets rid of the time-consuming sampling process. However, VAE usually fails to provide rich details in generated images. Another popular generative model, GANs, introduces a real-fake discriminator to supervise the learning of the generative model. Benefiting from the competition between discriminator and generator, GANs are advantageous in providing realistic details, but they usually introduce artifacts to the global appearance, especially when the image to be generated is large. To tackle this challenging problem of generating multiview images from a single-view observation, many approaches [1, 10, 32] first construct the 3D structure of the object and then generate desired target view images from that model. While other methods [18, 29, 33] learn the transformation between the input view and target view by relocating pixels. However, those methods mainly synthe- 1. Introduction Products at e-commerce websites are usually displayed by images from different views. Multi-view images provide straightforward and comprehensive product illustrations to potential buyers. However, such multi-view images are often expensive to produce in both time and cost, thus sometimes not available. For example, when one occasionally sees an image of the desired clothing item from a magazine, which only provides a single view image, he/she has to imagine its look from other views. An automatic model that can generate multi-view images from a single-view input is desired in such scenarios and can find practical application on e-commerce platforms and other applications like photo/video editing and AR/VR. Provided a single view clothing image, we aim to generate the rest views of the input image without requiring any extra information. Although image generation is a challenging task due to 1
2 size rigid objects, e.g. cars, chairs with simple textures. The generation of deformable objects with rich details such as clothes or human body has not been fully explored. In this paper, we propose a novel image generation model named Variational GAN (VariGAN) that combines the strengths of variational inference and adversarial training. The proposed model overcomes the limitations of GAN in modeling global appearance by introducing internal variational inference in the generative model learning. A low resolution (LR) image capturing global appearance is firstly generated by variational inference. This process learns to draw rough shapes and colors of the images to generate at a different view, conditioned on the given images. With the generated LR image, VariGAN then performs adversarial learning to generate realistic high resolution (HR) images by filling richer details to the low resolution image. Since the LR image only has the basic contour of the target object in a desired view, the fine image generation module just needs to focus on drawing details and rectifying defects in low resolution images. See Fig. 1 for illustration. Decomposing the complicated image generation process into the above two complementary learning processes significantly simplifies the learning and produces more realisticlook multi-view images. Note that VariGAN is a generic model and can be applied to other image generation applications like style transfer. We would like to exploit these potential applications of VariGAN in the future. The main contributions are summarized as follows: (1) To our best knowledge, we are the first to address the new problem of generating multi-view clothing images based on a given clothing image of a certain view, which has both theoretical and practical significance. (2) We propose a novel VariGAN generation architecture for multi-view clothing image generation that adopts a new coarse-to-fine image generation strategy. The proposed model is effective in both capturing global appearance and drawing richer details consistent with the input conditioned image. 2. Related Work (3) We apply our proposed model on two largest clothes image datasets and demonstrate its superiority through comprehensive evaluations compared with other stateof-the-arts. We will release the model and relevant code upon acceptance. Image Generation. Image generation has been a heated topic in recent years. Many approaches have been proposed with the emergence of deep learning techniques. Variational Autoencoder (VAE) [11] generates images based on the probabilistic graphical models, and are optimized by maximizing the lower bound of the data likelihood. Yan et al. [28] proposed the Attribute2Image, which generates images from visual attributes. They modeled an image as a composite of foreground and background and extended the VAE with disentangled latent variables. Gregor et al. [7] proposed the DRAW, which integrates the attention mechanism to the VAE to generate realistic images recurrently by patches. Different from the generative parametric approaches, Generative Adversarial Networks (GANs) proposed by Goodfellow et al. [6] introduce a generator and a discriminator in their model. The generator is trained to generate images to confuse the discriminator, and the discriminator is trained to distinguish between real and fake samples. Since then, many GANs-based models have been proposed, including Conditional GANs [15], Bi- GANs [3, 5], Semi-suprvised GANs [16], InfoGAns [2] and Auxiliary Classifier GANs [17]. GANs have been used to generate images from labels [15], text [20, 31] and also images [9, 19, 24, 30, 35, 34]. Our proposed model is also an image-conditioned GAN, with generation capability strengthened by variational inference. View Synthesizing. Images with different views of the object can be easily genertaed with the 3D modeling of the object [1, 4, 12, 10, 32]. Hinton et al. [8] proposed a transforming auto-encoder to generate images with view variance. Rezende et al. [21] introduced a general framework to learn 3D structures from 2D observations with a 3D-2D projection mechanism. Yan et al. [29] proposed Perspective Transformer Nets to learn the projection transformation after reconstructing the 3D volume of the object. Wu et al. [27] also proposed the 3D-2D projection layers that enable the learning of 3D object structures using annotated 2D keypoints. They further proposed the 3D-GAN [27] which generates 3D objects from a probabilistic space by leveraging recent advances in volumetric convolutional networks and generative adversarial nets. Zhou et al. [33] propose to synthesize novel views of the same object or scene corresponding by learning appearance flows. Most of these models are trained with the target view images or image pairs which can be generated by a graphics engine. Therefore, in theory, there are infinite amount of training data with desired view to train the model. However, in our task, the training data is limited in both views and numbers, which greatly adds the difficulties to generate image of different views. 3. Proposed Method 3.1. Problem Setup We first define the problem of generating multi-view images from a single view input. Suppose we have a predefined set of view angles V = {v 1,, v i,, v n }, where v i corresponds to one specific view, e.g. front or side view. An object captured from the view v i is denoted as I vi.
3 I vj Encoder latent variable z N(0, 1) Decoder bi vj Encoder Decoder I v j I vj Target Image Sharing Weights LR Image Sharing Weights HR Image + Target Image + I vi Encoder I vi Encoder I vi I vi Condition Image Condition Image Fine Image Generator Condition Image v j side Target View Word Embedding Coarse Image Generator T F CNN Conditional Discriminator Figure 2. Architecture of the proposed VariGAN. It consists of three modules: coarse image generator, fine image generator and conditional discriminator. During training, a LR Image is firstly generated by the coarse image generator conditioned on the target image, conditioned image and target view. The fine image generator with skip connections is designed to generate the HR image. Finally, the HR image and the conditioned image are concatenated as negative pairs and passed to the conditional discriminator together with positive pairs (target image & condition image) to distinguish real and fake. Given the source image I vi, multi-view image generation is to generate an image I vj with a different view from I vi, i.e. v j V and j i Variational GANs Standard GANs have been applied to generate images of desired properties based on the input. This type of model learns a generative model G on the distribution of the desired images, sampling from which would provide new images. Different from other generative models, GANs employ an extra discriminative model D to supervise the generative learning process, instead of purely optimizing G to best explain training data via Maximum Likelihood Estimation. Specified in multi-view image generation, given an input conditioned image I vi (captured at viewpoint v i ), the goal is to learn the distribution p(i vj I v, v j ) for generating the new image I vj of a different viewpoint v j, from a labeled dataset (I vj,1, I vi,1),..., (I vj,n, I vi,n). Here v j is specified by users as an input to the model. The objective of GANs is defined as min maxe Ivi p data(i vi ),I vj p data(i vj I vi,v θ G θ D j)[log D(I vi, I vj )]+ E z p(z) [log(1 D(I vi, G(z, I vi, v j ))], where G tries to generate real data I vj given noise z p(z) through minimizing its loss to fool an adversarial discriminator D, and D tries to maximize its discrimination accuracy between real data and generated data. However, it is difficult to learn a generator G to produce plausible images of high resolution, correct contour and rich details, because GANs are limited in capturing Neg Pos global appearance. To address this critical issue and generate more realistic images, the variational GANs (VariG- ANs) proposed in this work combines the strengths of variation inference for modeling correct contours and adversarial learning to fill realistic details. It decomposes the generator into two components. One is for generating a coarse image through the variational inference model V and the other is for generating the final image with fine details based on the outcome from V. Formally, the objective of VariGANs is min θ G max E Ivi p data(i vi ),I vj p data(i vj I v,v θ D,θ V j)[log D(I vi, I vj )]+ E z p(z) [log(1 D(I vi, G(V (z, I vi, v j ), I vi, v j ))]. (1) Here z is the random latent variable and V is the coarse image generator. This objective can be optimized by maximizing the variational lower bound of V, maximizing the discrimination accuracy of D, and minimizing the loss of G against D. We will elaborate the model of V, G and D in the following parts Coarse Image Generation Given an input image I vi with the view of v i, target view v j, and latent variable z, the coarse image generator V (I vi, z, v j ) learns the distribution p(îv j I v, z) with focus on modeling the global appearance. We use θ V to denote parameters of the coarse image generator. To alleviate difficulties of directly optimizing this log-likelihood function and avoid the time-consuming sampling, we apply the variational Bayesian approach to optimize the lower bound of the log-likelihood log p θ (Îv j I v, v j ), as proposed in [11, 22]. Specifically, an auxiliary distribution q φ (z Îv j, I vi, v j ) is introduced to approximate the true posterior p θv (z Îv j, I vi, v j ).
4 The conditional log-likelihood of the coarse image generator V is defined as log p θv (Îv j I vi, v j ) = L(Îv j, I vi, v j ; θ, φ)+ ( ) KL q φ (z Îv j, I vi, v j ) p θ (z Îv j, I vi, v j ), where the variational lower bound is ( ) L(Îv j,i vi, v j ; θ, φ) = KL q φ (z Îv j, I vi, v j ) p θ (z) + E qφ (z Îv j,iv i,vj)[log p θ(îv j I vi, v j, z)], (2) where the first KL term in Eqn. (2) is a regularization term that reduces the gap between the prior p(z) and the proposal distribution q φ (z Îv j, I vi, v j ). The second term log p θv (Îv j I vi, v j, z) is the log likelihood of samples and is usually measured by the reconstruction loss, e.g., l 1 used in our model Fine Image Generation After obtaining the low resolution image Îv j of the desired output I vj, the fine image generation module learns another generator G that maps the low resolution image Îv j to the high resolution image Iv j conditioned on the input I vi. The generator G is trained to generate images that cannot be distinguished from real images by an adversarial conditional discriminator, D, which is trained to distinguish as well as possible the generator s fakes. See Eqn. (1). Since the multi-view image generator need not only fool the discriminator but also be near the ground truth of the target image with a different view, we also add the l 1 loss for the generator. The l 1 loss is chosen because it alleviates over-smoothing artifacts compared with l 2 loss. Then, the GANs of fine image generation train the discriminator D and the generator G by alternatively maximizing L D in Eqn. (3) and minimizing L G in Eqn. (4): L D =E (Ivi,I vj ) p data [log D(I vi, I vj )]+ E z p(z) [log(1 D(I vi, G(Îv j (z), I vi, v j )))], (3) L G =E z p(z) [log(1 D(I vi, G(Îv j (z), I v, v )]+ λ I vj G(Îv j (z), I vi, v j ) 1, (4) where Îv j is the coarse image generated by V. The real images I vi and I vj are from the true data distribution Network Architecture The overall architecture of the proposed model in the training phase is illustrated in Fig. 2. It consists of three modules: the coarse image generator, the fine image generator and the conditional discriminator. During training, the target view image I vj and the conditioned image I vi are passed through two siamese-like encoders to learn their representations respectively. By word embedding, the input desired view angle v j is transformed into a vector. The representations of I vi, I vj and v j are combined to generate the latent variable z. However, during testing, there is no target image I vi and the encoder for it. The latent variable z is randomly sampled and combined with the representation of the condition image I vi and the target view v j to generate the target view LR image Îv j. After that, I vi and Îv j are sent to the fine image generator to generate the HR image Iv j. Similar to the coarse image generation module, the fine image generation module also contains two siamese-like encoders and a decoder. Moreover, there are skip connections between mirrored layers in the encoder and decoder stacks. By the channel concatenation of the HR image Iv j and the condition image I vi, a conditional discriminator is adopted to distinguish whether the generated image is real or fake. Coarse Image Generator There are several convolution layers in the encoder of the coarse image generator to down sample the input image to an M l 1 1 tensor. Then a fully-connected layer is topped to transform the tensor to an M l -D representation. The encoders for the target image and the condition image share weights. A word embedding layer is employed to embed the target view into an M l -D vector. The representations of the target image, the conditioned image and the view embedding are combined and transformed to an M l -D latent variable. Then, the latent variable together with the conditioned image representation and the view embedding are passed through a series of deconvolutional layers to generate a W LR W LR image. Fine Image Generator with Skips Similar to the coarse image generation module, the fine image generator also contains two siamese-like encoders and a decoder. The encoder consists of several convolutional layers to downsample the image to a M h 1 1 tensor. Then several deconvolutional layers are used to up-sample the bottleneck tensor to W HR W HR. Since the mapping from low resolution image to high resolution image can be seen as a conditional image translation problem, the low and high resolution images only differ in surface appearance, but both are rendered under the same underlying structure. Therefore, the shape information can be shared between the LR and HR image. Besides, the lowlevel information of the conditioned image will also provide rich guidance when translating the LR image to the HR image. It would be desirable to shuttle these two kinds of information directly across the net. Inspired by the work of U-Net [23] and image-to-image translateion [9], we add skip connections between the LR image encoder and the HR image decoder, and also between the conditioned image encoder and the HR image decoder simultaneously (see Fig. 3). By such skip connections, the decoder up-samples the encoded tensor to the high resolution image with the target view by several de-convolution layers.
5 4. Experiment LR Image Condition Image HR Image Figure 3. Dual-path U-Net. There are skip connections between the mirrored layers in two encoders and a decoder. Conditional Discriminator The generated high resolution image Iv j and the ground-truth target image I vj are concatenated with the conditioned image I vi by channels to form the negative pair and positive pair, respectively. These two kinds of image pairs are passed to the conditional discriminator and train the fine image generator adversarially Implementation Details For the coarse image generator, an encoder network contains 6 convolution layers followed by 1 fully-connected layer (convolution layers have 64, 128, 256, 256, 256 and 1024 channels with filter size of 5 5, 5 5, 5 5, 3 3, 3 3 and 4 4, respectively; the fully-connected layer has 1024 neurons), and M l is set to 1024, W LR is set to 64, respectively. The representations of the target image and the condition image and the embedding of the target view are concatenated and transformed to the latent variable by a fully-connected layer with 1024 neurons. The decoder network consists of 1 fully-connected layers with neurons, followed by 6 de-convolutional layers with 2 2 up-sampling (with 256, 256, 256, 128, 64 and 3 channels with filter size of 3 3, 5 5, 5 5, 5 5, 5 5 and 5 5). For the fine image generation module, the encoder network contains 7 convolution layers (with 64, 128, 256, 512, 512, 512, 512 channels with filter size of 4 4 and stride 2). Thus, M h is set to 512. The decoder network consists of 7 de-convolutional layers with 512, 512, 512, 256, 128, 64 and 3 channels with filter size 4 4 and stride 2. The conditional discriminator consists of 5 convolutional layers (they have 64, 128, 256, 512 and 1 channel(s) with filer size 4 4 and stride 2, 2, 2, 1, 1). W HR is set to 128. For training, we first train the coarse image generator for 500 epochs. Using the generated low resolution image and the conditioned image, we then iteratively train the fine image generator and the conditional discriminator for another 500 epochs. All networks are trained using ADAM solvers with batch size of 32 and an initial learning rate of To validate the effectiveness of our proposed VariGAN model, we conduct extensive quantitative and qualitative evaluations on the MVC [13] and the DeepFashion [14] datasets that contain a huge number of clothing images with different views. We compare the performance of generating multi-view images with two state-of-the-art image generation models: conditional VAE (cvae) [25], conditional GANs (cgans) [15]. The cvae has a similar architecture as the coarse image generator in our VGANs. It has one more convolution layer in the encoder and one more de-convolution layer in the decoder, which directly generates the HR Image. The cgans have one encoder network to encode the conditioned image and one word embedding layer to transform the view to the vector. The encoded conditioned image and the view embedding are concatenated and fed into the decoder to generate the HR image. In addition to performance comparison with state-of-theart models, we do ablation studies to investigate the design and important components of our proposed VariGANs. We firstly conduct experiment that replace the variational inference with GANs. Secondly, we train our model without the dual-path U-Net in the fine image generation module to verify the role of the skip connections between the encoders and the decoder. We also conduct experiments without l 1 loss to prove the importance of the traditional loss for plausible image generation. Finally, we do experiments of VariGANs without the conditional discriminator to show whether the channel-concatenation of the generated image and the condition image is beneficial for the high resolution image generation. Now we proceed to introduce details on evaluation benchmarks and present experimental results Datasets and Evaluation Metrics Datasets MVC 1 contains 36,323 clothing items. Most of them have 4 views, i.e. front, left side, right side and back side. DeepFashion 2 contains 8,697 clothing items with 4 views, i.e. front, side (left or right), back and full body. Example images from the two datasets are demonstrated in Fig. 4. We can see that the view and scale variance of images from DeepFashion is much higher than those in MVC. The total number of images in DeepFashion is also much smaller than MVC. Both the high variance and the limited number of training samples bring great difficulties to multi-view image generation on DeepFashion. To give a consistent task specification of multi-view image generation on the two datasets, we define that the view set contains the front, side and back view. We consider two generation goals: to generate the side view and back view images con
![chosen as another metric in our paper as [31, 9]. It is defined as IS(I x, y) = exp(e Ix D KL (p(y I x ) p(y))), (a) MVC (b) DeepFashion Figure 4.](/docs-images/74/70721306/images/6-0.jpg "Example images with multi-views from the MVC [13] and DeepFashion [14], respectively. ditioned on the front view image; and to generate the front view and back view image from side view images.")

 [26] to measure the similarity between generated image")

 from the ground truth, which means pixel-wise mean square")
6 chosen as another metric in our paper as [31, 9]. It is defined as IS(I x, y) = exp(e Ix D KL (p(y I x ) p(y))), (a) MVC (b) DeepFashion Figure 4. Example images with multi-views from the MVC [13] and DeepFashion [14], respectively. ditioned on the front view image; and to generate the front view and back view image from side view images. These two scenarios are most popular in real life. We split the MVC dataset into the training set with 33,323 groups of images and the testing set with 3,000 groups of images. Each group contains the three views of clothing images. The training set of DeepFashion dataset consists of 7,897 groups of clothing images, and there are 800 groups of images in the testing set. Evaluation Metrics In the previous literatures on image generation, the performance is usually evaluated by human subjects, which is subjective and time-consuming. Since the ground-truth images with target views are provided in the datasets, thus in our experiments, we adopt the Structural Similarity (SSIM) [26] to measure the similarity between generated image and ground truth image. We do not use the pixel-level mean square error as the evaluation metric since we focus more on the quality of generated clothes images for evaluation (note similarity of generated image and ground truth essentially also measures the quality of the result). There are usually human models in the generated clothes images, thus the images may present different poses (even in the same viewpoint) from the ground truth, which means pixel-wise mean square error is not suitable in our case. SSIM can faithfully reflect the similarity of two images regardless of the light condition or small pose variance, since it models the perceived change in the structural information of the images. This evaluation metric is also widely used in many other image generation papers such as [30, 18]. The SSIM between two images I x and I y is defined as SSIM(I x, I y ) = (2µ xµ y + c 1 )(2σ xy + c 2 ) (µ 2 x + µ 2 y + c 1 )(σ 2 x + σ 2 y + c 2 ), where x and y are the generated image and the ground-truth image. µ and σ are the average and variance of the image. c 1 and c 2 are two variables to stabilize the division, which are determined by the dynamic range of the images. The inception score [24] for quantitative evaluation is where I x denotes one generated image, and y is the label predicted by the Inception model. It is computed based on the assumption that the generated image with good quality should diverse and meaningful, i.e., the KL divergence between the marginal distribution p(y) and the conditional distribution p(y I x ) should be large Experimental Results and Analysis We compare our results with two state-of-the-arts methods, i.e. Conditional VAE (cvae) [25] and Conditional GANs (cgans) [15] on MVC and DeepFashion datasets. The SSIM and Inception Scores for our proposed method and compared methods are reported in Table 1. We can see that cvae has the worst SSIM and Inception Scores on both datasets, while the cgans improve the SSIM and Inception Score compared to cvae. Our proposed VariG- ANs further improves the performance on both datasets. The better SSIM and Inception Scores also indicate that our proposed method is able to generate more realistic images conditioned on the single-view image and the target view. We demonstrate some representative examples generated by the state-of-the-arts methods and our proposed method in Fig. 5. It can be seen that the samples generated by cvae are blurry, and the color is not correct. However, it correctly draws the general shape of the person and the clothes in the side view. The images generated by cgans are more realistic with more details, but present severe artifacts. Some of the generated images look unrealistic, such as the example in the second row. The low resolution image generated by the proposed coarse image generator with our proposed VariGAN model presents better shape and contour than cvae, benefiting from a more reasonable target setting for this phase (i.e. only generating LR images). Besides, the generated LR image looks more natural than those generated by other baselines, in terms of the view point, shape and contour. Finally, the fine image generator fills correct color and adds richer and realistic texture to the LR image. We give more examples generated by our VariGANs in Fig. 6. The first two rows are from MVC dataset, and the others are from the DeepFashion dataset. The first and third row show generating the side and back view images from Table 1. SSIM and IS of our proposed method and state-of-the-arts methods. Methods SSIM IS MVC DF MVC DF cvae [25] 0.66 ± ± ± ±.08 cgans [15] 0.69 ± ± ± ±.10 Ours 0.70 ± ± ± ±.20
 Ours (e) GT")


 Input Images (b)")
 GT Images")
 GT")





 (d) (e) (f) Figure")

 & (c)) in")

")







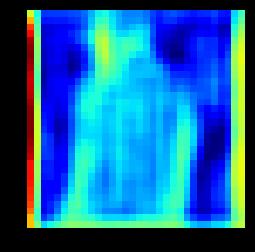

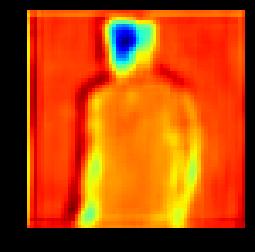
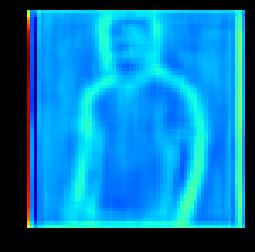
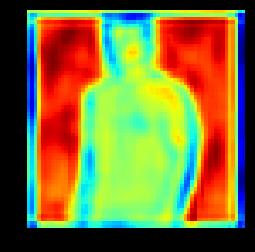
7 (a) Input (b) cvae (c) cgans (d) Ours (e) GT Figure 5. Example results by our proposed method and state-of-the-arts methods. (a) Input Images (b) Coarse Images (c) Fine Images (d) GT Images (e) Coarse Images (f) Fine Images (g) GT Images Figure 6. Example results by our proposed method. The first two rows shows examples from MVC, and the last two rows shows examples from DeepFashion. The images are generated from coarse to fine conditioned on input images of different views (a) (b) (c) (d) (e) (f) Figure 7. Visualization of feature maps in the first two convolution layers ((b) & (c)) in the encoder of coarse image generation and the mirrored last two convolution layers ((d) & (e)) in the decoder of coarse image generation. Our model learns how to transform image into the desired view. (a) and (f) are the input image and the generated LR image. the front view. Given the side view image, the second and fourth row demonstrate the generated front and back view images. There are coarse images, fine images and groundtruth images shown in each column of Fig. 6 (a) and Fig. 6 (b). It can be seen that the generated coarse images have the right view based on the conditioned image. The details are added to the coarse images reasonably by our fine image generation module. The results also demonstrate that
, (c), (d) and (e) are the results of the model without V, Dual-path U-Net, l 1 loss and conditional discriminator, respectively. (f) shows the results generated by our proposed model.")

8 (a) (b) (c) (d) (e) (f) (g) Figure 8. Generated images with different variants of our proposed method. (b), (c), (d) and (e) are the results of the model without V, Dual-path U-Net, l 1 loss and conditional discriminator, respectively. (f) shows the results generated by our proposed model. (a) and (g) are the input images and the ground truth image. Table 2. SSIM and IS of our proposed method and its variants. Methods SSIM IS MVC DF MVC DF Ours w/o V 0.69 ± ± ± ±.08 Ours w/o U-Net 0.56 ± ± ± ±.07 Ours w/o l ± ± ± ±.06 Ours w/o cdisc 0.66 ± ± ± ±.05 Ours 0.70 ± ± ± ±.20 the generated images need not be the same as the groundtruth image. There may be pose variance in the generated images like the generated front view image of the second example. Note that our proposed model focuses on clothes generation and does not consider humans in the image. Besides, some blocky artifacts can be observed in some examples, In the future, we would explore how to remove such artifacts by adopting more complicated models to learn to generate sharper details. Nevertheless, the current results present sufficient details about novel views for users. Visualization of the Feature Maps. To provide a deeper insight to the mechanism of the multi-view image generation in our proposed model, we also visualize the feature maps of the first two convolution layers in the encoder of coarse image generation and their corresponding de-convolution layers in the decoder (i.e. the last two), as shown in Fig. 7. The visualization demonstrates that the model learns how to change the view of different parts of the image. From the visualization results, one can observe that the generated feature maps effectively capture the transition of view angles and the counters from another view Ablation Study In this subsection, we analyze the effectiveness of the components in our proposed model on MVC and DeepFashion to further validate the design of our model by conducting following experiments: (1) VariGANs w/o V. In this experiment, the variational inference is replaced by another GANs to investigate the role of variational inference in our proposed Vari- GANs. (2) VariGANs w/o U-Net. The LR image and the conditioned image go through the Siamese encoder in the fine image generator until a bottle-neck, and the outputs of the encoders are concatenated and fed into the decoder networks. (3) VariGANs w/o l 1 loss. This experiment is to verify the importance of the traditional reconstruction loss in generating plausible images. (4) VariGANs w/o conditional discriminator. Only the generated HR images and ground truth images are sent to the discriminator separately. We report the results of those experiments on MVC and DeepFashion in Table 2. It can be seen that removing or replacing any component of our model lowers the performance of SSIM and IS. We also illustrate the images generated by different variants of our VariGANs in Fig. 8. Conditioned on the LR image generated by GANs, the result in Fig. 8.(b) displays relative good shape and right texture. However, there are also missing parts, i.e. the left hand, in the generated image. The results generated by VariGANs without the dual-path U-Net have incomplete areas and unnatural colors as shown in Fig. 8.(c). Without l 1 loss, the detail texture is not learned well such as the upper part of the cloth in Fig. 8.(d). VariGANs without conditional discriminator generate comparative results (Fig. 8.(e)) as VariGANs (Fig. 8.(f)) except some smears. 5. Conclusion In this paper, we propose a Variational Generative Adversarial Networks (VariGANs) for synthesizing realistic clothing images with different views as input image. The proposed method enhances the GANs with variational inference, which generate image from coarse to fine. Specifically, providing the input image with a certain view, the coarse image generator first generate the basic shape of the object with target view. Then the fine image generator fill the details into the coarse image and correct the defects. With extensive experiments, our model can generate more plausible results than the state-of-the-arts methods. The ablation studies also verify the importance of each component in the proposed VariGANs.
9 References [1] T. Chen, Z. Zhu, A. Shamir, S.-M. Hu, and D. Cohen-Or. 3- sweep: Extracting editable objects from a single photo. ACM Transactions on Graphics, , 2 [2] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. arxiv: , [3] J. Donahue, P. Krähenbähl, and T. Darrell. Adversarial feature learning. arxiv: , [4] A. Dosovitskiy, J. T. Springenberg, M. Tatarchenko, and T. Brox. Learning to generate chairs, tables and cars with convolutional networks. In CVPR, [5] V. Dumoulin, I. Belghazi, B. Poole, O. Mastropietro, A. Lamb, M. Arjovsky, and A. Courville. Adversarially learned inference. arxiv: , [6] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, , 2 [7] K. Gregor, I. Danihelka, A. Graves, D. J. Rezende, and D. Wierstra. Draw: A recurrent neural network for image generation. In ICML, [8] G. E. Hinton, A. Krizhevsky, and S. D. Wang. Transforming auto-encoders. In ICANN, [9] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Imageto-image translation with conditional adversarial networks. arxiv: , , 4, 6 [10] N. Kholgade, T. Simon, A. Efros, and Y. Sheikh. 3d object manipulation in a single photograph using stock 3d models. ACM Transactions on Graphics, , 2 [11] D. P. Kingma and M. Welling. Auto-encoding variational bayes. In ICLR, , 2, 3 [12] T. D. Kulkarni, W. Whitney, P. Kohli, and J. B. Tenenbaum. Deep convolutional inverse graphics network. In NIPS, [13] K.-H. Liu, T.-Y. Chen, and C.-S. Chen. Mvc: A dataset for view-invariant clothing retrieval and attribute prediction. In ICMR, , 6 [14] Z. Liu, P. Luo, S. Qiu, X. Wang, and X. Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In CVPR, , 6 [15] M. Mirza and S. Osindero. Conditional generative adversarial nets. arxiv: , , 5, 6 [16] A. Odena. Semi-supervised learning with generative adversarial networks. arxiv: , [17] A. Odena, C. Olah, and J. Shlens. Conditional image synthesis with auxiliary classifier gans. arxiv: , [18] E. Park, J. Yang, E. Yumer, D. Ceylan, and A. C. Berg. Transformation-grounded image generation network for novel 3d view synthesis. In CVPR, , 6 [19] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros. Context encoders: Feature learning by inpainting. In CVPR, [20] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text-to-image synthesis. In ICML, [21] D. J. Rezende, S. M. A. Eslami, S. Mohamed, P. W. Battaglia, M. Jaderberg, and N. Heess. Unsupervised learning of 3d structure from images. In NIPS, [22] D. J. Rezende, S. Mohamed, and D. Wierstra. Stochastic backpropagation and approximate inference in deep generative models. In ICML, [23] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MIC- CAI, [24] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training gans. arxiv: , , 6 [25] K. Sohn, H. Lee, and X. Yan. Learning structured output representation using deep conditional generative models. In NIPS, , 6 [26] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4): , [27] J. Wu, T. Xue, J. J. Lim, Y. Tian, J. B. Tenenbaum, A. Torralba, and W. T. Freeman. Single image 3d interpreter network. In ECCV, [28] X. Yan, J. Yang, K. Sohn, and H. Lee. Attribute2image: Conditional image generation from visual attributes. In ECCV, [29] X. Yan, J. Yang, E. Yumer, Y. Guo, and H. Lee. Perspective transformer nets: Learning single-view 3d object reconstruction without 3d supervision. In NIPS, , 2 [30] D. Yoo, N. Kim, S. Park, A. S. Paek, and I. S. Kweon. Pixellevel domain transfer. arxiv: , , 6 [31] H. Zhang, T. Xu, H. Li, S. Zhang, X. Huang, X. Wang, and D. Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. arxiv: , , 6 [32] Y. Zheng, X. Chen, M.-M. Cheng, K. Zhou, S.-M. Hu, and N. J. Mitra. Interactive images: cuboid proxies for smart image manipulation. ACM Transactions on Graphics, , 2 [33] T. Zhou, S. Tulsiani, W. Sun, J. Malik, and A. A. Efros. View synthesis by appearance flow. In ECCV, , 2 [34] Y. Zhou and T. L. Berg. Learning temporal transformations from time-lapse videos. In ECCV, [35] J.-Y. Zhu, P. Krähenbühl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In ECCV,
Using Variational Autoencoders to Learn Variations in Data
 Using Variational Autoencoders to Learn Variations in Data By Dr. Ethan M. Rudd and Cody Wild Often, we would like to be able to model probability distributions of high-dimensional data points that represent
Using Variational Autoencoders to Learn Variations in Data By Dr. Ethan M. Rudd and Cody Wild Often, we would like to be able to model probability distributions of high-dimensional data points that represent
Joint Image and Text Representation for Aesthetics Analysis
 Joint Image and Text Representation for Aesthetics Analysis Ye Zhou 1, Xin Lu 2, Junping Zhang 1, James Z. Wang 3 1 Fudan University, China 2 Adobe Systems Inc., USA 3 The Pennsylvania State University,
Joint Image and Text Representation for Aesthetics Analysis Ye Zhou 1, Xin Lu 2, Junping Zhang 1, James Z. Wang 3 1 Fudan University, China 2 Adobe Systems Inc., USA 3 The Pennsylvania State University,
Research Article. ISSN (Print) *Corresponding author Shireen Fathima
 *Corresponding author Shireen Fathima") Scholars Journal of Engineering and Technology (SJET) Sch. J. Eng. Tech., 2014; 2(4C):613-620 Scholars Academic and Scientific Publisher (An International Publisher for Academic and Scientific Resources)
Scholars Journal of Engineering and Technology (SJET) Sch. J. Eng. Tech., 2014; 2(4C):613-620 Scholars Academic and Scientific Publisher (An International Publisher for Academic and Scientific Resources)
arxiv: v3 [cs.sd] 14 Jul 2017
![arxiv: v3 [cs.sd] 14 Jul 2017](/thumbs/74/69700627.jpg "arxiv: v3 [cs.sd] 14 Jul 2017") Music Generation with Variational Recurrent Autoencoder Supported by History Alexey Tikhonov 1 and Ivan P. Yamshchikov 2 1 Yandex, Berlin altsoph@gmail.com 2 Max Planck Institute for Mathematics in the
Music Generation with Variational Recurrent Autoencoder Supported by History Alexey Tikhonov 1 and Ivan P. Yamshchikov 2 1 Yandex, Berlin altsoph@gmail.com 2 Max Planck Institute for Mathematics in the
Deep Aesthetic Quality Assessment with Semantic Information
 1 Deep Aesthetic Quality Assessment with Semantic Information Yueying Kao, Ran He, Kaiqi Huang arxiv:1604.04970v3 [cs.cv] 21 Oct 2016 Abstract Human beings often assess the aesthetic quality of an image
1 Deep Aesthetic Quality Assessment with Semantic Information Yueying Kao, Ran He, Kaiqi Huang arxiv:1604.04970v3 [cs.cv] 21 Oct 2016 Abstract Human beings often assess the aesthetic quality of an image
DeepID: Deep Learning for Face Recognition. Department of Electronic Engineering,
 DeepID: Deep Learning for Face Recognition Xiaogang Wang Department of Electronic Engineering, The Chinese University i of Hong Kong Machine Learning with Big Data Machine learning with small data: overfitting,
DeepID: Deep Learning for Face Recognition Xiaogang Wang Department of Electronic Engineering, The Chinese University i of Hong Kong Machine Learning with Big Data Machine learning with small data: overfitting,
A Discriminative Approach to Topic-based Citation Recommendation
 A Discriminative Approach to Topic-based Citation Recommendation Jie Tang and Jing Zhang Department of Computer Science and Technology, Tsinghua University, Beijing, 100084. China jietang@tsinghua.edu.cn,zhangjing@keg.cs.tsinghua.edu.cn
A Discriminative Approach to Topic-based Citation Recommendation Jie Tang and Jing Zhang Department of Computer Science and Technology, Tsinghua University, Beijing, 100084. China jietang@tsinghua.edu.cn,zhangjing@keg.cs.tsinghua.edu.cn
Skip Length and Inter-Starvation Distance as a Combined Metric to Assess the Quality of Transmitted Video
 Skip Length and Inter-Starvation Distance as a Combined Metric to Assess the Quality of Transmitted Video Mohamed Hassan, Taha Landolsi, Husameldin Mukhtar, and Tamer Shanableh College of Engineering American
Skip Length and Inter-Starvation Distance as a Combined Metric to Assess the Quality of Transmitted Video Mohamed Hassan, Taha Landolsi, Husameldin Mukhtar, and Tamer Shanableh College of Engineering American
LSTM Neural Style Transfer in Music Using Computational Musicology
 LSTM Neural Style Transfer in Music Using Computational Musicology Jett Oristaglio Dartmouth College, June 4 2017 1. Introduction In the 2016 paper A Neural Algorithm of Artistic Style, Gatys et al. discovered
LSTM Neural Style Transfer in Music Using Computational Musicology Jett Oristaglio Dartmouth College, June 4 2017 1. Introduction In the 2016 paper A Neural Algorithm of Artistic Style, Gatys et al. discovered
Sequence generation and classification with VAEs and RNNs
 Jay Hennig 1 * Akash Umakantha 1 * Ryan Williamson 1 * 1. Introduction Variational autoencoders (VAEs) (Kingma & Welling, 2013) are a popular approach for performing unsupervised learning that can also
Jay Hennig 1 * Akash Umakantha 1 * Ryan Williamson 1 * 1. Introduction Variational autoencoders (VAEs) (Kingma & Welling, 2013) are a popular approach for performing unsupervised learning that can also
Predicting Aesthetic Radar Map Using a Hierarchical Multi-task Network
 Predicting Aesthetic Radar Map Using a Hierarchical Multi-task Network Xin Jin 1,2,LeWu 1, Xinghui Zhou 1, Geng Zhao 1, Xiaokun Zhang 1, Xiaodong Li 1, and Shiming Ge 3(B) 1 Department of Cyber Security,
Predicting Aesthetic Radar Map Using a Hierarchical Multi-task Network Xin Jin 1,2,LeWu 1, Xinghui Zhou 1, Geng Zhao 1, Xiaokun Zhang 1, Xiaodong Li 1, and Shiming Ge 3(B) 1 Department of Cyber Security,
arxiv: v1 [cs.lg] 15 Jun 2016
![arxiv: v1 [cs.lg] 15 Jun 2016](/thumbs/79/79195906.jpg "arxiv: v1 [cs.lg] 15 Jun 2016") Deep Learning for Music arxiv:1606.04930v1 [cs.lg] 15 Jun 2016 Allen Huang Department of Management Science and Engineering Stanford University allenh@cs.stanford.edu Abstract Raymond Wu Department of
Deep Learning for Music arxiv:1606.04930v1 [cs.lg] 15 Jun 2016 Allen Huang Department of Management Science and Engineering Stanford University allenh@cs.stanford.edu Abstract Raymond Wu Department of
Music Composition with RNN
 Music Composition with RNN Jason Wang Department of Statistics Stanford University zwang01@stanford.edu Abstract Music composition is an interesting problem that tests the creativity capacities of artificial
Music Composition with RNN Jason Wang Department of Statistics Stanford University zwang01@stanford.edu Abstract Music composition is an interesting problem that tests the creativity capacities of artificial
arxiv: v1 [cs.sd] 21 May 2018
![arxiv: v1 [cs.sd] 21 May 2018](/thumbs/83/88396509.jpg "arxiv: v1 [cs.sd] 21 May 2018") A Universal Music Translation Network Noam Mor, Lior Wolf, Adam Polyak, Yaniv Taigman Facebook AI Research arxiv:1805.07848v1 [cs.sd] 21 May 2018 Abstract We present a method for translating music across
A Universal Music Translation Network Noam Mor, Lior Wolf, Adam Polyak, Yaniv Taigman Facebook AI Research arxiv:1805.07848v1 [cs.sd] 21 May 2018 Abstract We present a method for translating music across
An Introduction to Deep Image Aesthetics
 Seminar in Laboratory of Visual Intelligence and Pattern Analysis (VIPA) An Introduction to Deep Image Aesthetics Yongcheng Jing College of Computer Science and Technology Zhejiang University Zhenchuan
Seminar in Laboratory of Visual Intelligence and Pattern Analysis (VIPA) An Introduction to Deep Image Aesthetics Yongcheng Jing College of Computer Science and Technology Zhejiang University Zhenchuan
arxiv: v3 [cs.ne] 3 Dec 2015
![arxiv: v3 [cs.ne] 3 Dec 2015](/thumbs/90/101428769.jpg "arxiv: v3 [cs.ne] 3 Dec 2015") Inverting Visual Representations with Convolutional Networks Alexey Dosovitskiy Thomas Brox University of Freiburg Freiburg im Breisgau, Germany {dosovits,brox}@cs.uni-freiburg.de arxiv:1506.02753v3 [cs.ne]
Inverting Visual Representations with Convolutional Networks Alexey Dosovitskiy Thomas Brox University of Freiburg Freiburg im Breisgau, Germany {dosovits,brox}@cs.uni-freiburg.de arxiv:1506.02753v3 [cs.ne]
Neural Aesthetic Image Reviewer
 Neural Aesthetic Image Reviewer Wenshan Wang 1, Su Yang 1,3, Weishan Zhang 2, Jiulong Zhang 3 1 Shanghai Key Laboratory of Intelligent Information Processing School of Computer Science, Fudan University
Neural Aesthetic Image Reviewer Wenshan Wang 1, Su Yang 1,3, Weishan Zhang 2, Jiulong Zhang 3 1 Shanghai Key Laboratory of Intelligent Information Processing School of Computer Science, Fudan University
Broken Wires Diagnosis Method Numerical Simulation Based on Smart Cable Structure
 PHOTONIC SENSORS / Vol. 4, No. 4, 2014: 366 372 Broken Wires Diagnosis Method Numerical Simulation Based on Smart Cable Structure Sheng LI 1*, Min ZHOU 2, and Yan YANG 3 1 National Engineering Laboratory
PHOTONIC SENSORS / Vol. 4, No. 4, 2014: 366 372 Broken Wires Diagnosis Method Numerical Simulation Based on Smart Cable Structure Sheng LI 1*, Min ZHOU 2, and Yan YANG 3 1 National Engineering Laboratory
LEARNING AUDIO SHEET MUSIC CORRESPONDENCES. Matthias Dorfer Department of Computational Perception
 LEARNING AUDIO SHEET MUSIC CORRESPONDENCES Matthias Dorfer Department of Computational Perception Short Introduction... I am a PhD Candidate in the Department of Computational Perception at Johannes Kepler
LEARNING AUDIO SHEET MUSIC CORRESPONDENCES Matthias Dorfer Department of Computational Perception Short Introduction... I am a PhD Candidate in the Department of Computational Perception at Johannes Kepler
A repetition-based framework for lyric alignment in popular songs
 A repetition-based framework for lyric alignment in popular songs ABSTRACT LUONG Minh Thang and KAN Min Yen Department of Computer Science, School of Computing, National University of Singapore We examine
A repetition-based framework for lyric alignment in popular songs ABSTRACT LUONG Minh Thang and KAN Min Yen Department of Computer Science, School of Computing, National University of Singapore We examine
Discriminative and Generative Models for Image-Language Understanding. Svetlana Lazebnik
 Discriminative and Generative Models for Image-Language Understanding Svetlana Lazebnik Image-language understanding Robot, take the pan off the stove! Discriminative image-language tasks Image-sentence
Discriminative and Generative Models for Image-Language Understanding Svetlana Lazebnik Image-language understanding Robot, take the pan off the stove! Discriminative image-language tasks Image-sentence
Image-to-Markup Generation with Coarse-to-Fine Attention
 Image-to-Markup Generation with Coarse-to-Fine Attention Presenter: Ceyer Wakilpoor Yuntian Deng 1 Anssi Kanervisto 2 Alexander M. Rush 1 Harvard University 3 University of Eastern Finland ICML, 2017 Yuntian
Image-to-Markup Generation with Coarse-to-Fine Attention Presenter: Ceyer Wakilpoor Yuntian Deng 1 Anssi Kanervisto 2 Alexander M. Rush 1 Harvard University 3 University of Eastern Finland ICML, 2017 Yuntian
Stereo Super-resolution via a Deep Convolutional Network
 Stereo Super-resolution via a Deep Convolutional Network Junxuan Li 1 Shaodi You 1,2 Antonio Robles-Kelly 1,2 1 College of Eng. and Comp. Sci., The Australian National University, Canberra ACT 0200, Australia
Stereo Super-resolution via a Deep Convolutional Network Junxuan Li 1 Shaodi You 1,2 Antonio Robles-Kelly 1,2 1 College of Eng. and Comp. Sci., The Australian National University, Canberra ACT 0200, Australia
Free Viewpoint Switching in Multi-view Video Streaming Using. Wyner-Ziv Video Coding
 Free Viewpoint Switching in Multi-view Video Streaming Using Wyner-Ziv Video Coding Xun Guo 1,, Yan Lu 2, Feng Wu 2, Wen Gao 1, 3, Shipeng Li 2 1 School of Computer Sciences, Harbin Institute of Technology,
Free Viewpoint Switching in Multi-view Video Streaming Using Wyner-Ziv Video Coding Xun Guo 1,, Yan Lu 2, Feng Wu 2, Wen Gao 1, 3, Shipeng Li 2 1 School of Computer Sciences, Harbin Institute of Technology,
A CLASSIFICATION-BASED POLYPHONIC PIANO TRANSCRIPTION APPROACH USING LEARNED FEATURE REPRESENTATIONS
 12th International Society for Music Information Retrieval Conference (ISMIR 2011) A CLASSIFICATION-BASED POLYPHONIC PIANO TRANSCRIPTION APPROACH USING LEARNED FEATURE REPRESENTATIONS Juhan Nam Stanford
12th International Society for Music Information Retrieval Conference (ISMIR 2011) A CLASSIFICATION-BASED POLYPHONIC PIANO TRANSCRIPTION APPROACH USING LEARNED FEATURE REPRESENTATIONS Juhan Nam Stanford
A PROBABILISTIC TOPIC MODEL FOR UNSUPERVISED LEARNING OF MUSICAL KEY-PROFILES
 A PROBABILISTIC TOPIC MODEL FOR UNSUPERVISED LEARNING OF MUSICAL KEY-PROFILES Diane J. Hu and Lawrence K. Saul Department of Computer Science and Engineering University of California, San Diego {dhu,saul}@cs.ucsd.edu
A PROBABILISTIC TOPIC MODEL FOR UNSUPERVISED LEARNING OF MUSICAL KEY-PROFILES Diane J. Hu and Lawrence K. Saul Department of Computer Science and Engineering University of California, San Diego {dhu,saul}@cs.ucsd.edu
Supervised Learning in Genre Classification
 Supervised Learning in Genre Classification Introduction & Motivation Mohit Rajani and Luke Ekkizogloy {i.mohit,luke.ekkizogloy}@gmail.com Stanford University, CS229: Machine Learning, 2009 Now that music
Supervised Learning in Genre Classification Introduction & Motivation Mohit Rajani and Luke Ekkizogloy {i.mohit,luke.ekkizogloy}@gmail.com Stanford University, CS229: Machine Learning, 2009 Now that music
arxiv: v2 [cs.sd] 15 Jun 2017
![arxiv: v2 [cs.sd] 15 Jun 2017](/thumbs/80/81731083.jpg "arxiv: v2 [cs.sd] 15 Jun 2017") Learning and Evaluating Musical Features with Deep Autoencoders Mason Bretan Georgia Tech Atlanta, GA Sageev Oore, Douglas Eck, Larry Heck Google Research Mountain View, CA arxiv:1706.04486v2 [cs.sd] 15
Learning and Evaluating Musical Features with Deep Autoencoders Mason Bretan Georgia Tech Atlanta, GA Sageev Oore, Douglas Eck, Larry Heck Google Research Mountain View, CA arxiv:1706.04486v2 [cs.sd] 15
CS229 Project Report Polyphonic Piano Transcription
 CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
CS229 Project Report Polyphonic Piano Transcription Mohammad Sadegh Ebrahimi Stanford University Jean-Baptiste Boin Stanford University sadegh@stanford.edu jbboin@stanford.edu 1. Introduction In this project
Predicting the immediate future with Recurrent Neural Networks: Pre-training and Applications
 Predicting the immediate future with Recurrent Neural Networks: Pre-training and Applications Introduction Brandon Richardson December 16, 2011 Research preformed from the last 5 years has shown that the
Predicting the immediate future with Recurrent Neural Networks: Pre-training and Applications Introduction Brandon Richardson December 16, 2011 Research preformed from the last 5 years has shown that the
Detecting Musical Key with Supervised Learning
 Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
Structured training for large-vocabulary chord recognition. Brian McFee* & Juan Pablo Bello
 Structured training for large-vocabulary chord recognition Brian McFee* & Juan Pablo Bello Small chord vocabularies Typically a supervised learning problem N C:maj C:min C#:maj C#:min D:maj D:min......
Structured training for large-vocabulary chord recognition Brian McFee* & Juan Pablo Bello Small chord vocabularies Typically a supervised learning problem N C:maj C:min C#:maj C#:min D:maj D:min......
Image Aesthetics Assessment using Deep Chatterjee s Machine
 Image Aesthetics Assessment using Deep Chatterjee s Machine Zhangyang Wang, Ding Liu, Shiyu Chang, Florin Dolcos, Diane Beck, Thomas Huang Department of Computer Science and Engineering, Texas A&M University,
Image Aesthetics Assessment using Deep Chatterjee s Machine Zhangyang Wang, Ding Liu, Shiyu Chang, Florin Dolcos, Diane Beck, Thomas Huang Department of Computer Science and Engineering, Texas A&M University,
PaletteNet: Image Recolorization with Given Color Palette
 PaletteNet: Image Recolorization with Given Color Palette Junho Cho, Sangdoo Yun, Kyoungmu Lee, Jin Young Choi ASRI, Dept. of Electrical and Computer Eng., Seoul National University {junhocho, yunsd101,
PaletteNet: Image Recolorization with Given Color Palette Junho Cho, Sangdoo Yun, Kyoungmu Lee, Jin Young Choi ASRI, Dept. of Electrical and Computer Eng., Seoul National University {junhocho, yunsd101,
Adaptive Key Frame Selection for Efficient Video Coding
 Adaptive Key Frame Selection for Efficient Video Coding Jaebum Jun, Sunyoung Lee, Zanming He, Myungjung Lee, and Euee S. Jang Digital Media Lab., Hanyang University 17 Haengdang-dong, Seongdong-gu, Seoul,
Adaptive Key Frame Selection for Efficient Video Coding Jaebum Jun, Sunyoung Lee, Zanming He, Myungjung Lee, and Euee S. Jang Digital Media Lab., Hanyang University 17 Haengdang-dong, Seongdong-gu, Seoul,
Singer Traits Identification using Deep Neural Network
 Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Personalized TV Recommendation with Mixture Probabilistic Matrix Factorization
 Personalized TV Recommendation with Mixture Probabilistic Matrix Factorization Huayu Li Hengshu Zhu Yong Ge Yanjie Fu Yuan Ge ± Abstract With the rapid development of smart TV industry, a large number
Personalized TV Recommendation with Mixture Probabilistic Matrix Factorization Huayu Li Hengshu Zhu Yong Ge Yanjie Fu Yuan Ge ± Abstract With the rapid development of smart TV industry, a large number
Color Image Compression Using Colorization Based On Coding Technique
 Color Image Compression Using Colorization Based On Coding Technique D.P.Kawade 1, Prof. S.N.Rawat 2 1,2 Department of Electronics and Telecommunication, Bhivarabai Sawant Institute of Technology and Research
Color Image Compression Using Colorization Based On Coding Technique D.P.Kawade 1, Prof. S.N.Rawat 2 1,2 Department of Electronics and Telecommunication, Bhivarabai Sawant Institute of Technology and Research
Lecture 9 Source Separation
 10420CS 573100 音樂資訊檢索 Music Information Retrieval Lecture 9 Source Separation Yi-Hsuan Yang Ph.D. http://www.citi.sinica.edu.tw/pages/yang/ yang@citi.sinica.edu.tw Music & Audio Computing Lab, Research
10420CS 573100 音樂資訊檢索 Music Information Retrieval Lecture 9 Source Separation Yi-Hsuan Yang Ph.D. http://www.citi.sinica.edu.tw/pages/yang/ yang@citi.sinica.edu.tw Music & Audio Computing Lab, Research
Optimized Color Based Compression
 Optimized Color Based Compression 1 K.P.SONIA FENCY, 2 C.FELSY 1 PG Student, Department Of Computer Science Ponjesly College Of Engineering Nagercoil,Tamilnadu, India 2 Asst. Professor, Department Of Computer
Optimized Color Based Compression 1 K.P.SONIA FENCY, 2 C.FELSY 1 PG Student, Department Of Computer Science Ponjesly College Of Engineering Nagercoil,Tamilnadu, India 2 Asst. Professor, Department Of Computer
Classical Music Generation in Distinct Dastgahs with AlimNet ACGAN
 Classical Music Generation in Distinct Dastgahs with AlimNet ACGAN Saber Malekzadeh Computer Science Department University of Tabriz Tabriz, Iran Saber.Malekzadeh@sru.ac.ir Maryam Samami Islamic Azad University,
Classical Music Generation in Distinct Dastgahs with AlimNet ACGAN Saber Malekzadeh Computer Science Department University of Tabriz Tabriz, Iran Saber.Malekzadeh@sru.ac.ir Maryam Samami Islamic Azad University,
Modeling Temporal Tonal Relations in Polyphonic Music Through Deep Networks with a Novel Image-Based Representation
 INTRODUCTION Modeling Temporal Tonal Relations in Polyphonic Music Through Deep Networks with a Novel Image-Based Representation Ching-Hua Chuan 1, 2 1 University of North Florida 2 University of Miami
INTRODUCTION Modeling Temporal Tonal Relations in Polyphonic Music Through Deep Networks with a Novel Image-Based Representation Ching-Hua Chuan 1, 2 1 University of North Florida 2 University of Miami
Compressed-Sensing-Enabled Video Streaming for Wireless Multimedia Sensor Networks Abstract:
 Compressed-Sensing-Enabled Video Streaming for Wireless Multimedia Sensor Networks Abstract: This article1 presents the design of a networked system for joint compression, rate control and error correction
Compressed-Sensing-Enabled Video Streaming for Wireless Multimedia Sensor Networks Abstract: This article1 presents the design of a networked system for joint compression, rate control and error correction
arxiv: v1 [cs.cv] 9 Apr 2018
![arxiv: v1 [cs.cv] 9 Apr 2018](/thumbs/80/81675071.jpg "arxiv: v1 [cs.cv] 9 Apr 2018") arxiv:1804.03160v1 [cs.cv] 9 Apr 2018 The Sound of Pixels Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick Josh McDermott, and Antonio Torralba Massachusetts Institute of Technology Abstract.
arxiv:1804.03160v1 [cs.cv] 9 Apr 2018 The Sound of Pixels Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick Josh McDermott, and Antonio Torralba Massachusetts Institute of Technology Abstract.
arxiv: v1 [cs.sd] 5 Apr 2017
![arxiv: v1 [cs.sd] 5 Apr 2017](/thumbs/77/76093321.jpg "arxiv: v1 [cs.sd] 5 Apr 2017") REVISITING THE PROBLEM OF AUDIO-BASED HIT SONG PREDICTION USING CONVOLUTIONAL NEURAL NETWORKS Li-Chia Yang, Szu-Yu Chou, Jen-Yu Liu, Yi-Hsuan Yang, Yi-An Chen Research Center for Information Technology
REVISITING THE PROBLEM OF AUDIO-BASED HIT SONG PREDICTION USING CONVOLUTIONAL NEURAL NETWORKS Li-Chia Yang, Szu-Yu Chou, Jen-Yu Liu, Yi-Hsuan Yang, Yi-An Chen Research Center for Information Technology
IMAGE AESTHETIC PREDICTORS BASED ON WEIGHTED CNNS. Oce Print Logic Technologies, Creteil, France
 IMAGE AESTHETIC PREDICTORS BASED ON WEIGHTED CNNS Bin Jin, Maria V. Ortiz Segovia2 and Sabine Su sstrunk EPFL, Lausanne, Switzerland; 2 Oce Print Logic Technologies, Creteil, France ABSTRACT Convolutional
IMAGE AESTHETIC PREDICTORS BASED ON WEIGHTED CNNS Bin Jin, Maria V. Ortiz Segovia2 and Sabine Su sstrunk EPFL, Lausanne, Switzerland; 2 Oce Print Logic Technologies, Creteil, France ABSTRACT Convolutional
Interactive multiview video system with non-complex navigation at the decoder
 1 Interactive multiview video system with non-complex navigation at the decoder Thomas Maugey and Pascal Frossard Signal Processing Laboratory (LTS4) École Polytechnique Fédérale de Lausanne (EPFL), Lausanne,
1 Interactive multiview video system with non-complex navigation at the decoder Thomas Maugey and Pascal Frossard Signal Processing Laboratory (LTS4) École Polytechnique Fédérale de Lausanne (EPFL), Lausanne,
A Novel Approach towards Video Compression for Mobile Internet using Transform Domain Technique
 A Novel Approach towards Video Compression for Mobile Internet using Transform Domain Technique Dhaval R. Bhojani Research Scholar, Shri JJT University, Jhunjunu, Rajasthan, India Ved Vyas Dwivedi, PhD.
A Novel Approach towards Video Compression for Mobile Internet using Transform Domain Technique Dhaval R. Bhojani Research Scholar, Shri JJT University, Jhunjunu, Rajasthan, India Ved Vyas Dwivedi, PhD.
1. INTRODUCTION. Index Terms Video Transcoding, Video Streaming, Frame skipping, Interpolation frame, Decoder, Encoder.
 Video Streaming Based on Frame Skipping and Interpolation Techniques Fadlallah Ali Fadlallah Department of Computer Science Sudan University of Science and Technology Khartoum-SUDAN fadali@sustech.edu
Video Streaming Based on Frame Skipping and Interpolation Techniques Fadlallah Ali Fadlallah Department of Computer Science Sudan University of Science and Technology Khartoum-SUDAN fadali@sustech.edu
Embedding Multilevel Image Encryption in the LAR Codec
 Embedding Multilevel Image Encryption in the LAR Codec Jean Motsch, Olivier Déforges, Marie Babel To cite this version: Jean Motsch, Olivier Déforges, Marie Babel. Embedding Multilevel Image Encryption
Embedding Multilevel Image Encryption in the LAR Codec Jean Motsch, Olivier Déforges, Marie Babel To cite this version: Jean Motsch, Olivier Déforges, Marie Babel. Embedding Multilevel Image Encryption
Google s Cloud Vision API Is Not Robust To Noise
 Google s Cloud Vision API Is Not Robust To Noise Hossein Hosseini, Baicen Xiao and Radha Poovendran Network Security Lab (NSL), Department of Electrical Engineering, University of Washington, Seattle,
Google s Cloud Vision API Is Not Robust To Noise Hossein Hosseini, Baicen Xiao and Radha Poovendran Network Security Lab (NSL), Department of Electrical Engineering, University of Washington, Seattle,
Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj
 Bhiksha Raj") Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj 1 Story so far MLPs are universal function approximators Boolean functions, classifiers, and regressions MLPs can be
Deep Neural Networks Scanning for patterns (aka convolutional networks) Bhiksha Raj 1 Story so far MLPs are universal function approximators Boolean functions, classifiers, and regressions MLPs can be
Representations of Sound in Deep Learning of Audio Features from Music
 Representations of Sound in Deep Learning of Audio Features from Music Sergey Shuvaev, Hamza Giaffar, and Alexei A. Koulakov Cold Spring Harbor Laboratory, Cold Spring Harbor, NY Abstract The work of a
Representations of Sound in Deep Learning of Audio Features from Music Sergey Shuvaev, Hamza Giaffar, and Alexei A. Koulakov Cold Spring Harbor Laboratory, Cold Spring Harbor, NY Abstract The work of a
OPTICAL MUSIC RECOGNITION WITH CONVOLUTIONAL SEQUENCE-TO-SEQUENCE MODELS
 OPTICAL MUSIC RECOGNITION WITH CONVOLUTIONAL SEQUENCE-TO-SEQUENCE MODELS First Author Affiliation1 author1@ismir.edu Second Author Retain these fake authors in submission to preserve the formatting Third
OPTICAL MUSIC RECOGNITION WITH CONVOLUTIONAL SEQUENCE-TO-SEQUENCE MODELS First Author Affiliation1 author1@ismir.edu Second Author Retain these fake authors in submission to preserve the formatting Third
Automatic Music Clustering using Audio Attributes
 Automatic Music Clustering using Audio Attributes Abhishek Sen BTech (Electronics) Veermata Jijabai Technological Institute (VJTI), Mumbai, India abhishekpsen@gmail.com Abstract Music brings people together,
Automatic Music Clustering using Audio Attributes Abhishek Sen BTech (Electronics) Veermata Jijabai Technological Institute (VJTI), Mumbai, India abhishekpsen@gmail.com Abstract Music brings people together,
arxiv: v1 [cs.ir] 16 Jan 2019
![arxiv: v1 [cs.ir] 16 Jan 2019](/thumbs/88/116091101.jpg "arxiv: v1 [cs.ir] 16 Jan 2019") It s Only Words And Words Are All I Have Manash Pratim Barman 1, Kavish Dahekar 2, Abhinav Anshuman 3, and Amit Awekar 4 1 Indian Institute of Information Technology, Guwahati 2 SAP Labs, Bengaluru 3 Dell
It s Only Words And Words Are All I Have Manash Pratim Barman 1, Kavish Dahekar 2, Abhinav Anshuman 3, and Amit Awekar 4 1 Indian Institute of Information Technology, Guwahati 2 SAP Labs, Bengaluru 3 Dell
Automatic Extraction of Popular Music Ringtones Based on Music Structure Analysis
 Automatic Extraction of Popular Music Ringtones Based on Music Structure Analysis Fengyan Wu fengyanyy@163.com Shutao Sun stsun@cuc.edu.cn Weiyao Xue Wyxue_std@163.com Abstract Automatic extraction of
Automatic Extraction of Popular Music Ringtones Based on Music Structure Analysis Fengyan Wu fengyanyy@163.com Shutao Sun stsun@cuc.edu.cn Weiyao Xue Wyxue_std@163.com Abstract Automatic extraction of
Improving Performance in Neural Networks Using a Boosting Algorithm
 - Improving Performance in Neural Networks Using a Boosting Algorithm Harris Drucker AT&T Bell Laboratories Holmdel, NJ 07733 Robert Schapire AT&T Bell Laboratories Murray Hill, NJ 07974 Patrice Simard
- Improving Performance in Neural Networks Using a Boosting Algorithm Harris Drucker AT&T Bell Laboratories Holmdel, NJ 07733 Robert Schapire AT&T Bell Laboratories Murray Hill, NJ 07974 Patrice Simard
arxiv: v3 [cs.lg] 6 Oct 2018
![arxiv: v3 [cs.lg] 6 Oct 2018](/thumbs/88/115051173.jpg "arxiv: v3 [cs.lg] 6 Oct 2018") CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS WITH BINARY NEURONS FOR POLYPHONIC MUSIC GENERATION Hao-Wen Dong and Yi-Hsuan Yang Research Center for IT innovation, Academia Sinica, Taipei, Taiwan {salu133445,yang}@citi.sinica.edu.tw
CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS WITH BINARY NEURONS FOR POLYPHONIC MUSIC GENERATION Hao-Wen Dong and Yi-Hsuan Yang Research Center for IT innovation, Academia Sinica, Taipei, Taiwan {salu133445,yang}@citi.sinica.edu.tw
arxiv: v1 [cs.cv] 2 Nov 2017
![arxiv: v1 [cs.cv] 2 Nov 2017](/thumbs/71/65844936.jpg "arxiv: v1 [cs.cv] 2 Nov 2017") Understanding and Predicting The Attractiveness of Human Action Shot Bin Dai Institute for Advanced Study, Tsinghua University, Beijing, China daib13@mails.tsinghua.edu.cn Baoyuan Wang Microsoft Research,
Understanding and Predicting The Attractiveness of Human Action Shot Bin Dai Institute for Advanced Study, Tsinghua University, Beijing, China daib13@mails.tsinghua.edu.cn Baoyuan Wang Microsoft Research,
Experiments on musical instrument separation using multiplecause
 Experiments on musical instrument separation using multiplecause models J Klingseisen and M D Plumbley* Department of Electronic Engineering King's College London * - Corresponding Author - mark.plumbley@kcl.ac.uk
Experiments on musical instrument separation using multiplecause models J Klingseisen and M D Plumbley* Department of Electronic Engineering King's College London * - Corresponding Author - mark.plumbley@kcl.ac.uk
ERROR CONCEALMENT TECHNIQUES IN H.264 VIDEO TRANSMISSION OVER WIRELESS NETWORKS
 Multimedia Processing Term project on ERROR CONCEALMENT TECHNIQUES IN H.264 VIDEO TRANSMISSION OVER WIRELESS NETWORKS Interim Report Spring 2016 Under Dr. K. R. Rao by Moiz Mustafa Zaveri (1001115920)
Multimedia Processing Term project on ERROR CONCEALMENT TECHNIQUES IN H.264 VIDEO TRANSMISSION OVER WIRELESS NETWORKS Interim Report Spring 2016 Under Dr. K. R. Rao by Moiz Mustafa Zaveri (1001115920)
Deep Jammer: A Music Generation Model
 Deep Jammer: A Music Generation Model Justin Svegliato and Sam Witty College of Information and Computer Sciences University of Massachusetts Amherst, MA 01003, USA {jsvegliato,switty}@cs.umass.edu Abstract
Deep Jammer: A Music Generation Model Justin Svegliato and Sam Witty College of Information and Computer Sciences University of Massachusetts Amherst, MA 01003, USA {jsvegliato,switty}@cs.umass.edu Abstract
An AI Approach to Automatic Natural Music Transcription
 An AI Approach to Automatic Natural Music Transcription Michael Bereket Stanford University Stanford, CA mbereket@stanford.edu Karey Shi Stanford Univeristy Stanford, CA kareyshi@stanford.edu Abstract
An AI Approach to Automatic Natural Music Transcription Michael Bereket Stanford University Stanford, CA mbereket@stanford.edu Karey Shi Stanford Univeristy Stanford, CA kareyshi@stanford.edu Abstract
Automatic Piano Music Transcription
 Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Music Mood. Sheng Xu, Albert Peyton, Ryan Bhular
 Music Mood Sheng Xu, Albert Peyton, Ryan Bhular What is Music Mood A psychological & musical topic Human emotions conveyed in music can be comprehended from two aspects: Lyrics Music Factors that affect
Music Mood Sheng Xu, Albert Peyton, Ryan Bhular What is Music Mood A psychological & musical topic Human emotions conveyed in music can be comprehended from two aspects: Lyrics Music Factors that affect
Supplementary material for Inverting Visual Representations with Convolutional Networks
 Supplementary material for Inverting Visual Representations with Convolutional Networks Alexey Dosovitskiy Thomas Brox University of Freiburg Freiburg im Breisgau, Germany {dosovits,brox}@cs.uni-freiburg.de
Supplementary material for Inverting Visual Representations with Convolutional Networks Alexey Dosovitskiy Thomas Brox University of Freiburg Freiburg im Breisgau, Germany {dosovits,brox}@cs.uni-freiburg.de
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng
 Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the
A Transfer Learning Based Feature Extractor for Polyphonic Sound Event Detection Using Connectionist Temporal Classification
 INTERSPEECH 17 August, 17, Stockholm, Sweden A Transfer Learning Based Feature Extractor for Polyphonic Sound Event Detection Using Connectionist Temporal Classification Yun Wang and Florian Metze Language
INTERSPEECH 17 August, 17, Stockholm, Sweden A Transfer Learning Based Feature Extractor for Polyphonic Sound Event Detection Using Connectionist Temporal Classification Yun Wang and Florian Metze Language
UNIVERSAL SPATIAL UP-SCALER WITH NONLINEAR EDGE ENHANCEMENT
 UNIVERSAL SPATIAL UP-SCALER WITH NONLINEAR EDGE ENHANCEMENT Stefan Schiemenz, Christian Hentschel Brandenburg University of Technology, Cottbus, Germany ABSTRACT Spatial image resizing is an important
UNIVERSAL SPATIAL UP-SCALER WITH NONLINEAR EDGE ENHANCEMENT Stefan Schiemenz, Christian Hentschel Brandenburg University of Technology, Cottbus, Germany ABSTRACT Spatial image resizing is an important
An Image Compression Technique Based on the Novel Approach of Colorization Based Coding
 An Image Compression Technique Based on the Novel Approach of Colorization Based Coding Shireen Fathima 1, E Kavitha 2 PG Student [M.Tech in Electronics], Dept. of ECE, HKBK College of Engineering, Bangalore,
An Image Compression Technique Based on the Novel Approach of Colorization Based Coding Shireen Fathima 1, E Kavitha 2 PG Student [M.Tech in Electronics], Dept. of ECE, HKBK College of Engineering, Bangalore,
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes
 Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
Real-valued parametric conditioning of an RNN for interactive sound synthesis
 Real-valued parametric conditioning of an RNN for interactive sound synthesis Lonce Wyse Communications and New Media Department National University of Singapore Singapore lonce.acad@zwhome.org Abstract
Real-valued parametric conditioning of an RNN for interactive sound synthesis Lonce Wyse Communications and New Media Department National University of Singapore Singapore lonce.acad@zwhome.org Abstract
Implementation of an MPEG Codec on the Tilera TM 64 Processor
 1 Implementation of an MPEG Codec on the Tilera TM 64 Processor Whitney Flohr Supervisor: Mark Franklin, Ed Richter Department of Electrical and Systems Engineering Washington University in St. Louis Fall
1 Implementation of an MPEG Codec on the Tilera TM 64 Processor Whitney Flohr Supervisor: Mark Franklin, Ed Richter Department of Electrical and Systems Engineering Washington University in St. Louis Fall
Hidden Markov Model based dance recognition
 Hidden Markov Model based dance recognition Dragutin Hrenek, Nenad Mikša, Robert Perica, Pavle Prentašić and Boris Trubić University of Zagreb, Faculty of Electrical Engineering and Computing Unska 3,
Hidden Markov Model based dance recognition Dragutin Hrenek, Nenad Mikša, Robert Perica, Pavle Prentašić and Boris Trubić University of Zagreb, Faculty of Electrical Engineering and Computing Unska 3,
Satoshi Iizuka* Edgar Simo-Serra* Hiroshi Ishikawa Waseda University. (*equal contribution)
") Satoshi Iizuka* Edgar Simo-Serra* Hiroshi Ishikawa Waseda University (*equal contribution) Colorization of Black-and-white Pictures 2 Our Goal: Fully-automatic colorization 3 Colorization of Old Films
Satoshi Iizuka* Edgar Simo-Serra* Hiroshi Ishikawa Waseda University (*equal contribution) Colorization of Black-and-white Pictures 2 Our Goal: Fully-automatic colorization 3 Colorization of Old Films
Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn
 Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn Introduction Active neurons communicate by action potential firing (spikes), accompanied
Reconstruction of Ca 2+ dynamics from low frame rate Ca 2+ imaging data CS229 final project. Submitted by: Limor Bursztyn Introduction Active neurons communicate by action potential firing (spikes), accompanied
CHORD GENERATION FROM SYMBOLIC MELODY USING BLSTM NETWORKS
 CHORD GENERATION FROM SYMBOLIC MELODY USING BLSTM NETWORKS Hyungui Lim 1,2, Seungyeon Rhyu 1 and Kyogu Lee 1,2 3 Music and Audio Research Group, Graduate School of Convergence Science and Technology 4
CHORD GENERATION FROM SYMBOLIC MELODY USING BLSTM NETWORKS Hyungui Lim 1,2, Seungyeon Rhyu 1 and Kyogu Lee 1,2 3 Music and Audio Research Group, Graduate School of Convergence Science and Technology 4
arxiv: v1 [cs.cv] 1 Aug 2017
![arxiv: v1 [cs.cv] 1 Aug 2017](/thumbs/95/123913902.jpg "arxiv: v1 [cs.cv] 1 Aug 2017") Real-time Deep Video Deinterlacing HAICHAO ZHU, The Chinese University of Hong Kong XUETING LIU, The Chinese University of Hong Kong XIANGYU MAO, The Chinese University of Hong Kong TIEN-TSIN WONG, The
Real-time Deep Video Deinterlacing HAICHAO ZHU, The Chinese University of Hong Kong XUETING LIU, The Chinese University of Hong Kong XIANGYU MAO, The Chinese University of Hong Kong TIEN-TSIN WONG, The
Chord Classification of an Audio Signal using Artificial Neural Network
 Chord Classification of an Audio Signal using Artificial Neural Network Ronesh Shrestha Student, Department of Electrical and Electronic Engineering, Kathmandu University, Dhulikhel, Nepal ---------------------------------------------------------------------***---------------------------------------------------------------------
Chord Classification of an Audio Signal using Artificial Neural Network Ronesh Shrestha Student, Department of Electrical and Electronic Engineering, Kathmandu University, Dhulikhel, Nepal ---------------------------------------------------------------------***---------------------------------------------------------------------
Inverse Filtering by Signal Reconstruction from Phase. Megan M. Fuller
 Inverse Filtering by Signal Reconstruction from Phase by Megan M. Fuller B.S. Electrical Engineering Brigham Young University, 2012 Submitted to the Department of Electrical Engineering and Computer Science
Inverse Filtering by Signal Reconstruction from Phase by Megan M. Fuller B.S. Electrical Engineering Brigham Young University, 2012 Submitted to the Department of Electrical Engineering and Computer Science
Scene Classification with Inception-7. Christian Szegedy with Julian Ibarz and Vincent Vanhoucke
 Scene Classification with Inception-7 Christian Szegedy with Julian Ibarz and Vincent Vanhoucke Julian Ibarz Vincent Vanhoucke Task Classification of images into 10 different classes: Bedroom Bridge Church
Scene Classification with Inception-7 Christian Szegedy with Julian Ibarz and Vincent Vanhoucke Julian Ibarz Vincent Vanhoucke Task Classification of images into 10 different classes: Bedroom Bridge Church
Multichannel Satellite Image Resolution Enhancement Using Dual-Tree Complex Wavelet Transform and NLM Filtering
 Multichannel Satellite Image Resolution Enhancement Using Dual-Tree Complex Wavelet Transform and NLM Filtering P.K Ragunath 1, A.Balakrishnan 2 M.E, Karpagam University, Coimbatore, India 1 Asst Professor,
Multichannel Satellite Image Resolution Enhancement Using Dual-Tree Complex Wavelet Transform and NLM Filtering P.K Ragunath 1, A.Balakrishnan 2 M.E, Karpagam University, Coimbatore, India 1 Asst Professor,
Audio-Based Video Editing with Two-Channel Microphone
 Audio-Based Video Editing with Two-Channel Microphone Tetsuya Takiguchi Organization of Advanced Science and Technology Kobe University, Japan takigu@kobe-u.ac.jp Yasuo Ariki Organization of Advanced Science
Audio-Based Video Editing with Two-Channel Microphone Tetsuya Takiguchi Organization of Advanced Science and Technology Kobe University, Japan takigu@kobe-u.ac.jp Yasuo Ariki Organization of Advanced Science
CS 1674: Intro to Computer Vision. Intro to Recognition. Prof. Adriana Kovashka University of Pittsburgh October 24, 2016
 CS 1674: Intro to Computer Vision Intro to Recognition Prof. Adriana Kovashka University of Pittsburgh October 24, 2016 Plan for today Examples of visual recognition problems What should we recognize?
CS 1674: Intro to Computer Vision Intro to Recognition Prof. Adriana Kovashka University of Pittsburgh October 24, 2016 Plan for today Examples of visual recognition problems What should we recognize?
USING A GENERATIVE ADVERSARIAL NETWORK TO EXPLORE THE NEW AESTHETIC. Angela May Xie
 USING A GENERATIVE ADVERSARIAL NETWORK TO EXPLORE THE NEW AESTHETIC Angela May Xie CS 379H Department of Computer Science The University of Texas at Austin TC 660H Plan II Honors Program The University
USING A GENERATIVE ADVERSARIAL NETWORK TO EXPLORE THE NEW AESTHETIC Angela May Xie CS 379H Department of Computer Science The University of Texas at Austin TC 660H Plan II Honors Program The University
PERCEPTUAL QUALITY OF H.264/AVC DEBLOCKING FILTER
 PERCEPTUAL QUALITY OF H./AVC DEBLOCKING FILTER Y. Zhong, I. Richardson, A. Miller and Y. Zhao School of Enginnering, The Robert Gordon University, Schoolhill, Aberdeen, AB1 1FR, UK Phone: + 1, Fax: + 1,
PERCEPTUAL QUALITY OF H./AVC DEBLOCKING FILTER Y. Zhong, I. Richardson, A. Miller and Y. Zhao School of Enginnering, The Robert Gordon University, Schoolhill, Aberdeen, AB1 1FR, UK Phone: + 1, Fax: + 1,
Audio Cover Song Identification using Convolutional Neural Network
 Audio Cover Song Identification using Convolutional Neural Network Sungkyun Chang 1,4, Juheon Lee 2,4, Sang Keun Choe 3,4 and Kyogu Lee 1,4 Music and Audio Research Group 1, College of Liberal Studies
Audio Cover Song Identification using Convolutional Neural Network Sungkyun Chang 1,4, Juheon Lee 2,4, Sang Keun Choe 3,4 and Kyogu Lee 1,4 Music and Audio Research Group 1, College of Liberal Studies
arxiv: v1 [cs.cv] 16 Jul 2017
![arxiv: v1 [cs.cv] 16 Jul 2017](/thumbs/72/67002892.jpg "arxiv: v1 [cs.cv] 16 Jul 2017") OPTICAL MUSIC RECOGNITION WITH CONVOLUTIONAL SEQUENCE-TO-SEQUENCE MODELS Eelco van der Wel University of Amsterdam eelcovdw@gmail.com Karen Ullrich University of Amsterdam karen.ullrich@uva.nl arxiv:1707.04877v1
OPTICAL MUSIC RECOGNITION WITH CONVOLUTIONAL SEQUENCE-TO-SEQUENCE MODELS Eelco van der Wel University of Amsterdam eelcovdw@gmail.com Karen Ullrich University of Amsterdam karen.ullrich@uva.nl arxiv:1707.04877v1
MPEG has been established as an international standard
 1100 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 9, NO. 7, OCTOBER 1999 Fast Extraction of Spatially Reduced Image Sequences from MPEG-2 Compressed Video Junehwa Song, Member,
1100 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 9, NO. 7, OCTOBER 1999 Fast Extraction of Spatially Reduced Image Sequences from MPEG-2 Compressed Video Junehwa Song, Member,
arxiv: v2 [cs.cv] 27 Jul 2016
![arxiv: v2 [cs.cv] 27 Jul 2016](/thumbs/78/77625577.jpg "arxiv: v2 [cs.cv] 27 Jul 2016") arxiv:1606.01621v2 [cs.cv] 27 Jul 2016 Photo Aesthetics Ranking Network with Attributes and Adaptation Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, Charless Fowlkes UC Irvine Adobe {skong2,fowlkes}@ics.uci.edu
arxiv:1606.01621v2 [cs.cv] 27 Jul 2016 Photo Aesthetics Ranking Network with Attributes and Adaptation Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, Charless Fowlkes UC Irvine Adobe {skong2,fowlkes}@ics.uci.edu
A QUERY BY EXAMPLE MUSIC RETRIEVAL ALGORITHM
 A QUER B EAMPLE MUSIC RETRIEVAL ALGORITHM H. HARB AND L. CHEN Maths-Info department, Ecole Centrale de Lyon. 36, av. Guy de Collongue, 69134, Ecully, France, EUROPE E-mail: {hadi.harb, liming.chen}@ec-lyon.fr
A QUER B EAMPLE MUSIC RETRIEVAL ALGORITHM H. HARB AND L. CHEN Maths-Info department, Ecole Centrale de Lyon. 36, av. Guy de Collongue, 69134, Ecully, France, EUROPE E-mail: {hadi.harb, liming.chen}@ec-lyon.fr
Convolutional Neural Network-Based Block Up-sampling for Intra Frame Coding
 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY 1 Convolutional Neural Network-Based Block Up-sampling for Intra Frame Coding Yue Li, Dong Liu, Member, IEEE, Houqiang Li, Senior Member,
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY 1 Convolutional Neural Network-Based Block Up-sampling for Intra Frame Coding Yue Li, Dong Liu, Member, IEEE, Houqiang Li, Senior Member,
Less is More: Picking Informative Frames for Video Captioning
 Less is More: Picking Informative Frames for Video Captioning ECCV 2018 Yangyu Chen 1, Shuhui Wang 2, Weigang Zhang 3 and Qingming Huang 1,2 1 University of Chinese Academy of Science, Beijing, 100049,
Less is More: Picking Informative Frames for Video Captioning ECCV 2018 Yangyu Chen 1, Shuhui Wang 2, Weigang Zhang 3 and Qingming Huang 1,2 1 University of Chinese Academy of Science, Beijing, 100049,
Constant Bit Rate for Video Streaming Over Packet Switching Networks
 International OPEN ACCESS Journal Of Modern Engineering Research (IJMER) Constant Bit Rate for Video Streaming Over Packet Switching Networks Mr. S. P.V Subba rao 1, Y. Renuka Devi 2 Associate professor
International OPEN ACCESS Journal Of Modern Engineering Research (IJMER) Constant Bit Rate for Video Streaming Over Packet Switching Networks Mr. S. P.V Subba rao 1, Y. Renuka Devi 2 Associate professor
arxiv: v2 [eess.as] 24 Nov 2017
![arxiv: v2 [eess.as] 24 Nov 2017](/thumbs/79/79340147.jpg "arxiv: v2 [eess.as] 24 Nov 2017") MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment Hao-Wen Dong, 1 Wen-Yi Hsiao, 1,2 Li-Chia Yang, 1 Yi-Hsuan Yang 1 1 Research Center for Information
MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment Hao-Wen Dong, 1 Wen-Yi Hsiao, 1,2 Li-Chia Yang, 1 Yi-Hsuan Yang 1 1 Research Center for Information
Implementation of CRC and Viterbi algorithm on FPGA
 Implementation of CRC and Viterbi algorithm on FPGA S. V. Viraktamath 1, Akshata Kotihal 2, Girish V. Attimarad 3 1 Faculty, 2 Student, Dept of ECE, SDMCET, Dharwad, 3 HOD Department of E&CE, Dayanand
Implementation of CRC and Viterbi algorithm on FPGA S. V. Viraktamath 1, Akshata Kotihal 2, Girish V. Attimarad 3 1 Faculty, 2 Student, Dept of ECE, SDMCET, Dharwad, 3 HOD Department of E&CE, Dayanand
Enabling editors through machine learning
 Meta Follow Meta is an AI company that provides academics & innovation-driven companies with powerful views of t Dec 9, 2016 9 min read Enabling editors through machine learning Examining the data science
Meta Follow Meta is an AI company that provides academics & innovation-driven companies with powerful views of t Dec 9, 2016 9 min read Enabling editors through machine learning Examining the data science
CS 1674: Intro to Computer Vision. Face Detection. Prof. Adriana Kovashka University of Pittsburgh November 7, 2016
 CS 1674: Intro to Computer Vision Face Detection Prof. Adriana Kovashka University of Pittsburgh November 7, 2016 Today Window-based generic object detection basic pipeline boosting classifiers face detection
CS 1674: Intro to Computer Vision Face Detection Prof. Adriana Kovashka University of Pittsburgh November 7, 2016 Today Window-based generic object detection basic pipeline boosting classifiers face detection
Computational Modelling of Harmony
 Computational Modelling of Harmony Simon Dixon Centre for Digital Music, Queen Mary University of London, Mile End Rd, London E1 4NS, UK simon.dixon@elec.qmul.ac.uk http://www.elec.qmul.ac.uk/people/simond
Computational Modelling of Harmony Simon Dixon Centre for Digital Music, Queen Mary University of London, Mile End Rd, London E1 4NS, UK simon.dixon@elec.qmul.ac.uk http://www.elec.qmul.ac.uk/people/simond