Learning the meaning of music
|
|
|
- Roger Beasley
- 6 years ago
- Views:
Transcription
1 Learning the meaning of music Brian Whitman Music Mind and Machine group - MIT Media Laboratory 2004
2
3 Outline Why meaning / why music retrieval Community metadata / language analysis Long distance song effects / popularity Audio analysis / feature extraction Learning / grounding Application layer
4 Take home messages 1) Grounding for better results in both multimedia and textual information retrieval Query by description as multimedia interface 2) Music acquisition, bias-free models, organic music intelligence
5 Music intelligence Structure Structure Genre Genre / / Style Style ID ID Song Song similarity similarity Recommendation Recommendation Artist Artist ID ID Synthesis Synthesis Extracting salience from a signal Learning is features and regression ROCK/POP Classical
6 Better understanding through semantics Structure Structure Genre Genre / / Style Style ID ID Song Song similarity similarity Recommendation Recommendation Artist Artist ID ID Synthesis Synthesis Loud college rock with electronics. How can we get meaning to computationally influence understanding?



7 Using context to learn descriptions of perception Grounding meanings (Harnad 1990): defining terms by linking them to the outside world

8 Symbol grounding in action Linking perception and meaning Regier, Siskind, Roy Duygulu: Image descriptions Sea sky sun waves Cat grass tiger Jet plane sky

9 Meaning ain t in the head
10 Where meaning is in music Relational Actionable Significance Correspondence meaning: Meaning: Meaning: The This XTC (Relationship Shins song were are makes the between like most me the important dance. Sugarplastic. Jason This British representation song Falkner pop makes group was and me of in system) the The cry. 1980s. Grays. This song reminds me of my exgirlfriend. There s a trumpet there. These pitches have been played. Key of F

11
12 Parallel Review For Beginning the majority with "Caring of Americans, Is Creepy," it's which a given: opens summer this album is the with besta season psychedelic of the flourish year. Or that so would you'd not think, be out judging of place from on the a anonymous late- TV 1960s ad men Moody and Blues, women Beach who proclaim, Boys, or "Summer Love release, is here! the Get Shins yourpresent [insert a collection iced drink of retro here] pop now!"-- nuggets whereas that distill in the the winter, finer they aspects regret of classic to inform acid rock us that with it's surrealistic time to brace lyrics, ourselves independently with a new Burlington melodic bass coat. lines, And jangly TV is just guitars, an exaggerated echo laden reflection vocals, minimalist of ourselves; keyboard motifs, the hordes and a of myriad convertibles of cosmic making sound the effects. weekend With only two of the cuts clocking in at over four minutes, Oh Inverted World avoids the penchant for self-indulgence pilgrimage to the nearest beach are proof enough. Vitamin D that befalls most outfits who worship at the altar of Syd Barrett, Skip Spence, and Arthur Lee. Lead overdoses singer James Mercer's abound. lazy, hazy If phrasing my tone and vocal isn't timbre, suggestive which often echoes enough, a young then Brian Wilson, I'll drifts in and out of the subtle tempo changes of "Know Your Onion," the jagged rhythm "Girl Inform say Me," the it Donovan-esque flat out: folksy I veneer hate of the "New summer. Slang," and the It Warhol's is, in Factory my aura opinion, of "Your Algebra," the worst all of which season illustrate of this the New year. Mexico-based Sure, quartet's it's adept great knowledge for of the holidays, progressive/art work rock genre which they so lovingly pay homage to. Though the production and mix are somewhat polished when vacations, compared to the memorable and ogling recordings the of Moby underdressed Grape and early-pink opposite Floyd, the sex, Shins capture but the you spirit payof '67 with stunning accuracy. for this in sweat, which comes by the quart, even if you obey summer's central directive: be lazy. Then there's the traffic, both pedestrian and automobile, and those unavoidable, unbearable Hollywood blockbusters and TV reruns (or second-rate series). Not to mention those package music tours. But perhaps worst of all is the heightened aggression. Just last week, in the middle of the day, a reasonable-looking man in his mid-twenties decided to slam his palm across my forehead as he walked past me. Mere days later-- this time at night-- a similar-looking man (but different; there a lot of these guys in Boston) stumbled out of a bar and immediately grabbed my shirt and tore the pocket off, spattering his blood across my arms and chest in the process. There's a reason no one riots in the winter. Maybe I need to move to the home of Sub Pop, where the sun is shy even in summer, and where angst and aggression are more likely to be internalized. Then again, if Sub Pop is releasing the Shins' kind-of debut (they've been around for nine years, previously as Flake, and then Flake Music), maybe even
13 What is post-rock? Is genre ID learning meaning?
14 How to get at meaning Self label LKBs / SDBs Ontologies OpenMind / Community directed Observation Better initial results More accurate more generalization power (more work, too) scale free / organic
15

16 Music ontologies


17 Language Acquisition Animal experiments, birdsong Instinct / Innate Attempting to find linguistic primitives Computational models
18 Music acquisition Short term music model: auditory scene to events Structural music model: recurring patterns in music streams Language of music: relating artists to descriptions (cultural representation) Music acceptance models: path of music through social network Grounding sound, what does loud mean? Semantics of music: what does rock mean? What makes a song popular? Semantic synthesis
19 Acoustic vs. Cultural Representations Acoustic: Instrumentation Short-time (timbral) Mid-time (structural) Usually all we have Cultural: Long-scale time Inherent user model Listener s perspective Two-way IR Which genre? Which artist? What instruments? Describe this. Do I like this? 10 years ago? Which style?
20 Community metadata Whitman / Lawrence (ICMC2002) Internet-mined description of music Embed description as kernel space Community-derived meaning Time-aware! Freely available
21 Language Processing for IR Web page to feature vector HTML Aosid asduh asdihu asiuh oiasjodijasodjioaisjdsaioj aoijsoidjaosjidsaidoj. Oiajsdoijasoijd. Iasoijdoijasoijdaisjd. Asij aijsdoij. Aoijsdoijasdiojas. Aiasijdoiajsdj., asijdiojad iojasodijasiioas asjidijoasd oiajsdoijasd ioajsdojiasiojd iojasdoijasoidj. Asidjsadjd iojasdoijasoijdijdsa. IOJ iojasdoijaoisjd. Ijiojsad. Sentence Chunks. XTC was one of the smartest and catchiest British pop bands to emerge from the punk and new wave explosion of the late '70s.. n1 n2 n3 XTC Was One Of the Smartest And Catchiest British Pop Bands To Emerge From Punk New wave XTC was Was one One of Of the The smartest Smartest and And catchiest Catchiest british British pop Pop bands Bands to To emerge Emerge from From the The punk Punk and And new XTC was one Was one of One of the Of the smartest The smartest and Smartest and catchiest And catchiest british Catchiest british pop British pop bands Pop bands to Bands to emerge To emerge from Emerge from the From the punk The punk and Punk and new And new wave np art adj XTC Catchiest british pop bands British pop bands Pop bands Punk and new wave explosion XTC Smartest Catchiest British New late
22 What s a good scoring metric? TF-IDF provides natural weighting TF-IDF is More rare co-occurrences mean more. i.e. two artists sharing the term heavy metal banjo vs. rock music But s ( f, f ) = t d f f t d
 = s( f, f ) = f t d d f t e (log( 2σ f d 2 ) µ )")
23 Smooth the TF-IDF Reward mid-ground f terms t s ( ft, fd ) = s( f, f ) = f t d d f t e (log( 2σ f d 2 ) µ ) 2
24 Experiments Will two known-similar artists have a higher overlap than two random artists? Use 2 metrics Straight TF-IDF sum Smoothed gaussian sum On each term type Similarity is: for all shared terms S( a, b) = s( f t, fd )
25 TF-IDF Sum Results Accuracy: % of artist pairs that were predicted similar correctly (S(a,b) > S(a,random)) Improvement = S(a,b)/S(a,random) N1 N2 Np Adj Art Accuracy 78% 80% 82% 69% 79% Improvement 7.0x 7.7x 5.2x 6.8x 6.9x
26 Gaussian Smoothed Results Gaussian does far better on the larger term types (n1,n2,np) N1 N2 Np Adj Art Accuracy 83% 88% 85% 63% 79% Improvement 3.4x 2.7x 3.0x 4.8x 8.2x
27
28 P2P Similarity Crawling p2p networks Download user->song relations Similarity inferred from collections? Similarity metric: ) ) ( ) ( ) ( (1 ) ( ), ( ), ( c C b C a C b C b a C b a S =
29 P2P Crawling Logistics Many freely available scripting agents for P2P networks Easier: OpenNap, Gnutella, Soulseek No real authentication/social protocol Harder: Kazaa, DirectConnect, Hotline/KDX/etc Usual algorithm: search for random band name, browse collections of matching clients

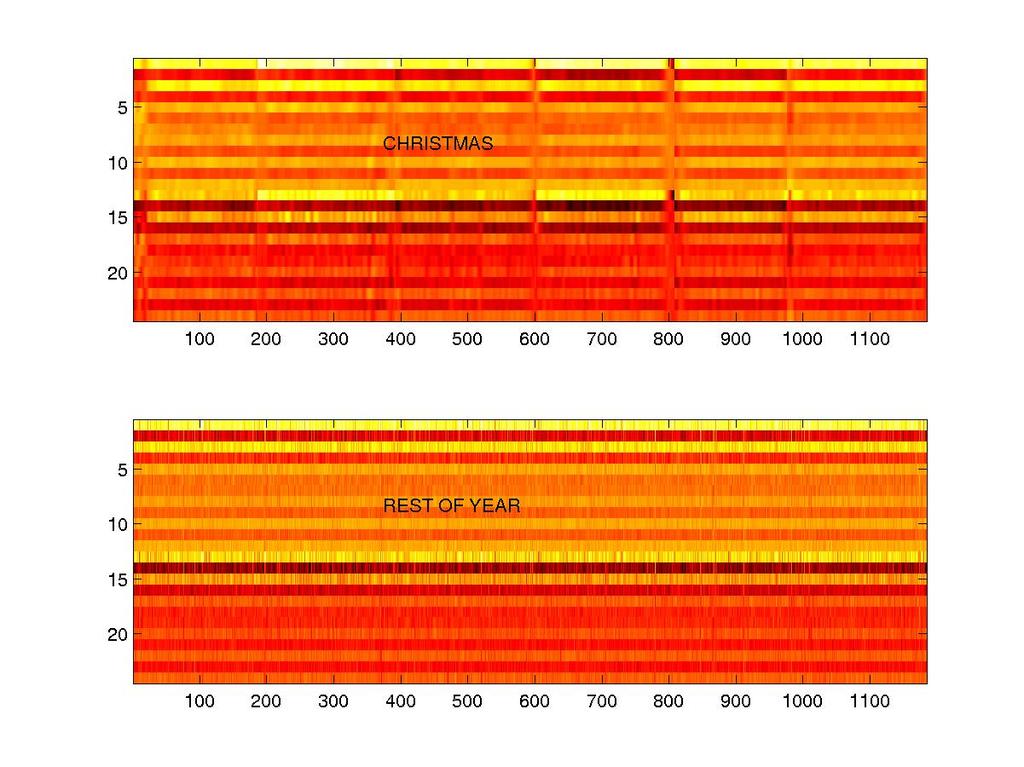
30

31 P2P trend maps Far more #1s/year than real life 7-14 day lead on big hits No genre stratification
32 Query by description (audio) What does loud mean? Play me something fast with an electronic beat Single-term to frame attachment
33 Query-by-description as evaluation case QBD: Play me something loud with an electronic beat. With what probability can we accurately describe music? Training: We play the computer songs by a bunch of artists, and have it read about the artists on the Internet. Testing: We play the computer more songs by different artists and see how well it can describe it. Next steps: human use

34 The audio data Large set of music audio Minnowmatch testbed (1000 albums) Most popular on OpenNap August artists randomly chosen, 5 songs each Each 2sec frame an observation: TD PSD PCA to 20 dimensions 2sec audio 512-pSD 20-PCA
35 Learning formalization Learn relation between audio and naturally encountered description Can t trust target class! Opinion Counterfactuals Wrong artist Not musical 200,000 possible terms (output classes!) (For this experiment we limit it to adjectives)
36 Severe multi-class problem Observed a B C D E F G?? 1. Incorrect ground truth 2. Bias 3. Large number of output classes
37 Kernel space Observed (, ) (, ) (, ) (, ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( x i, x j ) = e x i 2δ x 2 j 2 Distance function represents data (gaussian works well for audio)
38 Regularized least-squares classification (RLSC) (Rifkin 2002) (, ) (, ) (, ) (, ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) K ( ) ( ) ( ) ( ) ( K I + )c = C t y t I 1 c t = ( K + ) y t C c t = machine for class t y t = truth vector for class t C = regularization constant (10)
39 New SVM Kernel for Memory Casper: Gaussian distance with stored memory half-life, fourier domain Gaussian kernel Casper kernel

40 Gram Matrices Gaussian vs. Casper
41 Results Experiment Artist ID Result (1-in-107) Pos% Neg% Weight% PSD gaussian PSD casper
42 Per-term accuracy Good terms Bad terms Electronic 33% Annoying 0% Digital 29% Dangerous 0% Gloomy 29% Fictional 0% Unplugged 30% Magnetic 0% Acoustic 23% Pretentious 1% Dark 17% Gator 0% Female 32% Breaky 0% Romantic 23% Sexy 1% Vocal 18% Wicked 0% Happy 13% Lyrical 0% Classical 27% Worldwide 2% Baseline = 0.14% Good term set as restricted grammar?
 Music as discrete path through time Reg d to 20 states 0.")
43 Time-aware audio features MPEG-7 derived state-paths (Casey 2001) Music as discrete path through time Reg d to 20 states 0.1 s
44 Per-term accuracy (state paths) Good terms Bad terms Busy 42% Artistic 0% Steady 41% Homeless 0% Funky 39% Hungry 0% Intense 38% Great 0% Acoustic 36% Awful 0% African 35% Warped 0% Melodic 27% Illegal 0% Romantic 23% Cruel 0% Slow 21% Notorious 0% Wild 25% Good 0% Young 17% Okay 0% Weighted accuracy (to allow for bias)

45 Real-time Description synthesis

46 Semantic decomposition Music models from unsupervised methods find statistically significant parameters Can we identify the optimal semantic attributes for understanding music? Female/Male Angry/Calm
47 The linguistic expert Some semantic attachment requires lookups to an expert Dark Big Light? Small
48 Linguistic expert Perception + observed language: Big Lookups to linguistic expert: Light Dark Small Big Dark Small Light Allows you to infer new gradation:? Big Dark Small Light
49 Top descriptive parameters All P(a) of terms in anchor synant sets averaged P(quiet) = 0.2, P(loud) = 0.4, P(quiet-loud) = 0.3. Sorted list gives best grounded parameter map Good parameters Bad parameters Big little 30% Evil good 5% Present past 29% Bad good 0% Unusual familiar 28% Violent nonviolent 1% Low high 27% Extraordinary ordinary 0% Male female 22% Cool warm 7% Hard soft 21% Red white 6% Loud soft 19% Second first 4% Smooth rough 14% Full empty 0% Vocal instrumental 10% Internal external 0% Minor major 10% Foul fair 5%
50 Learning the knobs Nonlinear dimension reduction Isomap Like PCA/NMF/MDS, but: Meaning oriented Better perceptual distance Only feed polar observations as input Future data can be quickly semantically classified with guaranteed expressivity Quiet Male Loud Female
51 Parameter understanding Some knobs aren t 1-D intrinsically Color spaces & user models!

52 Mixture classification Eye ring Beak Uppertail coverts Bird head machine Bird tail machine Call pitch histogram Gis type Wingspan sparrow sparrow bluejay bluejay
53 Mixture classification Rock Classical Beat < 120bpm Harmonicity MFCC deltas Wears eye makeup Has made concept album Song s bridge is actually chorus shifted up a key

54 Clustering / de-correlation
55 Big idea Extract meaning from music for better audio classification and understanding 70% 60% 50% 40% 30% 20% 10% 0% baseline straight signal statistical reduction semantic reduction understanding task accuracy
56 Creating a semantic reducer Good terms Busy Steady Funky Intense Acoustic African Melodic Romantic Slow The Shins Madonna 42% 41% 39% 38% 36% 35% 27% 23% 21% Wild 25% Young Jason Falkner 17%
57 Applying the semantic reduction New audio: funky f(x) 0.5 cool -0.3 highest 0.8 junior 0.3 low -0.8
58 Experiment - artist ID The rare ground truth in music IR Still hard problem - 30% Perils: album effect, madonna problem Best test case for music intelligence
59 Proving it s better; the setup etc Bunch of music Basis extraction Artist ID (257) PCA sem NMF rand Train Test (10) Train Test (10) Train Test (10)
60 Artist identification results non pca nmf sem rand % 70% 60% 50% 40% 30% 20% 10% 0% non pca nmf sem per-observation baseline
61 Next steps Community detection / sharpening Human evaluation (agreement with learned models) (inter-rater reliability) Intra-song meaning
62 Thanks Dan Ellis, Adam Berenzweig, Beth Logan, Steve Lawrence, Gary Flake, Ryan Rifkin, Deb Roy, Barry Vercoe, Tristan Jehan, Victor Adan, Ryan McKinley, Youngmoo Kim, Paris Smaragdis, Mike Casey, Keith Martin, Kelly Dobson
Learning Word Meanings and Descriptive Parameter Spaces from Music. Brian Whitman, Deb Roy and Barry Vercoe MIT Media Lab
 Learning Word Meanings and Descriptive Parameter Spaces from Music Brian Whitman, Deb Roy and Barry Vercoe MIT Media Lab Music intelligence Structure Structure Genre Genre / / Style Style ID ID Song Song
Learning Word Meanings and Descriptive Parameter Spaces from Music Brian Whitman, Deb Roy and Barry Vercoe MIT Media Lab Music intelligence Structure Structure Genre Genre / / Style Style ID ID Song Song
MUSI-6201 Computational Music Analysis
 MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
MUSI-6201 Computational Music Analysis Part 9.1: Genre Classification alexander lerch November 4, 2015 temporal analysis overview text book Chapter 8: Musical Genre, Similarity, and Mood (pp. 151 155)
Music Emotion Recognition. Jaesung Lee. Chung-Ang University
 Music Emotion Recognition Jaesung Lee Chung-Ang University Introduction Searching Music in Music Information Retrieval Some information about target music is available Query by Text: Title, Artist, or
Music Emotion Recognition Jaesung Lee Chung-Ang University Introduction Searching Music in Music Information Retrieval Some information about target music is available Query by Text: Title, Artist, or
AUTOMATIC RECORD REVIEWS
 AUTOMATIC RECORD REVIEWS Brian Whitman MIT Media Lab Music Mind and Machine Group Daniel P.W. Ellis LabROSA Columbia University Electrical Engineering ABSTRACT Record reviews provide a unique and focused
AUTOMATIC RECORD REVIEWS Brian Whitman MIT Media Lab Music Mind and Machine Group Daniel P.W. Ellis LabROSA Columbia University Electrical Engineering ABSTRACT Record reviews provide a unique and focused
Supervised Learning in Genre Classification
 Supervised Learning in Genre Classification Introduction & Motivation Mohit Rajani and Luke Ekkizogloy {i.mohit,luke.ekkizogloy}@gmail.com Stanford University, CS229: Machine Learning, 2009 Now that music
Supervised Learning in Genre Classification Introduction & Motivation Mohit Rajani and Luke Ekkizogloy {i.mohit,luke.ekkizogloy}@gmail.com Stanford University, CS229: Machine Learning, 2009 Now that music
Music Recommendation from Song Sets
 Music Recommendation from Song Sets Beth Logan Cambridge Research Laboratory HP Laboratories Cambridge HPL-2004-148 August 30, 2004* E-mail: Beth.Logan@hp.com music analysis, information retrieval, multimedia
Music Recommendation from Song Sets Beth Logan Cambridge Research Laboratory HP Laboratories Cambridge HPL-2004-148 August 30, 2004* E-mail: Beth.Logan@hp.com music analysis, information retrieval, multimedia
WHAT MAKES FOR A HIT POP SONG? WHAT MAKES FOR A POP SONG?
 WHAT MAKES FOR A HIT POP SONG? WHAT MAKES FOR A POP SONG? NICHOLAS BORG AND GEORGE HOKKANEN Abstract. The possibility of a hit song prediction algorithm is both academically interesting and industry motivated.
WHAT MAKES FOR A HIT POP SONG? WHAT MAKES FOR A POP SONG? NICHOLAS BORG AND GEORGE HOKKANEN Abstract. The possibility of a hit song prediction algorithm is both academically interesting and industry motivated.
Outline. Why do we classify? Audio Classification
 Outline Introduction Music Information Retrieval Classification Process Steps Pitch Histograms Multiple Pitch Detection Algorithm Musical Genre Classification Implementation Future Work Why do we classify
Outline Introduction Music Information Retrieval Classification Process Steps Pitch Histograms Multiple Pitch Detection Algorithm Musical Genre Classification Implementation Future Work Why do we classify
Music Genre Classification and Variance Comparison on Number of Genres
 Music Genre Classification and Variance Comparison on Number of Genres Miguel Francisco, miguelf@stanford.edu Dong Myung Kim, dmk8265@stanford.edu 1 Abstract In this project we apply machine learning techniques
Music Genre Classification and Variance Comparison on Number of Genres Miguel Francisco, miguelf@stanford.edu Dong Myung Kim, dmk8265@stanford.edu 1 Abstract In this project we apply machine learning techniques
Can Song Lyrics Predict Genre? Danny Diekroeger Stanford University
 Can Song Lyrics Predict Genre? Danny Diekroeger Stanford University danny1@stanford.edu 1. Motivation and Goal Music has long been a way for people to express their emotions. And because we all have a
Can Song Lyrics Predict Genre? Danny Diekroeger Stanford University danny1@stanford.edu 1. Motivation and Goal Music has long been a way for people to express their emotions. And because we all have a
Music Genre Classification
 Music Genre Classification chunya25 Fall 2017 1 Introduction A genre is defined as a category of artistic composition, characterized by similarities in form, style, or subject matter. [1] Some researchers
Music Genre Classification chunya25 Fall 2017 1 Introduction A genre is defined as a category of artistic composition, characterized by similarities in form, style, or subject matter. [1] Some researchers
 http://www.xkcd.com/655/ Audio Retrieval David Kauchak cs160 Fall 2009 Thanks to Doug Turnbull for some of the slides Administrative CS Colloquium vs. Wed. before Thanksgiving producers consumers 8M artists
http://www.xkcd.com/655/ Audio Retrieval David Kauchak cs160 Fall 2009 Thanks to Doug Turnbull for some of the slides Administrative CS Colloquium vs. Wed. before Thanksgiving producers consumers 8M artists
Toward Evaluation Techniques for Music Similarity
 Toward Evaluation Techniques for Music Similarity Beth Logan, Daniel P.W. Ellis 1, Adam Berenzweig 1 Cambridge Research Laboratory HP Laboratories Cambridge HPL-2003-159 July 29 th, 2003* E-mail: Beth.Logan@hp.com,
Toward Evaluation Techniques for Music Similarity Beth Logan, Daniel P.W. Ellis 1, Adam Berenzweig 1 Cambridge Research Laboratory HP Laboratories Cambridge HPL-2003-159 July 29 th, 2003* E-mail: Beth.Logan@hp.com,
Singer Traits Identification using Deep Neural Network
 Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Singer Traits Identification using Deep Neural Network Zhengshan Shi Center for Computer Research in Music and Acoustics Stanford University kittyshi@stanford.edu Abstract The author investigates automatic
Combination of Audio & Lyrics Features for Genre Classication in Digital Audio Collections
 1/23 Combination of Audio & Lyrics Features for Genre Classication in Digital Audio Collections Rudolf Mayer, Andreas Rauber Vienna University of Technology {mayer,rauber}@ifs.tuwien.ac.at Robert Neumayer
1/23 Combination of Audio & Lyrics Features for Genre Classication in Digital Audio Collections Rudolf Mayer, Andreas Rauber Vienna University of Technology {mayer,rauber}@ifs.tuwien.ac.at Robert Neumayer
GCT535- Sound Technology for Multimedia Timbre Analysis. Graduate School of Culture Technology KAIST Juhan Nam
 GCT535- Sound Technology for Multimedia Timbre Analysis Graduate School of Culture Technology KAIST Juhan Nam 1 Outlines Timbre Analysis Definition of Timbre Timbre Features Zero-crossing rate Spectral
GCT535- Sound Technology for Multimedia Timbre Analysis Graduate School of Culture Technology KAIST Juhan Nam 1 Outlines Timbre Analysis Definition of Timbre Timbre Features Zero-crossing rate Spectral
Using Genre Classification to Make Content-based Music Recommendations
 Using Genre Classification to Make Content-based Music Recommendations Robbie Jones (rmjones@stanford.edu) and Karen Lu (karenlu@stanford.edu) CS 221, Autumn 2016 Stanford University I. Introduction Our
Using Genre Classification to Make Content-based Music Recommendations Robbie Jones (rmjones@stanford.edu) and Karen Lu (karenlu@stanford.edu) CS 221, Autumn 2016 Stanford University I. Introduction Our
Automatic Rhythmic Notation from Single Voice Audio Sources
 Automatic Rhythmic Notation from Single Voice Audio Sources Jack O Reilly, Shashwat Udit Introduction In this project we used machine learning technique to make estimations of rhythmic notation of a sung
Automatic Rhythmic Notation from Single Voice Audio Sources Jack O Reilly, Shashwat Udit Introduction In this project we used machine learning technique to make estimations of rhythmic notation of a sung
Computational Models of Music Similarity. Elias Pampalk National Institute for Advanced Industrial Science and Technology (AIST)
") Computational Models of Music Similarity 1 Elias Pampalk National Institute for Advanced Industrial Science and Technology (AIST) Abstract The perceived similarity of two pieces of music is multi-dimensional,
Computational Models of Music Similarity 1 Elias Pampalk National Institute for Advanced Industrial Science and Technology (AIST) Abstract The perceived similarity of two pieces of music is multi-dimensional,
Music Information Retrieval Community
 Music Information Retrieval Community What: Developing systems that retrieve music When: Late 1990 s to Present Where: ISMIR - conference started in 2000 Why: lots of digital music, lots of music lovers,
Music Information Retrieval Community What: Developing systems that retrieve music When: Late 1990 s to Present Where: ISMIR - conference started in 2000 Why: lots of digital music, lots of music lovers,
The Million Song Dataset
 The Million Song Dataset AUDIO FEATURES The Million Song Dataset There is no data like more data Bob Mercer of IBM (1985). T. Bertin-Mahieux, D.P.W. Ellis, B. Whitman, P. Lamere, The Million Song Dataset,
The Million Song Dataset AUDIO FEATURES The Million Song Dataset There is no data like more data Bob Mercer of IBM (1985). T. Bertin-Mahieux, D.P.W. Ellis, B. Whitman, P. Lamere, The Million Song Dataset,
Musical Hit Detection
 Musical Hit Detection CS 229 Project Milestone Report Eleanor Crane Sarah Houts Kiran Murthy December 12, 2008 1 Problem Statement Musical visualizers are programs that process audio input in order to
Musical Hit Detection CS 229 Project Milestone Report Eleanor Crane Sarah Houts Kiran Murthy December 12, 2008 1 Problem Statement Musical visualizers are programs that process audio input in order to
Music Segmentation Using Markov Chain Methods
 Music Segmentation Using Markov Chain Methods Paul Finkelstein March 8, 2011 Abstract This paper will present just how far the use of Markov Chains has spread in the 21 st century. We will explain some
Music Segmentation Using Markov Chain Methods Paul Finkelstein March 8, 2011 Abstract This paper will present just how far the use of Markov Chains has spread in the 21 st century. We will explain some
Classification of Timbre Similarity
 Classification of Timbre Similarity Corey Kereliuk McGill University March 15, 2007 1 / 16 1 Definition of Timbre What Timbre is Not What Timbre is A 2-dimensional Timbre Space 2 3 Considerations Common
Classification of Timbre Similarity Corey Kereliuk McGill University March 15, 2007 1 / 16 1 Definition of Timbre What Timbre is Not What Timbre is A 2-dimensional Timbre Space 2 3 Considerations Common
Extracting Information from Music Audio
 Extracting Information from Music Audio Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Engineering, Columbia University, NY USA http://labrosa.ee.columbia.edu/
Extracting Information from Music Audio Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Engineering, Columbia University, NY USA http://labrosa.ee.columbia.edu/
Music Mood. Sheng Xu, Albert Peyton, Ryan Bhular
 Music Mood Sheng Xu, Albert Peyton, Ryan Bhular What is Music Mood A psychological & musical topic Human emotions conveyed in music can be comprehended from two aspects: Lyrics Music Factors that affect
Music Mood Sheng Xu, Albert Peyton, Ryan Bhular What is Music Mood A psychological & musical topic Human emotions conveyed in music can be comprehended from two aspects: Lyrics Music Factors that affect
Assigning and Visualizing Music Genres by Web-based Co-Occurrence Analysis
 Assigning and Visualizing Music Genres by Web-based Co-Occurrence Analysis Markus Schedl 1, Tim Pohle 1, Peter Knees 1, Gerhard Widmer 1,2 1 Department of Computational Perception, Johannes Kepler University,
Assigning and Visualizing Music Genres by Web-based Co-Occurrence Analysis Markus Schedl 1, Tim Pohle 1, Peter Knees 1, Gerhard Widmer 1,2 1 Department of Computational Perception, Johannes Kepler University,
Machine Learning Term Project Write-up Creating Models of Performers of Chopin Mazurkas
 Machine Learning Term Project Write-up Creating Models of Performers of Chopin Mazurkas Marcello Herreshoff In collaboration with Craig Sapp (craig@ccrma.stanford.edu) 1 Motivation We want to generative
Machine Learning Term Project Write-up Creating Models of Performers of Chopin Mazurkas Marcello Herreshoff In collaboration with Craig Sapp (craig@ccrma.stanford.edu) 1 Motivation We want to generative
DAY 1. Intelligent Audio Systems: A review of the foundations and applications of semantic audio analysis and music information retrieval
 DAY 1 Intelligent Audio Systems: A review of the foundations and applications of semantic audio analysis and music information retrieval Jay LeBoeuf Imagine Research jay{at}imagine-research.com Rebecca
DAY 1 Intelligent Audio Systems: A review of the foundations and applications of semantic audio analysis and music information retrieval Jay LeBoeuf Imagine Research jay{at}imagine-research.com Rebecca
APPLICATIONS OF A SEMI-AUTOMATIC MELODY EXTRACTION INTERFACE FOR INDIAN MUSIC
 APPLICATIONS OF A SEMI-AUTOMATIC MELODY EXTRACTION INTERFACE FOR INDIAN MUSIC Vishweshwara Rao, Sachin Pant, Madhumita Bhaskar and Preeti Rao Department of Electrical Engineering, IIT Bombay {vishu, sachinp,
APPLICATIONS OF A SEMI-AUTOMATIC MELODY EXTRACTION INTERFACE FOR INDIAN MUSIC Vishweshwara Rao, Sachin Pant, Madhumita Bhaskar and Preeti Rao Department of Electrical Engineering, IIT Bombay {vishu, sachinp,
INTER GENRE SIMILARITY MODELLING FOR AUTOMATIC MUSIC GENRE CLASSIFICATION
 INTER GENRE SIMILARITY MODELLING FOR AUTOMATIC MUSIC GENRE CLASSIFICATION ULAŞ BAĞCI AND ENGIN ERZIN arxiv:0907.3220v1 [cs.sd] 18 Jul 2009 ABSTRACT. Music genre classification is an essential tool for
INTER GENRE SIMILARITY MODELLING FOR AUTOMATIC MUSIC GENRE CLASSIFICATION ULAŞ BAĞCI AND ENGIN ERZIN arxiv:0907.3220v1 [cs.sd] 18 Jul 2009 ABSTRACT. Music genre classification is an essential tool for
Music Mood Classification - an SVM based approach. Sebastian Napiorkowski
 Music Mood Classification - an SVM based approach Sebastian Napiorkowski Topics on Computer Music (Seminar Report) HPAC - RWTH - SS2015 Contents 1. Motivation 2. Quantification and Definition of Mood 3.
Music Mood Classification - an SVM based approach Sebastian Napiorkowski Topics on Computer Music (Seminar Report) HPAC - RWTH - SS2015 Contents 1. Motivation 2. Quantification and Definition of Mood 3.
Acoustic Scene Classification
 Acoustic Scene Classification Marc-Christoph Gerasch Seminar Topics in Computer Music - Acoustic Scene Classification 6/24/2015 1 Outline Acoustic Scene Classification - definition History and state of
Acoustic Scene Classification Marc-Christoph Gerasch Seminar Topics in Computer Music - Acoustic Scene Classification 6/24/2015 1 Outline Acoustic Scene Classification - definition History and state of
Week 14 Query-by-Humming and Music Fingerprinting. Roger B. Dannenberg Professor of Computer Science, Art and Music Carnegie Mellon University
 Week 14 Query-by-Humming and Music Fingerprinting Roger B. Dannenberg Professor of Computer Science, Art and Music Overview n Melody-Based Retrieval n Audio-Score Alignment n Music Fingerprinting 2 Metadata-based
Week 14 Query-by-Humming and Music Fingerprinting Roger B. Dannenberg Professor of Computer Science, Art and Music Overview n Melody-Based Retrieval n Audio-Score Alignment n Music Fingerprinting 2 Metadata-based
jsymbolic 2: New Developments and Research Opportunities
 jsymbolic 2: New Developments and Research Opportunities Cory McKay Marianopolis College and CIRMMT Montreal, Canada 2 / 30 Topics Introduction to features (from a machine learning perspective) And how
jsymbolic 2: New Developments and Research Opportunities Cory McKay Marianopolis College and CIRMMT Montreal, Canada 2 / 30 Topics Introduction to features (from a machine learning perspective) And how
Music Radar: A Web-based Query by Humming System
 Music Radar: A Web-based Query by Humming System Lianjie Cao, Peng Hao, Chunmeng Zhou Computer Science Department, Purdue University, 305 N. University Street West Lafayette, IN 47907-2107 {cao62, pengh,
Music Radar: A Web-based Query by Humming System Lianjie Cao, Peng Hao, Chunmeng Zhou Computer Science Department, Purdue University, 305 N. University Street West Lafayette, IN 47907-2107 {cao62, pengh,
Predicting Time-Varying Musical Emotion Distributions from Multi-Track Audio
 Predicting Time-Varying Musical Emotion Distributions from Multi-Track Audio Jeffrey Scott, Erik M. Schmidt, Matthew Prockup, Brandon Morton, and Youngmoo E. Kim Music and Entertainment Technology Laboratory
Predicting Time-Varying Musical Emotion Distributions from Multi-Track Audio Jeffrey Scott, Erik M. Schmidt, Matthew Prockup, Brandon Morton, and Youngmoo E. Kim Music and Entertainment Technology Laboratory
A Survey of Audio-Based Music Classification and Annotation
 A Survey of Audio-Based Music Classification and Annotation Zhouyu Fu, Guojun Lu, Kai Ming Ting, and Dengsheng Zhang IEEE Trans. on Multimedia, vol. 13, no. 2, April 2011 presenter: Yin-Tzu Lin ( 阿孜孜 ^.^)
A Survey of Audio-Based Music Classification and Annotation Zhouyu Fu, Guojun Lu, Kai Ming Ting, and Dengsheng Zhang IEEE Trans. on Multimedia, vol. 13, no. 2, April 2011 presenter: Yin-Tzu Lin ( 阿孜孜 ^.^)
Lecture 15: Research at LabROSA
 ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 15: Research at LabROSA 1. Sources, Mixtures, & Perception 2. Spatial Filtering 3. Time-Frequency Masking 4. Model-Based Separation Dan Ellis Dept. Electrical
ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 15: Research at LabROSA 1. Sources, Mixtures, & Perception 2. Spatial Filtering 3. Time-Frequency Masking 4. Model-Based Separation Dan Ellis Dept. Electrical
Introductions to Music Information Retrieval
 Introductions to Music Information Retrieval ECE 272/472 Audio Signal Processing Bochen Li University of Rochester Wish List For music learners/performers While I play the piano, turn the page for me Tell
Introductions to Music Information Retrieval ECE 272/472 Audio Signal Processing Bochen Li University of Rochester Wish List For music learners/performers While I play the piano, turn the page for me Tell
Automatic Laughter Detection
 Automatic Laughter Detection Mary Knox Final Project (EECS 94) knoxm@eecs.berkeley.edu December 1, 006 1 Introduction Laughter is a powerful cue in communication. It communicates to listeners the emotional
Automatic Laughter Detection Mary Knox Final Project (EECS 94) knoxm@eecs.berkeley.edu December 1, 006 1 Introduction Laughter is a powerful cue in communication. It communicates to listeners the emotional
Melody Retrieval On The Web
 Melody Retrieval On The Web Thesis proposal for the degree of Master of Science at the Massachusetts Institute of Technology M.I.T Media Laboratory Fall 2000 Thesis supervisor: Barry Vercoe Professor,
Melody Retrieval On The Web Thesis proposal for the degree of Master of Science at the Massachusetts Institute of Technology M.I.T Media Laboratory Fall 2000 Thesis supervisor: Barry Vercoe Professor,
MusCat: A Music Browser Featuring Abstract Pictures and Zooming User Interface
 MusCat: A Music Browser Featuring Abstract Pictures and Zooming User Interface 1st Author 1st author's affiliation 1st line of address 2nd line of address Telephone number, incl. country code 1st author's
MusCat: A Music Browser Featuring Abstract Pictures and Zooming User Interface 1st Author 1st author's affiliation 1st line of address 2nd line of address Telephone number, incl. country code 1st author's
SONG-LEVEL FEATURES AND SUPPORT VECTOR MACHINES FOR MUSIC CLASSIFICATION
 SONG-LEVEL FEATURES AN SUPPORT VECTOR MACHINES FOR MUSIC CLASSIFICATION Michael I. Mandel and aniel P.W. Ellis LabROSA, ept. of Elec. Eng., Columbia University, NY NY USA {mim,dpwe}@ee.columbia.edu ABSTRACT
SONG-LEVEL FEATURES AN SUPPORT VECTOR MACHINES FOR MUSIC CLASSIFICATION Michael I. Mandel and aniel P.W. Ellis LabROSA, ept. of Elec. Eng., Columbia University, NY NY USA {mim,dpwe}@ee.columbia.edu ABSTRACT
ONLINE ACTIVITIES FOR MUSIC INFORMATION AND ACOUSTICS EDUCATION AND PSYCHOACOUSTIC DATA COLLECTION
 ONLINE ACTIVITIES FOR MUSIC INFORMATION AND ACOUSTICS EDUCATION AND PSYCHOACOUSTIC DATA COLLECTION Travis M. Doll Ray V. Migneco Youngmoo E. Kim Drexel University, Electrical & Computer Engineering {tmd47,rm443,ykim}@drexel.edu
ONLINE ACTIVITIES FOR MUSIC INFORMATION AND ACOUSTICS EDUCATION AND PSYCHOACOUSTIC DATA COLLECTION Travis M. Doll Ray V. Migneco Youngmoo E. Kim Drexel University, Electrical & Computer Engineering {tmd47,rm443,ykim}@drexel.edu
Creating a Feature Vector to Identify Similarity between MIDI Files
 Creating a Feature Vector to Identify Similarity between MIDI Files Joseph Stroud 2017 Honors Thesis Advised by Sergio Alvarez Computer Science Department, Boston College 1 Abstract Today there are many
Creating a Feature Vector to Identify Similarity between MIDI Files Joseph Stroud 2017 Honors Thesis Advised by Sergio Alvarez Computer Science Department, Boston College 1 Abstract Today there are many
An ecological approach to multimodal subjective music similarity perception
 An ecological approach to multimodal subjective music similarity perception Stephan Baumann German Research Center for AI, Germany www.dfki.uni-kl.de/~baumann John Halloran Interact Lab, Department of
An ecological approach to multimodal subjective music similarity perception Stephan Baumann German Research Center for AI, Germany www.dfki.uni-kl.de/~baumann John Halloran Interact Lab, Department of
Automatic Music Clustering using Audio Attributes
 Automatic Music Clustering using Audio Attributes Abhishek Sen BTech (Electronics) Veermata Jijabai Technological Institute (VJTI), Mumbai, India abhishekpsen@gmail.com Abstract Music brings people together,
Automatic Music Clustering using Audio Attributes Abhishek Sen BTech (Electronics) Veermata Jijabai Technological Institute (VJTI), Mumbai, India abhishekpsen@gmail.com Abstract Music brings people together,
About Giovanni De Poli. What is Model. Introduction. di Poli: Methodologies for Expressive Modeling of/for Music Performance
 Methodologies for Expressiveness Modeling of and for Music Performance by Giovanni De Poli Center of Computational Sonology, Department of Information Engineering, University of Padova, Padova, Italy About
Methodologies for Expressiveness Modeling of and for Music Performance by Giovanni De Poli Center of Computational Sonology, Department of Information Engineering, University of Padova, Padova, Italy About
Audio Feature Extraction for Corpus Analysis
 Audio Feature Extraction for Corpus Analysis Anja Volk Sound and Music Technology 5 Dec 2017 1 Corpus analysis What is corpus analysis study a large corpus of music for gaining insights on general trends
Audio Feature Extraction for Corpus Analysis Anja Volk Sound and Music Technology 5 Dec 2017 1 Corpus analysis What is corpus analysis study a large corpus of music for gaining insights on general trends
Automatic Music Genre Classification
 Automatic Music Genre Classification Nathan YongHoon Kwon, SUNY Binghamton Ingrid Tchakoua, Jackson State University Matthew Pietrosanu, University of Alberta Freya Fu, Colorado State University Yue Wang,
Automatic Music Genre Classification Nathan YongHoon Kwon, SUNY Binghamton Ingrid Tchakoua, Jackson State University Matthew Pietrosanu, University of Alberta Freya Fu, Colorado State University Yue Wang,
Chapter Two: Long-Term Memory for Timbre
 25 Chapter Two: Long-Term Memory for Timbre Task In a test of long-term memory, listeners are asked to label timbres and indicate whether or not each timbre was heard in a previous phase of the experiment
25 Chapter Two: Long-Term Memory for Timbre Task In a test of long-term memory, listeners are asked to label timbres and indicate whether or not each timbre was heard in a previous phase of the experiment
Automatic Music Similarity Assessment and Recommendation. A Thesis. Submitted to the Faculty. Drexel University. Donald Shaul Williamson
 Automatic Music Similarity Assessment and Recommendation A Thesis Submitted to the Faculty of Drexel University by Donald Shaul Williamson in partial fulfillment of the requirements for the degree of Master
Automatic Music Similarity Assessment and Recommendation A Thesis Submitted to the Faculty of Drexel University by Donald Shaul Williamson in partial fulfillment of the requirements for the degree of Master
Gaussian Mixture Model for Singing Voice Separation from Stereophonic Music
 Gaussian Mixture Model for Singing Voice Separation from Stereophonic Music Mine Kim, Seungkwon Beack, Keunwoo Choi, and Kyeongok Kang Realistic Acoustics Research Team, Electronics and Telecommunications
Gaussian Mixture Model for Singing Voice Separation from Stereophonic Music Mine Kim, Seungkwon Beack, Keunwoo Choi, and Kyeongok Kang Realistic Acoustics Research Team, Electronics and Telecommunications
THE importance of music content analysis for musical
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 1, JANUARY 2007 333 Drum Sound Recognition for Polyphonic Audio Signals by Adaptation and Matching of Spectrogram Templates With
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 15, NO. 1, JANUARY 2007 333 Drum Sound Recognition for Polyphonic Audio Signals by Adaptation and Matching of Spectrogram Templates With
THE FUTURE OF VOICE ASSISTANTS IN THE NETHERLANDS. To what extent should voice technology improve in order to conquer the Western European market?
 THE FUTURE OF VOICE ASSISTANTS IN THE NETHERLANDS To what extent should voice technology improve in order to conquer the Western European market? THE FUTURE OF VOICE ASSISTANTS IN THE NETHERLANDS Go to
THE FUTURE OF VOICE ASSISTANTS IN THE NETHERLANDS To what extent should voice technology improve in order to conquer the Western European market? THE FUTURE OF VOICE ASSISTANTS IN THE NETHERLANDS Go to
Section I. Quotations
 Hour 8: The Thing Explainer! Those of you who are fans of xkcd s Randall Munroe may be aware of his book Thing Explainer: Complicated Stuff in Simple Words, in which he describes a variety of things using
Hour 8: The Thing Explainer! Those of you who are fans of xkcd s Randall Munroe may be aware of his book Thing Explainer: Complicated Stuff in Simple Words, in which he describes a variety of things using
Subjective Similarity of Music: Data Collection for Individuality Analysis
 Subjective Similarity of Music: Data Collection for Individuality Analysis Shota Kawabuchi and Chiyomi Miyajima and Norihide Kitaoka and Kazuya Takeda Nagoya University, Nagoya, Japan E-mail: shota.kawabuchi@g.sp.m.is.nagoya-u.ac.jp
Subjective Similarity of Music: Data Collection for Individuality Analysis Shota Kawabuchi and Chiyomi Miyajima and Norihide Kitaoka and Kazuya Takeda Nagoya University, Nagoya, Japan E-mail: shota.kawabuchi@g.sp.m.is.nagoya-u.ac.jp
Automatic Piano Music Transcription
 Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Automatic Piano Music Transcription Jianyu Fan Qiuhan Wang Xin Li Jianyu.Fan.Gr@dartmouth.edu Qiuhan.Wang.Gr@dartmouth.edu Xi.Li.Gr@dartmouth.edu 1. Introduction Writing down the score while listening
Analyzing the Relationship Among Audio Labels Using Hubert-Arabie adjusted Rand Index
 Analyzing the Relationship Among Audio Labels Using Hubert-Arabie adjusted Rand Index Kwan Kim Submitted in partial fulfillment of the requirements for the Master of Music in Music Technology in the Department
Analyzing the Relationship Among Audio Labels Using Hubert-Arabie adjusted Rand Index Kwan Kim Submitted in partial fulfillment of the requirements for the Master of Music in Music Technology in the Department
Music Information Retrieval
 CTP 431 Music and Audio Computing Music Information Retrieval Graduate School of Culture Technology (GSCT) Juhan Nam 1 Introduction ü Instrument: Piano ü Composer: Chopin ü Key: E-minor ü Melody - ELO
CTP 431 Music and Audio Computing Music Information Retrieval Graduate School of Culture Technology (GSCT) Juhan Nam 1 Introduction ü Instrument: Piano ü Composer: Chopin ü Key: E-minor ü Melody - ELO
The song remains the same: identifying versions of the same piece using tonal descriptors
 The song remains the same: identifying versions of the same piece using tonal descriptors Emilia Gómez Music Technology Group, Universitat Pompeu Fabra Ocata, 83, Barcelona emilia.gomez@iua.upf.edu Abstract
The song remains the same: identifying versions of the same piece using tonal descriptors Emilia Gómez Music Technology Group, Universitat Pompeu Fabra Ocata, 83, Barcelona emilia.gomez@iua.upf.edu Abstract
Automatic Laughter Detection
 Automatic Laughter Detection Mary Knox 1803707 knoxm@eecs.berkeley.edu December 1, 006 Abstract We built a system to automatically detect laughter from acoustic features of audio. To implement the system,
Automatic Laughter Detection Mary Knox 1803707 knoxm@eecs.berkeley.edu December 1, 006 Abstract We built a system to automatically detect laughter from acoustic features of audio. To implement the system,
AudioRadar. A metaphorical visualization for the navigation of large music collections
 AudioRadar A metaphorical visualization for the navigation of large music collections Otmar Hilliges, Phillip Holzer, René Klüber, Andreas Butz Ludwig-Maximilians-Universität München AudioRadar An Introduction
AudioRadar A metaphorical visualization for the navigation of large music collections Otmar Hilliges, Phillip Holzer, René Klüber, Andreas Butz Ludwig-Maximilians-Universität München AudioRadar An Introduction
Unifying Low-level and High-level Music. Similarity Measures
 Unifying Low-level and High-level Music 1 Similarity Measures Dmitry Bogdanov, Joan Serrà, Nicolas Wack, Perfecto Herrera, and Xavier Serra Abstract Measuring music similarity is essential for multimedia
Unifying Low-level and High-level Music 1 Similarity Measures Dmitry Bogdanov, Joan Serrà, Nicolas Wack, Perfecto Herrera, and Xavier Serra Abstract Measuring music similarity is essential for multimedia
Computer Coordination With Popular Music: A New Research Agenda 1
 Computer Coordination With Popular Music: A New Research Agenda 1 Roger B. Dannenberg roger.dannenberg@cs.cmu.edu http://www.cs.cmu.edu/~rbd School of Computer Science Carnegie Mellon University Pittsburgh,
Computer Coordination With Popular Music: A New Research Agenda 1 Roger B. Dannenberg roger.dannenberg@cs.cmu.edu http://www.cs.cmu.edu/~rbd School of Computer Science Carnegie Mellon University Pittsburgh,
Music Information Retrieval with Temporal Features and Timbre
 Music Information Retrieval with Temporal Features and Timbre Angelina A. Tzacheva and Keith J. Bell University of South Carolina Upstate, Department of Informatics 800 University Way, Spartanburg, SC
Music Information Retrieval with Temporal Features and Timbre Angelina A. Tzacheva and Keith J. Bell University of South Carolina Upstate, Department of Informatics 800 University Way, Spartanburg, SC
SIGNAL + CONTEXT = BETTER CLASSIFICATION
 SIGNAL + CONTEXT = BETTER CLASSIFICATION Jean-Julien Aucouturier Grad. School of Arts and Sciences The University of Tokyo, Japan François Pachet, Pierre Roy, Anthony Beurivé SONY CSL Paris 6 rue Amyot,
SIGNAL + CONTEXT = BETTER CLASSIFICATION Jean-Julien Aucouturier Grad. School of Arts and Sciences The University of Tokyo, Japan François Pachet, Pierre Roy, Anthony Beurivé SONY CSL Paris 6 rue Amyot,
Inferring Descriptions and Similarity for Music from Community Metadata
 Inferring Descriptions and Similarity for Music from Community Metadata Brian Whitman, Steve Lawrence MIT Media Lab, Music, Mind & Machine Group, 20 Ames St., E15-491, Cambridge, MA 02139 NEC Research
Inferring Descriptions and Similarity for Music from Community Metadata Brian Whitman, Steve Lawrence MIT Media Lab, Music, Mind & Machine Group, 20 Ames St., E15-491, Cambridge, MA 02139 NEC Research
Music Similarity and Cover Song Identification: The Case of Jazz
 Music Similarity and Cover Song Identification: The Case of Jazz Simon Dixon and Peter Foster s.e.dixon@qmul.ac.uk Centre for Digital Music School of Electronic Engineering and Computer Science Queen Mary
Music Similarity and Cover Song Identification: The Case of Jazz Simon Dixon and Peter Foster s.e.dixon@qmul.ac.uk Centre for Digital Music School of Electronic Engineering and Computer Science Queen Mary
Detecting Musical Key with Supervised Learning
 Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
Detecting Musical Key with Supervised Learning Robert Mahieu Department of Electrical Engineering Stanford University rmahieu@stanford.edu Abstract This paper proposes and tests performance of two different
Neural Network for Music Instrument Identi cation
 Neural Network for Music Instrument Identi cation Zhiwen Zhang(MSE), Hanze Tu(CCRMA), Yuan Li(CCRMA) SUN ID: zhiwen, hanze, yuanli92 Abstract - In the context of music, instrument identi cation would contribute
Neural Network for Music Instrument Identi cation Zhiwen Zhang(MSE), Hanze Tu(CCRMA), Yuan Li(CCRMA) SUN ID: zhiwen, hanze, yuanli92 Abstract - In the context of music, instrument identi cation would contribute
Tempo and Beat Analysis
 Advanced Course Computer Science Music Processing Summer Term 2010 Meinard Müller, Peter Grosche Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Tempo and Beat Analysis Musical Properties:
Advanced Course Computer Science Music Processing Summer Term 2010 Meinard Müller, Peter Grosche Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Tempo and Beat Analysis Musical Properties:
CTP431- Music and Audio Computing Music Information Retrieval. Graduate School of Culture Technology KAIST Juhan Nam
 CTP431- Music and Audio Computing Music Information Retrieval Graduate School of Culture Technology KAIST Juhan Nam 1 Introduction ü Instrument: Piano ü Genre: Classical ü Composer: Chopin ü Key: E-minor
CTP431- Music and Audio Computing Music Information Retrieval Graduate School of Culture Technology KAIST Juhan Nam 1 Introduction ü Instrument: Piano ü Genre: Classical ü Composer: Chopin ü Key: E-minor
Composer Style Attribution
 Composer Style Attribution Jacqueline Speiser, Vishesh Gupta Introduction Josquin des Prez (1450 1521) is one of the most famous composers of the Renaissance. Despite his fame, there exists a significant
Composer Style Attribution Jacqueline Speiser, Vishesh Gupta Introduction Josquin des Prez (1450 1521) is one of the most famous composers of the Renaissance. Despite his fame, there exists a significant
ISMIR 2008 Session 2a Music Recommendation and Organization
 A COMPARISON OF SIGNAL-BASED MUSIC RECOMMENDATION TO GENRE LABELS, COLLABORATIVE FILTERING, MUSICOLOGICAL ANALYSIS, HUMAN RECOMMENDATION, AND RANDOM BASELINE Terence Magno Cooper Union magno.nyc@gmail.com
A COMPARISON OF SIGNAL-BASED MUSIC RECOMMENDATION TO GENRE LABELS, COLLABORATIVE FILTERING, MUSICOLOGICAL ANALYSIS, HUMAN RECOMMENDATION, AND RANDOM BASELINE Terence Magno Cooper Union magno.nyc@gmail.com
Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models
 Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models Aric Bartle (abartle@stanford.edu) December 14, 2012 1 Background The field of composer recognition has
Composer Identification of Digital Audio Modeling Content Specific Features Through Markov Models Aric Bartle (abartle@stanford.edu) December 14, 2012 1 Background The field of composer recognition has
AUTOREGRESSIVE MFCC MODELS FOR GENRE CLASSIFICATION IMPROVED BY HARMONIC-PERCUSSION SEPARATION
 AUTOREGRESSIVE MFCC MODELS FOR GENRE CLASSIFICATION IMPROVED BY HARMONIC-PERCUSSION SEPARATION Halfdan Rump, Shigeki Miyabe, Emiru Tsunoo, Nobukata Ono, Shigeki Sagama The University of Tokyo, Graduate
AUTOREGRESSIVE MFCC MODELS FOR GENRE CLASSIFICATION IMPROVED BY HARMONIC-PERCUSSION SEPARATION Halfdan Rump, Shigeki Miyabe, Emiru Tsunoo, Nobukata Ono, Shigeki Sagama The University of Tokyo, Graduate
Efficient Computer-Aided Pitch Track and Note Estimation for Scientific Applications. Matthias Mauch Chris Cannam György Fazekas
 Efficient Computer-Aided Pitch Track and Note Estimation for Scientific Applications Matthias Mauch Chris Cannam György Fazekas! 1 Matthias Mauch, Chris Cannam, George Fazekas Problem Intonation in Unaccompanied
Efficient Computer-Aided Pitch Track and Note Estimation for Scientific Applications Matthias Mauch Chris Cannam György Fazekas! 1 Matthias Mauch, Chris Cannam, George Fazekas Problem Intonation in Unaccompanied
Week 14 Music Understanding and Classification
 Week 14 Music Understanding and Classification Roger B. Dannenberg Professor of Computer Science, Music & Art Overview n Music Style Classification n What s a classifier? n Naïve Bayesian Classifiers n
Week 14 Music Understanding and Classification Roger B. Dannenberg Professor of Computer Science, Music & Art Overview n Music Style Classification n What s a classifier? n Naïve Bayesian Classifiers n
Data Driven Music Understanding
 Data Driven Music Understanding Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Engineering, Columbia University, NY USA http://labrosa.ee.columbia.edu/ 1. Motivation:
Data Driven Music Understanding Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Engineering, Columbia University, NY USA http://labrosa.ee.columbia.edu/ 1. Motivation:
A New Method for Calculating Music Similarity
 A New Method for Calculating Music Similarity Eric Battenberg and Vijay Ullal December 12, 2006 Abstract We introduce a new technique for calculating the perceived similarity of two songs based on their
A New Method for Calculating Music Similarity Eric Battenberg and Vijay Ullal December 12, 2006 Abstract We introduce a new technique for calculating the perceived similarity of two songs based on their
A Need for Universal Audio Terminologies and Improved Knowledge Transfer to the Consumer
 A Need for Universal Audio Terminologies and Improved Knowledge Transfer to the Consumer Rob Toulson Anglia Ruskin University, Cambridge Conference 8-10 September 2006 Edinburgh University Summary Three
A Need for Universal Audio Terminologies and Improved Knowledge Transfer to the Consumer Rob Toulson Anglia Ruskin University, Cambridge Conference 8-10 September 2006 Edinburgh University Summary Three
Singer Recognition and Modeling Singer Error
 Singer Recognition and Modeling Singer Error Johan Ismael Stanford University jismael@stanford.edu Nicholas McGee Stanford University ndmcgee@stanford.edu 1. Abstract We propose a system for recognizing
Singer Recognition and Modeling Singer Error Johan Ismael Stanford University jismael@stanford.edu Nicholas McGee Stanford University ndmcgee@stanford.edu 1. Abstract We propose a system for recognizing
Release Year Prediction for Songs
 Release Year Prediction for Songs [CSE 258 Assignment 2] Ruyu Tan University of California San Diego PID: A53099216 rut003@ucsd.edu Jiaying Liu University of California San Diego PID: A53107720 jil672@ucsd.edu
Release Year Prediction for Songs [CSE 258 Assignment 2] Ruyu Tan University of California San Diego PID: A53099216 rut003@ucsd.edu Jiaying Liu University of California San Diego PID: A53107720 jil672@ucsd.edu
Computational Modelling of Harmony
 Computational Modelling of Harmony Simon Dixon Centre for Digital Music, Queen Mary University of London, Mile End Rd, London E1 4NS, UK simon.dixon@elec.qmul.ac.uk http://www.elec.qmul.ac.uk/people/simond
Computational Modelling of Harmony Simon Dixon Centre for Digital Music, Queen Mary University of London, Mile End Rd, London E1 4NS, UK simon.dixon@elec.qmul.ac.uk http://www.elec.qmul.ac.uk/people/simond
However, in studies of expressive timing, the aim is to investigate production rather than perception of timing, that is, independently of the listene
 Beat Extraction from Expressive Musical Performances Simon Dixon, Werner Goebl and Emilios Cambouropoulos Austrian Research Institute for Artificial Intelligence, Schottengasse 3, A-1010 Vienna, Austria.
Beat Extraction from Expressive Musical Performances Simon Dixon, Werner Goebl and Emilios Cambouropoulos Austrian Research Institute for Artificial Intelligence, Schottengasse 3, A-1010 Vienna, Austria.
Bi-Modal Music Emotion Recognition: Novel Lyrical Features and Dataset
 Bi-Modal Music Emotion Recognition: Novel Lyrical Features and Dataset Ricardo Malheiro, Renato Panda, Paulo Gomes, Rui Paiva CISUC Centre for Informatics and Systems of the University of Coimbra {rsmal,
Bi-Modal Music Emotion Recognition: Novel Lyrical Features and Dataset Ricardo Malheiro, Renato Panda, Paulo Gomes, Rui Paiva CISUC Centre for Informatics and Systems of the University of Coimbra {rsmal,
Predicting Hit Songs with MIDI Musical Features
 Predicting Hit Songs with MIDI Musical Features Keven (Kedao) Wang Stanford University kvw@stanford.edu ABSTRACT This paper predicts hit songs based on musical features from MIDI files. The task is modeled
Predicting Hit Songs with MIDI Musical Features Keven (Kedao) Wang Stanford University kvw@stanford.edu ABSTRACT This paper predicts hit songs based on musical features from MIDI files. The task is modeled
Recommending Music for Language Learning: The Problem of Singing Voice Intelligibility
 Recommending Music for Language Learning: The Problem of Singing Voice Intelligibility Karim M. Ibrahim (M.Sc.,Nile University, Cairo, 2016) A THESIS SUBMITTED FOR THE DEGREE OF MASTER OF SCIENCE DEPARTMENT
Recommending Music for Language Learning: The Problem of Singing Voice Intelligibility Karim M. Ibrahim (M.Sc.,Nile University, Cairo, 2016) A THESIS SUBMITTED FOR THE DEGREE OF MASTER OF SCIENCE DEPARTMENT
IEEE TRANSACTIONS ON MULTIMEDIA, VOL. X, NO. X, MONTH Unifying Low-level and High-level Music Similarity Measures
 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. X, NO. X, MONTH 2010. 1 Unifying Low-level and High-level Music Similarity Measures Dmitry Bogdanov, Joan Serrà, Nicolas Wack, Perfecto Herrera, and Xavier Serra Abstract
IEEE TRANSACTIONS ON MULTIMEDIA, VOL. X, NO. X, MONTH 2010. 1 Unifying Low-level and High-level Music Similarity Measures Dmitry Bogdanov, Joan Serrà, Nicolas Wack, Perfecto Herrera, and Xavier Serra Abstract
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes
 Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
Instrument Recognition in Polyphonic Mixtures Using Spectral Envelopes hello Jay Biernat Third author University of Rochester University of Rochester Affiliation3 words jbiernat@ur.rochester.edu author3@ismir.edu
A TEXT RETRIEVAL APPROACH TO CONTENT-BASED AUDIO RETRIEVAL
 A TEXT RETRIEVAL APPROACH TO CONTENT-BASED AUDIO RETRIEVAL Matthew Riley University of Texas at Austin mriley@gmail.com Eric Heinen University of Texas at Austin eheinen@mail.utexas.edu Joydeep Ghosh University
A TEXT RETRIEVAL APPROACH TO CONTENT-BASED AUDIO RETRIEVAL Matthew Riley University of Texas at Austin mriley@gmail.com Eric Heinen University of Texas at Austin eheinen@mail.utexas.edu Joydeep Ghosh University
Hidden Markov Model based dance recognition
 Hidden Markov Model based dance recognition Dragutin Hrenek, Nenad Mikša, Robert Perica, Pavle Prentašić and Boris Trubić University of Zagreb, Faculty of Electrical Engineering and Computing Unska 3,
Hidden Markov Model based dance recognition Dragutin Hrenek, Nenad Mikša, Robert Perica, Pavle Prentašić and Boris Trubić University of Zagreb, Faculty of Electrical Engineering and Computing Unska 3,
Speech Recognition and Signal Processing for Broadcast News Transcription
 2.2.1 Speech Recognition and Signal Processing for Broadcast News Transcription Continued research and development of a broadcast news speech transcription system has been promoted. Universities and researchers
2.2.1 Speech Recognition and Signal Processing for Broadcast News Transcription Continued research and development of a broadcast news speech transcription system has been promoted. Universities and researchers
A PERPLEXITY BASED COVER SONG MATCHING SYSTEM FOR SHORT LENGTH QUERIES
 12th International Society for Music Information Retrieval Conference (ISMIR 2011) A PERPLEXITY BASED COVER SONG MATCHING SYSTEM FOR SHORT LENGTH QUERIES Erdem Unal 1 Elaine Chew 2 Panayiotis Georgiou
12th International Society for Music Information Retrieval Conference (ISMIR 2011) A PERPLEXITY BASED COVER SONG MATCHING SYSTEM FOR SHORT LENGTH QUERIES Erdem Unal 1 Elaine Chew 2 Panayiotis Georgiou
Singer Identification
 Singer Identification Bertrand SCHERRER McGill University March 15, 2007 Bertrand SCHERRER (McGill University) Singer Identification March 15, 2007 1 / 27 Outline 1 Introduction Applications Challenges
Singer Identification Bertrand SCHERRER McGill University March 15, 2007 Bertrand SCHERRER (McGill University) Singer Identification March 15, 2007 1 / 27 Outline 1 Introduction Applications Challenges
Speech and Speaker Recognition for the Command of an Industrial Robot
 Speech and Speaker Recognition for the Command of an Industrial Robot CLAUDIA MOISA*, HELGA SILAGHI*, ANDREI SILAGHI** *Dept. of Electric Drives and Automation University of Oradea University Street, nr.
Speech and Speaker Recognition for the Command of an Industrial Robot CLAUDIA MOISA*, HELGA SILAGHI*, ANDREI SILAGHI** *Dept. of Electric Drives and Automation University of Oradea University Street, nr.
Music Source Separation
 Music Source Separation Hao-Wei Tseng Electrical and Engineering System University of Michigan Ann Arbor, Michigan Email: blakesen@umich.edu Abstract In popular music, a cover version or cover song, or
Music Source Separation Hao-Wei Tseng Electrical and Engineering System University of Michigan Ann Arbor, Michigan Email: blakesen@umich.edu Abstract In popular music, a cover version or cover song, or
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng
 Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the
Melody Extraction from Generic Audio Clips Thaminda Edirisooriya, Hansohl Kim, Connie Zeng Introduction In this project we were interested in extracting the melody from generic audio files. Due to the